







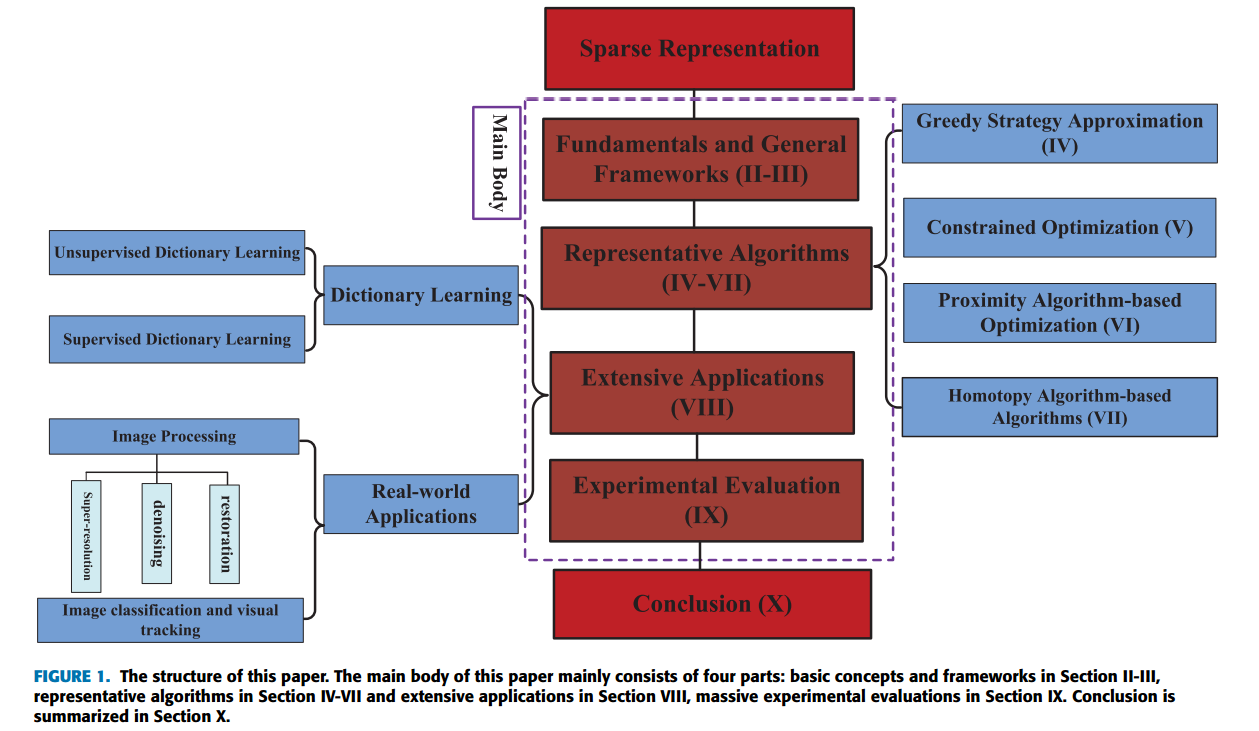
A Survey of Sparse Representation: Algorithms and Applications
ZHENG ZHANG, YONG XU, JIAN YANG, XUELONG LI, AND DAVID ZHANG
本文地址:http://blog.csdn.net/shanglianlm/article/details/46848803
I. 简介(INTRODUCTION)
II. 基础和初步概念(FUNDAMENTALS AND PRELIMINARY CONCEPTS)
两个向量
x∈Rn
和
y∈Rn
的内积(inner product)操作为:
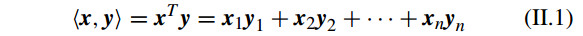
两个矩阵
X∈Rm×n
和
Y∈Rm×n
的内积(inner product)操作为:
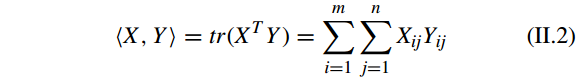
其中
tr(A)
表示矩阵 A 的迹(trace ),即它的对角元素的和。
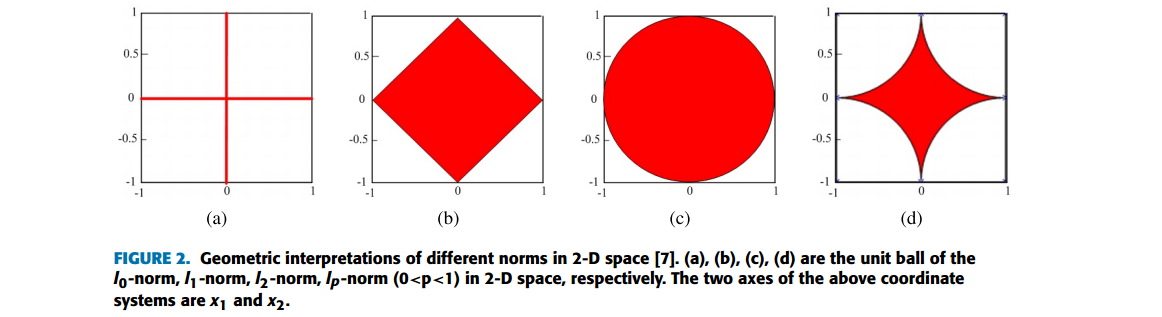
2D空间中不同范式的几何解释(Geometric interpretations)。
假设
v=[v1,v2,⋅⋅⋅,vn]
为 Euclidean 空间的
n
维向量,则
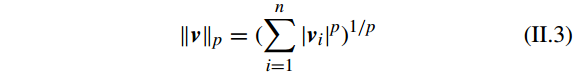
为向量
v
的
lp−norm(1≤p≤∞)
。其中
l0
-norm 表示为
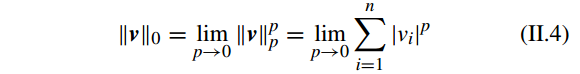
假设 f(x) 是向量 x 上的
lp
-norm
(p>0)
的函数,有
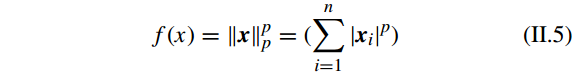
不同范式的关系总结在Fig. 3。
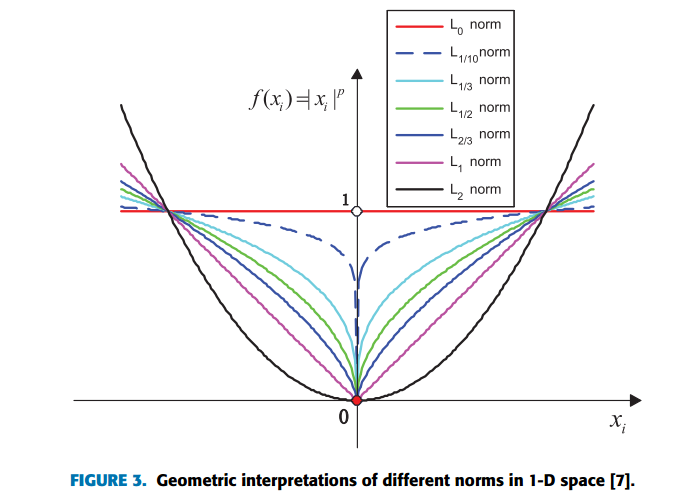
从Fig. 3有
The l0-norm function is a nonconvex, nonsmooth, discontinuity, global nondifferentiable function.
The lp-norm (0<p<1) is a nonconvex, nonsmooth, global nondifferentiable function.
The l1-norm function is a convex, nonsmooth, global nondifferentiable function.
The l2-norm function is a convex, smooth, global differentiable function.
2-D 空间中不同范式正则化的解的几何图见下图
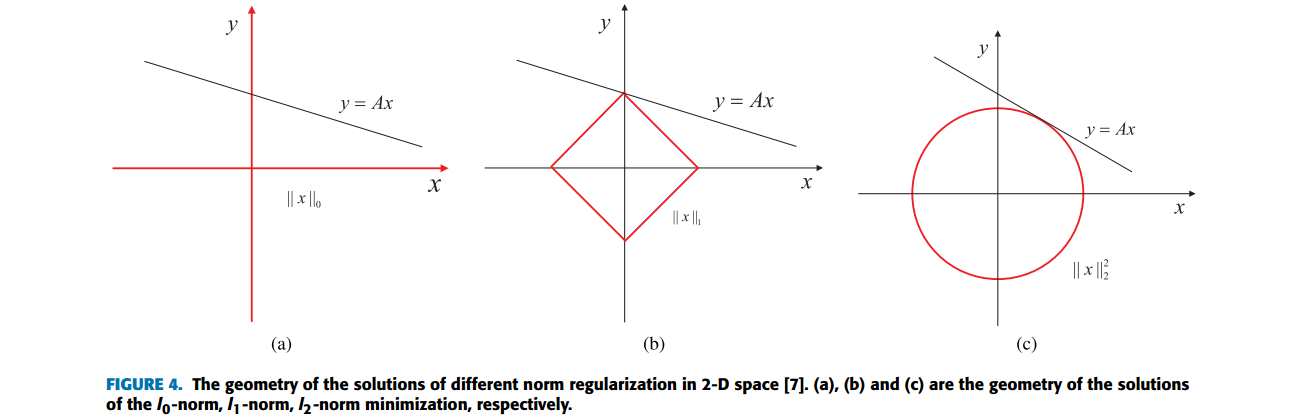
矩阵
X∈Rm×n
的 Frobenius norm,
L1
-norm 和
L2
-norm or spectral norm 分别被定义为:
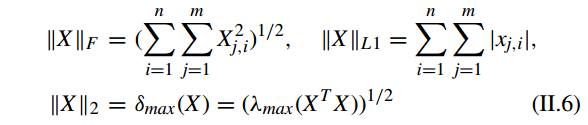
其中 δ 是奇异值操作(singular value operator)和 X 的
l2
-norm 是它的最大奇异值。
矩阵的
l2,1
-norm 或
R1
-norm 定义为:
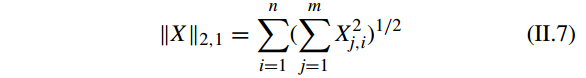
如上,一个范式(vector )可以看做是一个向量 v 的长度的度量。两个向量 x 和 y,矩阵 X 和 Y 之间距离定义为:
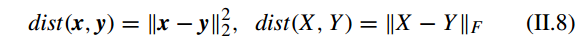
即 向量 x 和 y 之间的距离用
l2
-norm 来衡量;矩阵 X 和 Y 之间的距离用 Frobenius norm 来衡量。
III. 带有不同范式正则化的稀疏表示(SPARSE REPRESENTATION PROBLEM WITH DIFFERENT NORM REGULARIZATIONS)
分为五类:
sparse representation with the l0-norm minimization [37], [38],
sparse representation with the lp-norm (0 < p < 1) minimization [39]–[41],
sparse representation with the l1-norm minimization [42]–[45],
sparse representation with the l2,1-norm minimization [46]–[50],
sparse representation with the l2-norm minimization [9], [22], [51].
A. 带有 L0 范式最小化的稀疏表示(SPARSE REPRESENTATION WITH l0-NORM MINIMIZATION)
假设
x1,x2,⋅⋅⋅,xn∈Rd
是已知的 n 个样本,矩阵
X∈Rd×n (d<n)
,调查样本(probe sample)
y∈Rd
, 则有
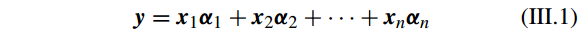
简写为
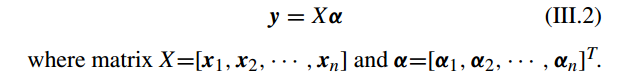
但是 问题 III.2 是一个欠定线性系统(underdetermined linear system),没有唯一解。所以要求添加一些约束,如求最稀疏的解。因此问题 III.2 可以转化为如下优化问题:
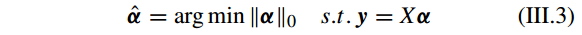
其中 ||·||_{0} 表示向量中的非零元素(nonzero elements)的个数,也可以看做是稀疏性的度量。
此外,当正好有 k(k
B. 带有 L1 范式最小化的稀疏表示(SPARSE REPRESENTATION WITH l1-NORM MINIMIZATION)
尽管 l0-norm 最小化的稀疏表示方法能获得 α 在 X 上的基础性的稀疏解,但是这个问题是non-deterministic polynomial-time hard (NP-hard) ,并且解很难接近。因此我们考虑 l1 -norm。
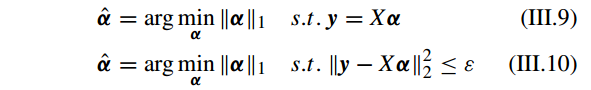
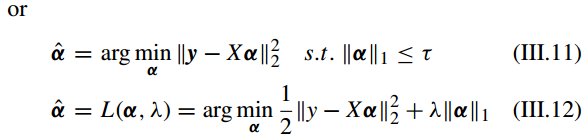
Recent literature [20], [56]–[58] has demonstrated that when the representation solution obtained by using the l1 -norm minimization constraint is also content with the condition of sparsity and the solution using l1 -norm minimization with sufficient sparsity can be equivalent to the solution obtained by l0-norm minimization with full probability.
[20] J. Wright, A. Y. Yang, A. Ganesh, S. S. Sastry, and Y. Ma, ‘‘Robust face recognition via sparse representation,’’ IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 2, pp. 210–227, Feb. 2009.
[56] D. L. Donoho, ‘‘For most large underdetermined systems of linear equations the minimal `1-norm solution is also the sparsest solution,’’Commun. Pure Appl. Math., vol. 59, no. 6, pp. 797–829, 2006.
[57] E. J. Candès, J. K. Romberg, and T. Tao, ‘‘Stable signal recovery from incomplete and inaccurate measurements,’’ Commun. Pure Appl. Math., vol. 59, no. 8, pp. 1207–1223, 2006.
[58] E. J. Candès and T. Tao, ‘‘Near-optimal signal recovery from random projections: Universal encoding strategies?’’ IEEE Trans. Inf. Theory, vol. 52, no. 12, pp. 5406–5425, Dec. 2006.
C. 带有 Lp 范式最小化的稀疏表示(SPARSE REPRESENTATION WITH lp-NORM (0 < p < 1) MINIMIZATION)
接着考虑 lp-norm ,有
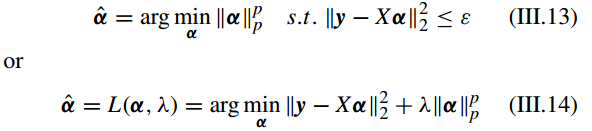
常用的有 p = 0.1, 1/2 , 1/3 , or 0.9 [59]–[61]。
[59] Q. Lyu, Z. Lin, Y. She, and C. Zhang, ‘‘A comparison of typical lp minimization algorithms,’’ Neurocomputing, vol. 119, pp. 413–424, Nov. 2013.
[60] Z. Xu, X. Chang, F. Xu, and H. Zhang, ‘‘L1/2 regularization: A thresholding representation theory and a fast solver,’’ IEEE Trans. Neural Netw. Learn. Syst., vol. 23, no. 7, pp. 1013–1027, Jul. 2012.
[61] S. Guo, Z. Wang, and Q. Ruan, ‘‘Enhancing sparsity via lp (0 < p < 1) minimization for robust face recognition,’’ Neurocomputing, vol. 99, pp. 592–602, Jan. 2013.
D. 带有 L2 范式和 L2,1 范式最小化的稀疏表示(SPARSE REPRESENTATION WITH l2-NORM AND l2,1-NORM MINIMIZATION)
l2-norm 最小化获得的稀疏表示解不是严格稀疏的,只能是有限稀疏(limitedly-sparse)的,i.e. the solution has the property that it is discriminative and distinguishable
but is not really sparse enough [31]。有
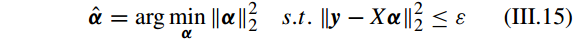
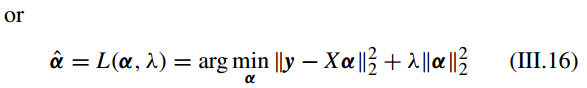
l2,1-norm 也叫做rotation invariant l1-norm,提出是主要为了处理离群点(outliers)问题[62]。
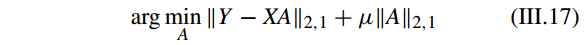
具体看 [46]–[48]。
[31] Z. Zhang, L. Wang, Q. Zhu, Z. Liu, and Y. Chen, ‘‘Noise modeling and representation based classification methods for face recognition,’’ Neurocomputing, vol. 148, pp. 420–429, Jan. 2015.
[46] F. Nie, H. Huang, X. Cai, and C. Ding, ‘‘Efficient and robust feature selection via joint l2,1-norms minimization,’’ in Proc. Adv. Neural Inf. Process. Syst., 2010, pp. 1813–1821.
[47] Y. Yang, H. T. Shen, Z. Ma, Z. Huang, and X. Zhou, ‘‘l2,1-norm regularized discriminative feature selection for unsupervised learning,’’ in Proc. 22nd Int. Joint Conf. Artif. Intell., 2011, vol. 22, no. 1, pp. 1589–1594.
[48] X. Shi, Y. Yang, Z. Guo, and Z. Lai, ‘‘Face recognition by sparse discriminant analysis via joint L2,1-norm minimization,’’ Pattern Recognit., vol. 47, no. 7, pp. 2447–2453, 2014.
IV. 贪心策略逼近(GREEDY STRATEGY APPROXIMATION)
贪心策略不直接求解优化问题,它寻求 问题 III.3 的一个近似解。
A. 匹配追踪算法(MATCHING PURSUIT ALGORITHM)
匹配追踪(MP)算法的核心思想是基于一定的相似性度量迭代地从字典中选择最好的原子(atom)来逼近获得稀疏解。
假定初始化的表示残差( initialized representation residual)
R0=y
, 字典
D=[d1,d2,⋅⋅⋅,dN]∈Rd×N
,字典 D 中的每个样本已经归一化(i.e. ||d_{i}|| = 1)。 为了接近 y ,MP 首先在 D 中选择与它最匹配的一个原子,即
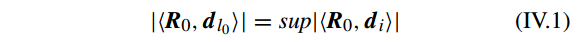
其中
l0
是 字典 D 的标签索引(第几个原子或第几列)。因此 y 可以分解为下面的等式:
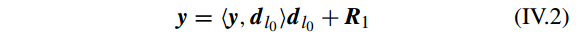
所以有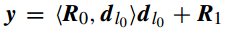
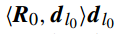
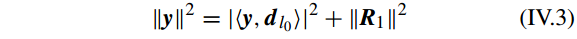
为了获得最小的表示残差(minimum representation residual),MP 迭代地从超完备字典(over-completed dictionary)中找到最匹配的原子,然后使用获得的表示残差(representation residual)最为下一次接近的目标,直到迭代终止条件满足。
对于第 t 次迭代,最好的匹配原子是
dlt
,逼近结果通过下列等式获得
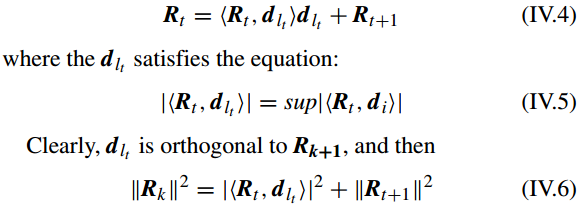
对于第 n 次迭代,表示残差(representation residual)
||Rn||2≤τ
,其中 τ 是一个很小的常数。因此调查样本(probe sample)能被表示为:
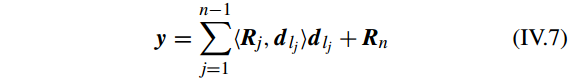
如果(representation residual)足够的小,y 可以近似表示为
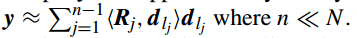
更多细节见 [63]
[63] S. G. Mallat and Z. Zhang, ‘‘Matching pursuits with time-frequency dictionaries,’’ IEEE Trans. Signal Process., vol. 41, no. 12, pp. 3397–3415, Dec. 1993.
B. 正交匹配追踪算法(ORTHOGONAL MATCHING PURSUIT ALGORITHM)
正交匹配追踪算法 orthogonal matching pursuit (OMP) 使用正交化过程来保证每次迭代中投影的正交方向。[37] 表明 OMP 能在有限时间内收敛。具体实现见下面

MP算法和OMP算法及其思想:http://blog.csdn.net/scucj/article/details/7467955
[37] J. A. Tropp and A. C. Gilbert, ‘‘Signal recovery from random measurements via orthogonal matching pursuit,’’ IEEE Trans. Inf. Theory, vol. 53, no. 12, pp. 4655–4666, Dec. 2007
V. 约束优化策略(CONSTRAINED OPTIMIZATION STRATEGY)
A. 梯度投影稀疏重建(GRADIENT PROJECTION SPARSE RECONSTRUCTION)
梯度投影稀疏重建 gradient projection sparse representation (GPSR) [73] 算法的核心思想是沿着梯度递减方向找到稀疏的解。GPSR 划分 α 的每个值为正负两部分,形成一个约束的形式。
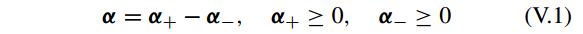
其中 操作
(⋅)+
表示正部分操作,即
(x)+=max0,x
。因此有
||α||1=1Tdα++1Tdα−
,
1d
是一个 d 维的 1 向量。
对应地 问题 III.12 可以写为一个约束二次形式
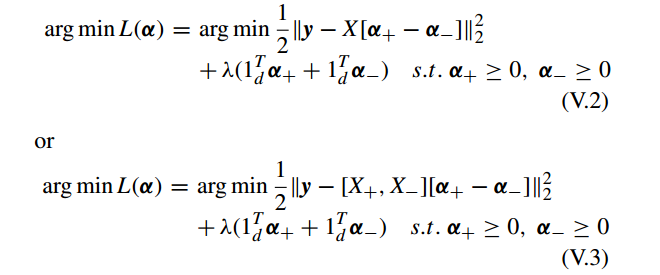
进一步, V.3 可写成
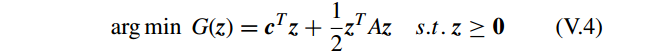
GPSR 使用 梯度下降法(gradient descent)和 标准线性搜索算法(standard line-search method)[32] 来处理问题 V.4 。z 的值可以通过迭代获得
其中梯度 
对于每个 σ, GPSR 更新它
问题 V.6 有一个闭合形式的解
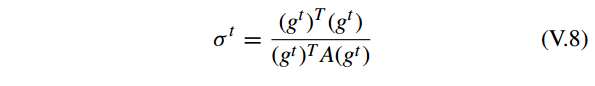
此外, GPSR 使用 backtracking linear search method [32] 确保梯度下降法每次迭代的步长为一个更合适的值。backtracking linear search method 的停止条件为
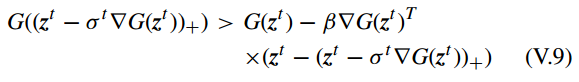
详细算法

[73] M. A. T. Figueiredo, R. D. Nowak, and S. J. Wright, ‘‘Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems,’’ IEEE J. Sel. Topics Signal Process., vol. 1, no. 4, pp. 586–597, Dec. 2007
B. 基于内点法的稀疏表示策略(INTERIOR-POINT METHOD BASED SPARSE REPRESENTATION STRATEGY)
本节主要介绍一种叫做 runcated Newton based interior-point method (TNIPM) 用来求解 large-scale l1-regularized least squares (i.e. l_{1}_l_{s} ) problem [74]。
l1_ls 的原始问题 是用来求解问题 III.12,主要步骤如下:
(1)转换原来的无约束非光滑问题(unconstrained non-smooth problem)为一个有约束光滑优化问题(constrained smooth optimization problem);
(2)使用内点法转换约束光滑优化问题为一个新的无约束光滑优化问题(unconstrained smooth optimization problem);
(3)使用截断牛顿法( truncated Newton method)求解这个无约束光滑问题。
用一个简单的例子来描述
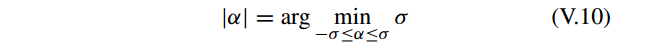
其中 σ 是一个合适的正常数。


其中 惩罚函数 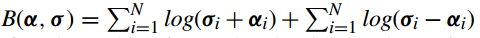
接着,l_{1}_l_{s} 使用 truncated Newton method 来求解问题 V.14。
第一步,构建Newton system,
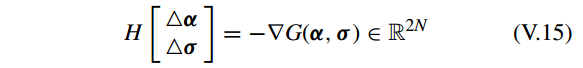
其中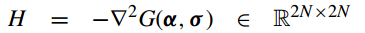
第二步,问题 III.12 的 Lagrange dual 用来构建对偶可行点(dual feasible point)和对偶间隙(duality gap)。
第三步,回溯线性搜索(backtracking linear search)用于确定 牛顿线性搜索(Newton linear search)的一个最优步长。回溯线性搜索的停止条件(stopping condition)为:
其中
ρ∈(0,0.5)
和
ηt∈(0,1)
是 牛顿线性搜索的步长。
最后,牛顿线性搜索(Newton linear search)的终止条件(termination condition)为
其中 函数
h=∇G(α,σ)
, β 是一个小的常数,g 是对偶间隙(duality gap)。


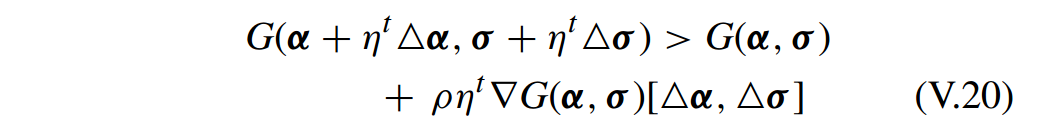
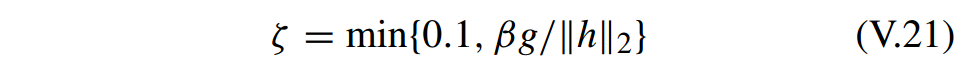
详细算法:

[74] S.-J. Kim, K. Koh, M. Lustig, S. Boyd, and D. Gorinevsky, ‘‘An interiorpoint method for large-scale `1-regularized least squares,’’ IEEE J. Sel. Topics Signal Process., vol. 1, no. 4, pp. 606–617, Dec. 2007.
C. 基于交替方向法(ADM)的稀疏表示策略(ALTERNATING DIRECTION METHOD (ADM) BASED SPARSE REPRESENTATION STRATEGY)
这一部分介绍怎样用 ADM [44] 解决 III.12 的原始(primal)和对偶(dual )问题。
首先通过引入一个辅助变量(auxiliary variable)
s∈Rd
,将问题 III.12 转换成一个约束问题:
V.22 的增广 Lagrangian 函数为
用 ADM 求解有
上面主要利用二阶泰勒展开(second order Taylor expansion)来近似求解问题 V.27 的子问题。因此算法也叫做 inexact ADM 或 approximate ADM。
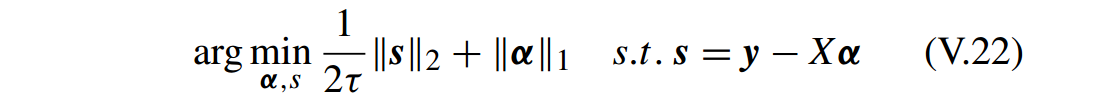
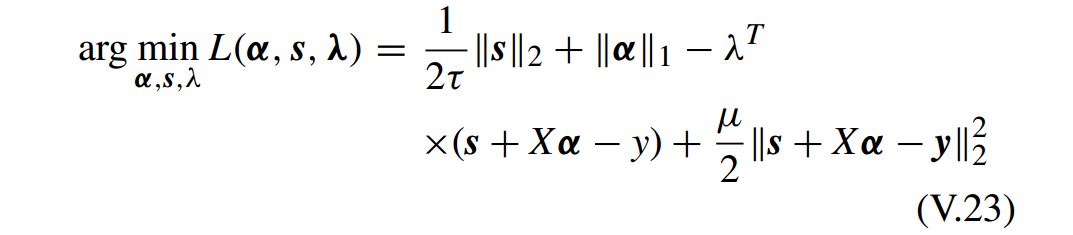
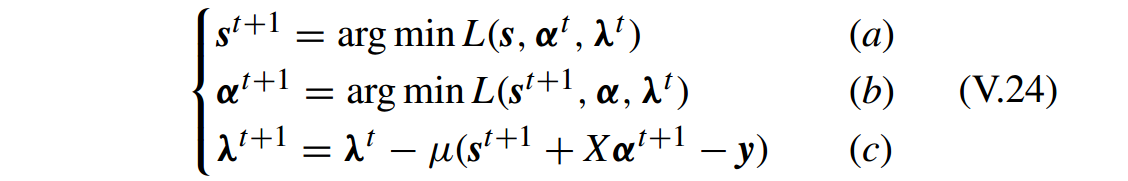



详细算法:

[44] J. Yang and Y. Zhang, ‘‘Alternating direction algorithms for L1-problems in compressive sensing,’’ SIAM J. Sci. Comput., vol. 33, no. 1, pp. 250–278, 2011.
[79] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, ‘‘Distributed optimization and statistical learning via the alternating direction method of multipliers,’’ Found. Trends Mach. Learn., vol. 3, no. 1, pp. 1–122, 2011.
主要参考文献:
[37] J. A. Tropp and A. C. Gilbert, ‘‘Signal recovery from random measurements via orthogonal matching pursuit,’’ IEEE Trans. Inf. Theory, vol. 53, no. 12, pp. 4655–4666, Dec. 2007.
[38] D. Needell and R. Vershynin, ‘‘Uniform uncertainty principle and signal recovery via regularized orthogonal matching pursuit,’’ Found. Comput. Math., vol. 9, no. 3, pp. 317–334, 2009.
[39] R. Saab, R. Chartrand, and O. Yilmaz, ‘‘Stable sparse approximations via nonconvex optimization,’’ in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., Mar./Apr. 2008, pp. 3885–3888.
[40] R. Chartrand, “Exact reconstruction of sparse signals via nonconvex minimization,’’ IEEE Signal Process. Lett., vol. 14, no. 10, pp. 707–710, Oct. 2007.
[41] Z. Xu, ‘‘Data modeling: Visual psychology approach and L1/2 regularization theory,’’ in Proc. Int. Congr. Math., 2010, pp. 3151–3184.
[42] R. Tibshirani, “Regression shrinkage and selection via the lasso,’’ J. Roy. Statist. Soc. B, vol. 58, no. 1, pp. 267–288, 1996.
[43] B. Efron, T. Hastie, I. Johnstone, and R. Tibshirani, ‘‘Least angle regression,’’ Ann. Statist., vol. 32, no. 2, pp. 407–499, 2004.
[44] J. Yang and Y. Zhang, “Alternating direction algorithms for L1-problems in compressive sensing,’’ SIAM J. Sci. Comput., vol. 33, no. 1, pp. 250–278, 2011.
[45] M. Schmidt, G. Fung, and R. Rosales, ‘‘Fast optimization methods for L1 regularization: A comparative study and two new approaches,’’ in Machine Learning. Berlin, Germany: Springer-Verlag, 2007, pp. 286–297.
[46] F. Nie, H. Huang, X. Cai, and C. Ding, ‘‘Efficient and robust feature selection via joint l2,1-norms minimization,’’ in Proc. Adv. Neural Inf. Process. Syst., 2010, pp. 1813–1821.
[47] Y. Yang, H. T. Shen, Z. Ma, Z. Huang, and X. Zhou, ‘‘l2,1-norm regularized discriminative feature selection for unsupervised learning,’’ in Proc. 22nd Int. Joint Conf. Artif. Intell., 2011, vol. 22, no. 1, pp. 1589–1594.
[48] X. Shi, Y. Yang, Z. Guo, and Z. Lai, ‘‘Face recognition by sparse discriminant analysis via joint L2,1-norm minimization,’’ Pattern Recognit., vol. 47, no. 7, pp. 2447–2453, 2014.
[49] J. Liu, S. Ji, and J. Ye, ‘‘Multi-task feature learning via efficient `2,1-norm minimization,’’ in Proc. 25th Conf. Uncertainty Artif. Intell., 2009, pp. 339–348.
[50] C. Hou, F. Nie, X. Li, D. Yi, and Y. Wu, ‘‘Joint embedding learning and sparse regression: A framework for unsupervised feature selection,’’ IEEE Trans. Cybern., vol. 44, no. 6, pp. 793–804, Jun. 2014.
[51] D. Zhang, M. Yang, and X. Feng, ‘‘Sparse representation or collaborative representation: Which helps face recognition?’’ in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Nov. 2011, pp. 471–478.
[9] Y. Xu, D. Zhang, J. Yang, and J.-Y. Yang, ‘‘A two-phase test sample sparse representation method for use with face recognition,’’ IEEE Trans. Circuits Syst. Video Technol., vol. 21, no. 9, pp. 1255–1262, Sep. 2011.
[22] I. Naseem, R. Togneri, and M. Bennamoun, ‘‘Linear regression for face recognition,’’ IEEE Trans. Pattern Anal. Mach. Intell., vol. 32, no. 11, pp. 2106–2112, Nov. 2010.
第二部分:http://blog.csdn.net/shanglianlm/article/details/46866803















 8271
8271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









