









目录
赛题
识别声景录音中的鸟叫声

您在本次比赛中面临的挑战是确定哪些鸟类在长录音中调用,因为培训数据是在有意义的不同环境中生成的。这正是科学家试图自动化对鸟类种群的远程监测所面临的确切问题。本次比赛以上一场比赛为基础,增加了来自新地点的声景、更多的鸟类物种、关于测试集录音的更丰富的元数据以及火车集的声景。
文件介绍
train_short_audio - 大部分训练数据包括由xenocanto.org用户慷慨上传的个别鸟类呼叫的简短录音。这些文件已缩小到 32 kHz,适用于匹配测试集音频并转换为 ogg 格式。培训数据应包含几乎所有相关文件:我们期望在 xenocanto.org 上寻找更多,是没有好处的。
train_soundscapes - 与测试集相当的音频文件。它们都大约十分钟长,以奥格格式。测试集还具有此处所示的两个录制位置的声景。
test_soundscapes - 提交笔记本时,test_soundscapes目录将填充大约 80 个用于评分的录音。这些将是大约10分钟长,在奥格音频格式。文件名称包括记录的日期,这对于识别候鸟特别有用。
此文件夹还包含包含包含录制位置名称和近似坐标的文本文件,以及带有测试集声景录制日期集的 csv。
测试.csv - 只有前三行可供下载;完整的测试.csv是在隐藏的测试集。
-
row_id:行的ID代码。 -
site:站点 ID。 -
seconds:第二个结束时间窗口 -
audio_id:音频文件的ID代码。
train_metadata.csv - 为培训数据提供了广泛的元数据。最直接相关的领域是:
-
primary_label:鸟类的代码。您可以通过将代码附加到(如美国乌鸦)来查看有关鸟类代码的详细信息。https://ebird.org/species/https://ebird.org/species/amecro -
recodist:提供录音的用户。 -
latitude&longitude:录音位置的坐标。有些鸟类可能具有当地称为"方言",因此您可能需要在培训数据中寻求地理多样性。 -
date:虽然有些鸟可以全年拨打电话,例如报警电话,但有些则仅限于特定季节。您可能需要在培训数据中寻求时间多样性。 -
filename:相关音频文件的名称。
train_soundscape_labels.csv -
-
row_id:行的ID代码。 -
site:站点 ID。 -
seconds:第二个结束时间窗口 -
audio_id:音频文件的ID代码。 -
birds:空间划定列表的任何鸟歌出现在5秒窗口。该标签表示未发生呼叫。nocall
sample_submission.csv - 一个正确形成的样品提交文件。只有前三行是公开的,其余的将作为隐藏测试集的一部分提供给您的笔记本。
-
row_id -
birds:空间划定列表的任何鸟歌出现在5秒窗口。如果没有鸟叫,使用标签。nocall
数据下载地址
赛题理解
我对赛题的理解:本次比赛是对鸟叫声的分类,共有397类,将数据集中的给定的训练集按5s窗口宽度截取音频时域波形图,傅立叶变换得到频谱图,再由神经网络识别。
在这里要注意:空间划定列表的任何鸟叫声出现在5秒窗口,所以要注意将训练集按照每5秒切分一张图像。
code
音频数据转图像
音频转图像主要用到:librosa,将图像转为224×224的一维图像
安装命令:pip install librosa或者conda install -c conda-forge librosa
import os
import warnings
warnings.filterwarnings(action='ignore')
import pandas as pd
import librosa
import numpy as np
from sklearn.utils import shuffle
from PIL import Image
from tqdm import tqdm
# Global vars
RANDOM_SEED = 1337
SAMPLE_RATE = 32000
SIGNAL_LENGTH = 5 # seconds
SPEC_SHAPE = (224, 224) # height x width
FMIN = 20
FMAX = 16000
# Code adapted from:
# https://www.kaggle.com/frlemarchand/bird-song-classification-using-an-efficientnet
# Make sure to check out the entire notebook.
# Load metadata file
train = pd.read_csv('../input/birdclef-2021/train_metadata.csv', )
# Second, assume that birds with the most training samples are also the most common
# A species needs at least 200 recordings with a rating above 4 to be considered common
birds_count = {}
for bird_species, count in zip(train.primary_label.unique(),
train.groupby('primary_label')['primary_label'].count().values):
birds_count[bird_species] = count
most_represented_birds = [key for key, value in birds_count.items()]
TRAIN = train.query('primary_label in @most_represented_birds')
LABELS = sorted(TRAIN.primary_label.unique())
# Let's see how many species and samples we have left
print('NUMBER OF SPECIES IN TRAIN DATA:', len(LABELS))
print('NUMBER OF SAMPLES IN TRAIN DATA:', len(TRAIN))
print('LABELS:', most_represented_birds)
# Shuffle the training data and limit the number of audio files to MAX_AUDIO_FILES
TRAIN = shuffle(TRAIN, random_state=RANDOM_SEED)
# Define a function that splits an audio file,
# extracts spectrograms and saves them in a working directory
def get_spectrograms(filepath, primary_label, output_dir):
# Open the file with librosa (limited to the first 15 seconds)
sig, rate = librosa.load(filepath, sr=SAMPLE_RATE, offset=None, duration=15)
# Split signal into five second chunks
sig_splits = []
for i in range(0, len(sig), int(SIGNAL_LENGTH * SAMPLE_RATE)):
split = sig[i:i + int(SIGNAL_LENGTH * SAMPLE_RATE)]
# End of signal?
if len(split) < int(SIGNAL_LENGTH * SAMPLE_RATE):
break
sig_splits.append(split)
# Extract mel spectrograms for each audio chunk
s_cnt = 0
saved_samples = []
for chunk in sig_splits:
hop_length = int(SIGNAL_LENGTH * SAMPLE_RATE / (SPEC_SHAPE[1] - 1))
mel_spec = librosa.feature.melspectrogram(y=chunk,
sr=SAMPLE_RATE,
n_fft=2048,
hop_length=hop_length,
n_mels=SPEC_SHAPE[0],
fmin=FMIN,
fmax=FMAX)
mel_spec = librosa.power_to_db(mel_spec, ref=np.max)
# Normalize
mel_spec -= mel_spec.min()
mel_spec /= mel_spec.max()
# Save as image file
save_dir = os.path.join(output_dir, primary_label)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
save_path = os.path.join(save_dir, filepath.rsplit(os.sep, 1)[-1].rsplit('.', 1)[0] +
'_' + str(s_cnt) + '.png')
im = Image.fromarray(mel_spec * 255.0).convert("L")
im.save(save_path)
saved_samples.append(save_path)
s_cnt += 1
return saved_samples
print('FINAL NUMBER OF AUDIO FILES IN TRAINING DATA:', len(TRAIN))
# Parse audio files and extract training samples
input_dir = '../input/birdclef-2021/train_short_audio/'
output_dir = '../working/melspectrogram_dataset/'
samples = []
with tqdm(total=len(TRAIN)) as pbar:
for idx, row in TRAIN.iterrows():
pbar.update(1)
if row.primary_label in most_represented_birds:
audio_file_path = os.path.join(input_dir, row.primary_label, row.filename)
samples += get_spectrograms(audio_file_path, row.primary_label, output_dir)
print(samples)
str_samples = ','.join(samples)
TRAIN_SPECS = shuffle(samples, random_state=RANDOM_SEED)
filename = open('a.txt', 'w')
filename.write(str_samples)
filename.close()
下面的图像就是转换的结果:
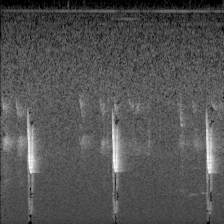
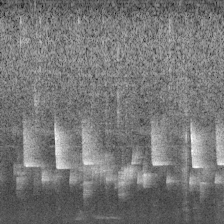
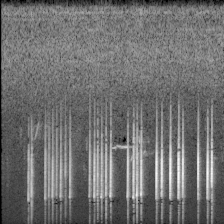

切分训练集和验证集
使用sklearn.model_selection 的 train_test_split切分数据集,按照7:3的比例切分训练集和验证集。
import os
import warnings
warnings.filterwarnings(action='ignore')
from sklearn.model_selection import train_test_split
import shutil
filename = open('a.txt', 'r')
str_samples = filename.read()
filename.close()
str_samples = str_samples.replace("\\", "/")
samples = str_samples.split(',')
trainval_files, test_files = train_test_split(samples, test_size=0.3, random_state=42)
train_dir = '../working/train/'
val_dir = '../working/val/'
def copyfiles(file, dir):
filelist = file.split('/')
filename = filelist[-1]
lable = filelist[-2]
cpfile = dir + "/" + lable
if not os.path.exists(cpfile):
os.makedirs(cpfile)
cppath = cpfile + '/' + filename
shutil.copy(file, cppath)
for file in trainval_files:
copyfiles(file, train_dir)
for file in test_files:
copyfiles(file, val_dir)
训练
模型采用EfficientNet的b3作为预训练模型,使用 datasets.ImageFolder加载数据集。差不多在20个epoch准确率能达到95%。
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
from torch.autograd import Variable
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from efficientnet_pytorch import EfficientNet
import os
import time
# 设置超参数
momentum = 0.9
BATCH_SIZE = 32
class_num = 397
EPOCHS = 500
lr = 0.001
use_gpu = True
net_name = 'efficientnet-b3'
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 数据预处理
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
dataset_train = datasets.ImageFolder('../working/train', transform)
dataset_val = datasets.ImageFolder('../working/val', transform)
# 对应文件夹的label
print(dataset_train.class_to_idx)
dset_sizes = len(dataset_train)
dset_sizes_val = len(dataset_val)
print("dset_sizes_val Length:", dset_sizes_val)
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_val, batch_size=BATCH_SIZE, shuffle=True)
def exp_lr_scheduler(optimizer, epoch, init_lr=0.001, lr_decay_epoch=10):
"""Decay learning rate by a f# model_out_path ="./model/W_epoch_{}.pth".format(epoch)
# torch.save(model_W, model_out_path) actor of 0.1 every lr_decay_epoch epochs."""
lr = init_lr * (0.8 ** (epoch // lr_decay_epoch))
print('LR is set to {}'.format(lr))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
return optimizer
def train_model(model_ft, criterion, optimizer, lr_scheduler, num_epochs=50):
train_loss = []
since = time.time()
best_model_wts = model_ft.state_dict()
best_acc = 0.0
model_ft.train(True)
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
optimizer = lr_scheduler(optimizer, epoch)
running_loss = 0.0
running_corrects = 0
count = 0
for data in train_loader:
inputs, labels = data
labels = torch.squeeze(labels.type(torch.LongTensor))
if use_gpu:
inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
outputs = model_ft(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
count += 1
if count % 30 == 0 or outputs.size()[0] < BATCH_SIZE:
print('Epoch:{}: loss:{:.3f}'.format(epoch, loss.item()))
train_loss.append(loss.item())
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dset_sizes
epoch_acc = running_corrects.double() / dset_sizes
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model_ft.state_dict()
# save best model
save_dir = 'model'
os.makedirs(save_dir, exist_ok=True)
model_ft.load_state_dict(best_model_wts)
model_out_path = save_dir + "/" + net_name + '.pth'
torch.save(model_ft, model_out_path)
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
return train_loss, best_model_wts
model_ft = EfficientNet.from_pretrained('efficientnet-b3')
num_ftrs = model_ft._fc.in_features
model_ft._fc = nn.Linear(num_ftrs, class_num)
criterion = nn.CrossEntropyLoss()
if use_gpu:
model_ft = model_ft.cuda()
criterion = criterion.cuda()
optimizer = optim.Adam((model_ft.parameters()), lr=lr)
train_loss, best_model_wts = train_model(model_ft, criterion, optimizer, exp_lr_scheduler, num_epochs=EPOCHS)
测试
将测试集按照5秒做切分,然后转为图像,这里转的图像是一维的,但是使用datasets.ImageFolder在的图像3维的,我查看了一张图像,发现着3维的数据是相同。由于输入是3维的,所以测试时的一维图像也要转为3维的,我在transform 做了操作,加入 transforms.Lambda(lambda x: x.repeat(3, 1, 1)),这样就转为3维的图像,其他的参照训练集处理逻辑更改就可以。
import os
import pandas as pd
import torch
import librosa
import numpy as np
# Global vars
RANDOM_SEED = 1337
SAMPLE_RATE = 32000
SIGNAL_LENGTH = 5 # seconds
SPEC_SHAPE = (224, 224) # height x width
FMIN = 20
FMAX = 16000
# Load metadata file
train = pd.read_csv('../input/birdclef-2021/train_metadata.csv', )
# Second, assume that birds with the most training samples are also the most common
# A species needs at least 200 recordings with a rating above 4 to be considered common
birds_count = {}
for bird_species, count in zip(train.primary_label.unique(),
train.groupby('primary_label')['primary_label'].count().values):
birds_count[bird_species] = count
most_represented_birds = [key for key, value in birds_count.items()]
TRAIN = train.query('primary_label in @most_represented_birds')
LABELS = sorted(TRAIN.primary_label.unique())
# Let's see how many species and samples we have left
print('NUMBER OF SPECIES IN TRAIN DATA:', len(LABELS))
print('NUMBER OF SAMPLES IN TRAIN DATA:', len(TRAIN))
print('LABELS:', most_represented_birds)
# First, get a list of soundscape files to process.
# We'll use the test_soundscape directory if it contains "ogg" files
# (which it only does when submitting the notebook),
# otherwise we'll use the train_soundscape folder to make predictions.
def list_files(path):
return [os.path.join(path, f) for f in os.listdir(path) if f.rsplit('.', 1)[-1] in ['ogg']]
test_audio = list_files('../input/birdclef-2021/test_soundscapes')
if len(test_audio) == 0:
test_audio = list_files('../input/birdclef-2021/train_soundscapes')
print('{} FILES IN TEST SET.'.format(len(test_audio)))
path = test_audio[0]
data = path.split(os.sep)[-1].rsplit('.', 1)[0].split('_')
print('FILEPATH:', path)
print('ID: {}, SITE: {}, DATE: {}'.format(data[0], data[1], data[2]))
# This is where we will store our results
pred = {'row_id': [], 'birds': []}
model = torch.load("./model/efficientnet-b3.pth")
model.eval()
import torchvision.transforms as transforms
from PIL import Image
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Lambda(lambda x: x.repeat(3, 1, 1)),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Analyze each soundscape recording
# Store results so that we can analyze them later
data = {'row_id': [], 'birds': []}
for path in test_audio:
path = path.replace("\\", "/")
# Open file with Librosa
# Split file into 5-second chunks
# Extract spectrogram for each chunk
# Predict on spectrogram
# Get row_id and birds and store result
# (maybe using a post-filter based on location)
# The above steps are just placeholders, we will use mock predictions.
# Our "model" will predict "nocall" for each spectrogram.
sig, rate = librosa.load(path, sr=SAMPLE_RATE)
# Split signal into 5-second chunks
# Just like we did before (well, this could actually be a seperate function)
sig_splits = []
for i in range(0, len(sig), int(SIGNAL_LENGTH * SAMPLE_RATE)):
split = sig[i:i + int(SIGNAL_LENGTH * SAMPLE_RATE)]
# End of signal?
if len(split) < int(SIGNAL_LENGTH * SAMPLE_RATE):
break
sig_splits.append(split)
# Get the spectrograms and run inference on each of them
# This should be the exact same process as we used to
# generate training samples!
seconds, scnt = 0, 0
for chunk in sig_splits:
# Keep track of the end time of each chunk
seconds += 5
# Get the spectrogram
hop_length = int(SIGNAL_LENGTH * SAMPLE_RATE / (SPEC_SHAPE[1] - 1))
mel_spec = librosa.feature.melspectrogram(y=chunk,
sr=SAMPLE_RATE,
n_fft=2048,
hop_length=hop_length,
n_mels=SPEC_SHAPE[0],
fmin=FMIN,
fmax=FMAX)
mel_spec = librosa.power_to_db(mel_spec, ref=np.max)
# Normalize to match the value range we used during training.
# That's something you should always double check!
mel_spec -= mel_spec.min()
mel_spec /= mel_spec.max()
im = Image.fromarray(mel_spec * 255.0).convert("L")
im = transform(im)
print(im.shape)
im.unsqueeze_(0)
# 没有这句话会报错
im = im.to(device)
# Predict
p = model(im)[0]
print(p.shape)
# Get highest scoring species
idx = p.argmax()
print(idx)
species = LABELS[idx]
print(species)
score = p[idx]
print(score)
# Prepare submission entry
spath = path.split('/')[-1].rsplit('_', 1)[0]
print(spath)
data['row_id'].append(path.split('/')[-1].rsplit('_', 1)[0] +
'_' + str(seconds))
# Decide if it's a "nocall" or a species by applying a threshold
if score > 0.75:
data['birds'].append(species)
scnt += 1
else:
data['birds'].append('nocall')
print('SOUNSCAPE ANALYSIS DONE. FOUND {} BIRDS.'.format(scnt))
# Make a new data frame and look at a few "results"
results = pd.DataFrame(data, columns=['row_id', 'birds'])
results.head()
# Convert our results to csv
results.to_csv("submission.csv", index=False)


















 6800
6800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











