






多token预测的实现
DeepSeek-V3实现多token预测的方式主要通过引入多token预测(Multi-Token Prediction, MTP)目标来增强模型的性能。
实现过程
- MTP模块结构:
- DeepSeek-V3使用多个顺序模块来预测多个未来token。每个模块包括:
- 共享的嵌入层(Emb)
- 共享的输出头(OutHead)
- 一个Transformer块(TRM)
- 一个投影矩阵(M)
- DeepSeek-V3使用多个顺序模块来预测多个未来token。每个模块包括:
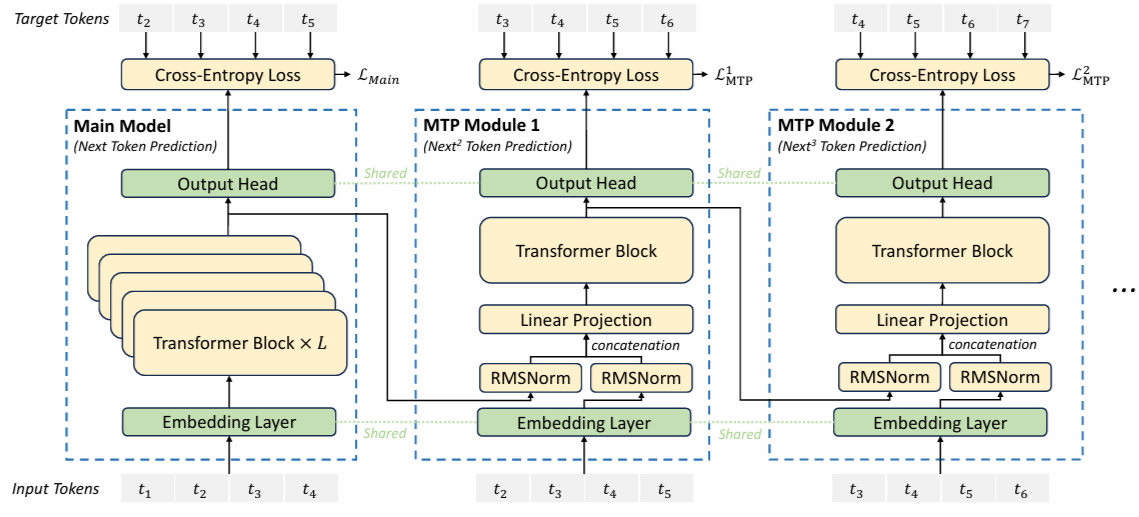
-
预测过程:
- 对于输入的第i个token,在每个预测深度k,模型将前一个深度的表示与当前token的嵌入拼接,形成新的输入表示。
- 该输入表示被送入Transformer块以生成当前深度的输出表示。
- 最后,输出头计算下一个token的概率分布。
-
训练目标:
- 对于每个预测深度,计算交叉熵损失( L M T P k L_MTP^k LMTPk),并对所有深度的损失进行平均,得到总体MTP损失(L_MTP)。
- 该损失作为DeepSeek-V3的额外训练目标,旨在提高模型的预测能力。
-
推理阶段:
- 在推理时,MTP模块可以被丢弃,主模型可以独立运行,确保模型的正常工作。
MTP的优势
- 提高数据效率:MTP目标使得训练信号更加密集,从而可能提高模型在数据利用上的效率。
- 增强预测能力:通过为未来token的预测提供更好的上下文,模型能够更好地规划其表示。
DeepSeek-V3的多token预测如何影响模型的训练效率?
DeepSeek-V3通过多token预测的设计,不仅提升了模型的训练效率,还增强了其在生成任务中的表现。这种方法的引入使得DeepSeek-V3在处理复杂的语言任务时,能够更有效地利用上下文信息,从而实现更高的预测准确性。
DeepSeek-V3的多token预测(Multi-Token Prediction, MTP)对模型的训练效率有以下几个方面的积极影响:
-
密集训练信号:
- MTP通过在每个位置上预测多个未来token,使得训练信号更加密集。这意味着模型在每个训练步骤中能够接收到更多的信息,从而加快学习速度,提高数据利用效率。
-
更好的上下文利用:
- 通过同时预测多个token,模型能够更好地利用上下文信息。这种方法使得模型在生成时能够考虑到更多的上下文,从而提高生成的连贯性和准确性,减少了训练过程中因上下文不足而导致的错误。
-
减少训练时间:
- MTP的设计使得模型在每个训练步骤中能够进行更多的预测,这可能减少了模型所需的训练步骤总数,从而缩短了整体训练时间。
-
提高模型的泛化能力:
- 通过多token预测,模型能够学习到更复杂的模式和关系,这有助于提高其在未见数据上的泛化能力。这种泛化能力的提升意味着在相同的训练时间内,模型能够达到更好的性能。
-
优化计算资源的使用:
- MTP的实现允许模型在推理时丢弃MTP模块,从而减少了计算开销。这种灵活性使得在实际应用中,模型能够在保持高效性的同时,适应不同的计算资源限制。
总的来说,DeepSeek-V3的多token预测通过提高训练信号的密度、优化上下文利用、减少训练时间、增强泛化能力以及优化计算资源的使用,显著提升了模型的训练效率。这使得DeepSeek-V3在处理复杂语言任务时,能够更快地收敛并达到更高的性能。
多token预测与传统单token预测相比,有哪些显著的区别?
多token预测(Multi-Token Prediction, MTP)与传统的单token预测(Single-Token Prediction)相比,有以下显著的区别:
-
预测范围:
- 单token预测:模型在每个时间步只预测一个token,即当前输入序列的下一个token。这种方法通常依赖于前面的上下文来生成下一个词。
- 多token预测:模型在每个时间步可以同时预测多个未来token。这种方法允许模型在生成时考虑更长的上下文,从而能够更好地捕捉序列中的复杂关系。
-
训练信号密度:
- 单token预测:每个训练步骤只提供一个目标token的训练信号,导致训练信号相对稀疏。
- 多token预测:每个训练步骤提供多个目标token的训练信号,使得训练信号更加密集,有助于模型更快地学习和收敛。
-
上下文利用:
- 单token预测:模型通常只能利用当前token及其之前的上下文来进行预测,限制了模型对上下文信息的利用。
- 多token预测:模型能够在每个预测步骤中利用更丰富的上下文信息,从而提高生成的连贯性和准确性。
-
计算复杂性:
- 单token预测:计算相对简单,因为每次只需处理一个token的预测。
- 多token预测:计算复杂性增加,因为需要同时处理多个token的预测,这可能需要更多的计算资源和内存。
-
生成能力:
- 单token预测:生成的文本可能在连贯性和上下文一致性方面存在不足,尤其是在长文本生成时。
- 多token预测:由于能够同时考虑多个token的生成,模型在生成长文本时通常表现得更加连贯和一致。
-
训练效率:
- 单token预测:训练效率相对较低,因为每个步骤只更新一个token的预测。
- 多token预测:通过密集的训练信号和更好的上下文利用,训练效率显著提高,模型能够在较短的时间内达到更好的性能。
多token预测相较于传统单token预测,提供了更丰富的上下文信息、更密集的训练信号和更高的训练效率,尽管其计算复杂性有所增加。这使得多token预测在处理复杂语言任务时,能够更好地捕捉语言的结构和语义,从而生成更高质量的文本。


















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











