







你是否想过,未来的语音助手不仅能“说话”,还能根据你的需求调整音色、语速甚至情绪?近日,一项名为Spark-TTS的突破性技术横空出世,它基于大语言模型(LLM),将文本转语音(TTS)技术推向了全新高度!今天,我们就来揭秘这项“会思考的语音合成黑科技”。
🔍 为什么说Spark-TTS是革命性的?
传统语音合成技术常面临两大难题:
1️⃣ 效率低:需多阶段处理或复杂架构预测多码本,耗时耗力。
2️⃣ 不够灵活:只能模仿参考语音,无法自由定制音色、语调等细节。
而Spark-TTS凭借两大核心创新,完美解决这些问题👇
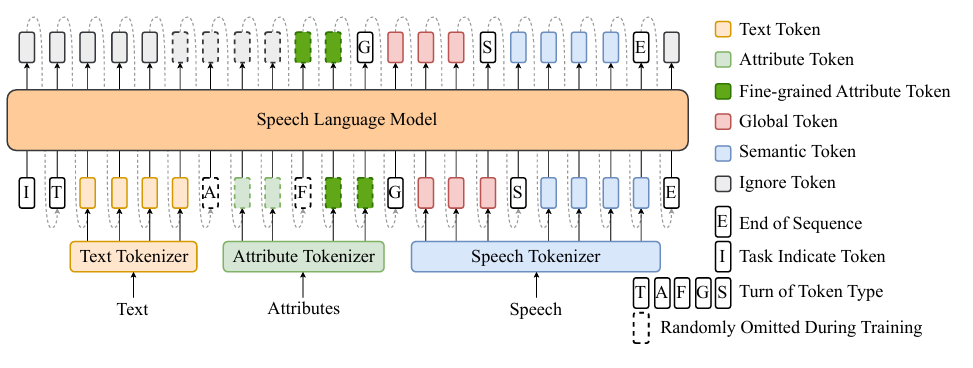
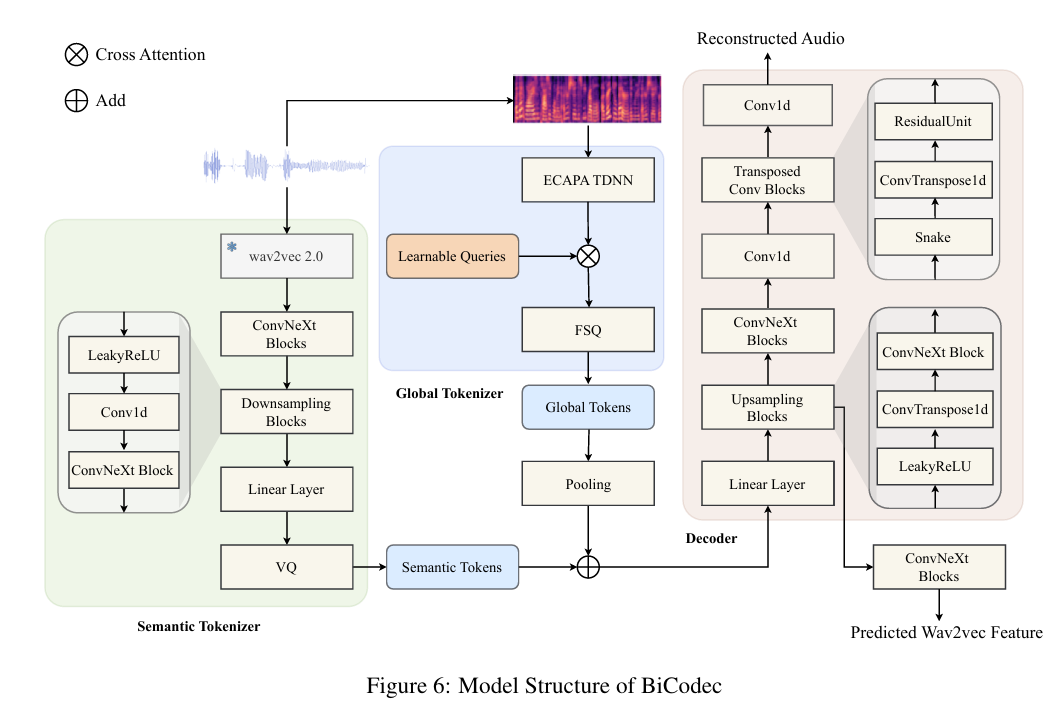
🌟 核心技术一:BiCodec——语音“分轨处理”的黑科技
想象一下,把一段语音像分轨录音一样拆解!
• 语义标记:专注“说什么”,以超低码率(50 tokens/秒)捕捉语言内容。
• 全局标记:记录“怎么说”,固定长度编码说话人音色、语调等属性。
这种单流解耦设计,让模型像“语音调色盘”般灵活组合内容和风格,既高效又精准!
🌐 核心技术二:VoxBox——语音界的“百科全书”
研究团队耗时打造100,000小时开源语音数据集VoxBox,涵盖多语言、多场景语音,并标注性别、音高、语速等精细属性,堪称语音合成的“黄金训练库”!
✅ 数据清洗严格,质量媲美专业录音
✅ 属性标注精准,支持从“温柔女声”到“激昂演讲”的多样需求
🎯 Spark-TTS能做什么?
1️⃣ 零样本语音克隆
仅凭3秒参考音频,即可模仿任意人声,相似度超越现有技术!
2️⃣ 精细化语音定制
• 粗粒度:一键选择性别、音调(5档)、语速(5档)
• 细粒度:精确到具体音高数值(如A4=440Hz)、每秒音节数调整
3️⃣ 多语言支持
中英文流畅切换,满足全球化场景需求。
🔊 试听对比(假设有链接)
[示例1:零样本克隆] | [示例2:语速控制] | [示例3:跨语言生成]
🏆 性能碾压对手!
• 重建质量:BiCodec在0.65kbps超低码率下,语音自然度超越主流编码器(如Encodec)。
• 可控性:性别控制准确率高达99.77%,音高/语速调整误差小于5%。
• 效率:仅0.5B参数量,训练数据量仅为同类模型的40%,效果却更优!
🌍 应用场景展望
• 无障碍沟通:为语言障碍者定制个性化辅助语音
• 内容创作:一键生成多语种有声书、视频配音
• 虚拟偶像:打造独一无二的“数字人”声线
• 教育娱乐:模拟名人声音讲历史、方言教学…
📢 开源共享,推动技术普惠
研究团队已全面开源代码、模型及数据集,开发者可轻松复现并二次开发!
🔗 GitHub地址:https://github.com/SparkAudio/Spark-TTS
未来已来,Spark-TTS正重新定义人机交互的边界。无论是追求极致的科技爱好者,还是寻找创新解决方案的企业,都不容错过这场语音技术的革命!点击关注,第一时间获取更多AI前沿资讯! 💡
#人工智能 #语音合成 #黑科技 #大模型 #开源项目


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











