







一、线性回归的复现代码(用梯度下降法复现的):
# coding: utf-8
# In[10]:
import numpy as np
# In[11]:
def h(x,b0,b1):
y=b0+b1*x
return y
def train(x,y):
m=len(x)
a=0.001
b0=0
b1=0
temp1=0
temp2=0
for j in range(180):
temp1=0
temp2=0
for i in range(0,m):
temp1+=h(x[i],b0,b1)-y[i]
temp2+=(h(x[i],b0,b1)-y[i])*x[i]
b0=b0-(a*1/m)*temp1
b1=b1-(a*1/m)*temp2
print(temp1)
p.append(temp1)
return b0,b1
# In[12]:
def predict(x,b0,b1):
return b0+b1*x
# In[13]:
x=[1,2,3,4,5,6]
y=[2.89,6.11,8.2,12.9,16.9,18.1]
# In[14]:
p=[]
a1,a2=train(x,y)
print(p)
# In[15]:
a1
# In[16]:
a2
# In[17]:
x1=8
y1=predict(x1,a1,a2)
# In[18]:
y1
二、关于决策数的理解:
1、决策数是一个类似于流程图的树结构,分支节点表示对每一个特征进行测试,根据测试进行分类,树叶节点代表一个类别。要判断先对哪个特征进行分裂要需要用信息熵来判断。
①信息熵:一条信息的信息量和它的不确定性有直接的关系,一个问题的不确定性越大,要搞清楚这个问题,需要的信息就越多,其信息熵的计算公式为: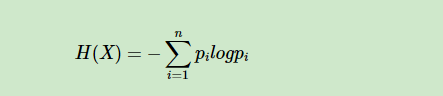
以二位底的对数 Pi表示事件x出现的概率。信息量的单位是比特(bit)
当我们要构建一个决策树时,应该遍历所有特征,分别计算,使用这个特征划分数据集前后信息熵的变化值,然后选择信息熵幅度变化最大的哪个特征,来优先作为数据集划分依据。即选择信息增益最大的特征作为分裂节点。在算信息增益的时候先算基础信息熵。
以概率p(x)为横坐标,以信息熵为纵坐标,把信息熵和概率的关系画图:

从这个函数关系可以看出,当概率p(x)越接近0或越接近1时,信息熵的值就越小,其不确定性越小,即数据越纯。
2、②:的决策数的创建:
(1)计算数据划分前的信息熵。
(2)遍历所有未作为划分条件的特征,分别计算根据每个特征划分数据集前后的信息熵。
(3)选择信息熵增益最大的特征,并使用这个特征作为数据划分节点来划分数据。
(4)递归的处理被划分后的所有子数据集,从未被选择的特征里继续选择最优数据划分特征来划分子数据集。
递归结束的条件:①:所有特征都用完了。②:划分后的信息增益足够小了,这个时候就可以停止递归划分了。针对这个条件,我们需要设置信息增益的门限值来作为结束递归的条件。
使用信息增益作为特征选择指标的决策数构建法,称为ID3算法。
3、离散化:如果一个特征是连续值,我们可以进行离散化,经过离散化处理后,我们就可以构建决策树了。要离散化成几个类别,这个往往和具体的业务有关。
4、正则项:最大化信息增益来选择特征,在决策数构建过程中,容易造成优先选择类别最多的特征进行分类。举一个极端的例子,我们把某产品的唯一标识符ID作为特征之一加入到数据集中,那么构建决策数时,就会优先选择产品ID来作为划分特征,因为这样划分出来的数据,每一个叶子节点只有一个样本,划分后的子数据集最纯净,其信息增益最大。对于这种情况我们的解决办法是:计算划分数据集的信息熵时,加上一个于类别个数成正比的正则项,来作为最后的信息熵。这样当算法选择某个类别较多的特征,使信息熵减少时,由于受到类别个数的正则项惩罚,导致最终的信息熵也比较大,这样通过合适的参数,可以使算法训练得到的某种程度得平衡。
5、基尼不纯度:也是用来衡量信息不纯度的指标。其计算公式如下:

Pk是样本属于k这个类别的概率。如果所有的样本都属于一个类别,此时Pk=1,则结果为0,即数据不纯度最低,纯度最高。我们以概率p为横坐标,以这个类别的基尼不纯度作为纵坐标,在坐标轴上画出其函数关系,如图:

从图中看出,其形状和信息熵的形状几乎一样。CART使用基尼不纯度来作为特征选择标准,CART也是一种决策树构建算法。
6、剪枝算法:
使用决策数模型拟合数据时,容易造成过拟合。解决过拟合的方法是对决策树进行剪枝处理,决策树有两种剪枝思路:前剪枝和后剪枝。
①:前剪枝:前剪枝是在构造决策数的同时进行剪枝,在决策数构建过程中,如果无法进一步降低信息熵的情况下,就会停止创建分支。为了避免过拟合,可以设定一个阈值,信息熵减少大数量小于这个阈值,即使还可以继续降低熵,也停止继续创建分支。这种方法称为前剪枝。还有一些简单的前剪枝的方法,如限制叶子节点的样本数,当样本个数小于一定的阈值时,即不再继续创建分支。
②:后剪枝:后剪枝指决策树构建完成后进行剪枝。剪枝的过程是对拥有同样父节点的一组节点进行检查,判断如果将其合并,信息熵的增加量是否小于某一阈值。如果小于阈值,则这一组节点可以合并一个节点。后剪枝的做法比较普遍,后剪枝的过程时删除一些子树,然后用子树的根节点来代替,来作为新的叶子节点。这个新叶子节点所标识的类别通过大多数原则来确定,即把这个叶子节点里样本最多的类别,作为这个叶子节点的类别。
后剪枝的算法有很多种,其中常用的一种称为降低错误率剪枝法。其思路是,自底向上,从已经构建好的完全决策树中找出一个子树,然后用子树的根节点代替这颗子树,作为新的叶子节点。叶子节点所标识的类别通过大多数原则来确定。这样就构建出一个简化版的决策数。然后使用交叉验证数据来测试简化版的决策数,看看错误率是不是降低了,如果错误率降低了,则可以使用这个简化版的决策数完全代替决策树,否则还是用原来的决策数,。通过遍历所有的子树,直到针对交叉验证数据集无法进一步降低错误率为止。
三、神经网络:
1、人工神经网络是由一系列简单的单元相互紧密联系构成的,每个单元有一定数量的实数输入和唯一的实数输出。神经网络的一个重要用途就是接受和处理传感器产生的复杂的输入并进行自适应的学习。
2、感知机模型:感知机是一种线性分类器,它用于二分类问题。它将每一个实例分类为正类(+1)和负类(-1)。感知机的物理意义为:它将输入空间(特征空间)划分为正负两类的分离超平面。
3、神经网络:
(1)神经网络中最基本的成分是神经元
(2)每一个神经元和其他神经元相连
(3)当一个神经元兴奋时,它会向相连的神经元发送化学物质。这样会改变相邻神经元的内部电位。
(4)如果某个神经元的电位超过了一个阈值,则该神经元被激活。
(5)每个神经元接收来自相邻神经元传递过来的输入信号。
(6)这些输入信号通过带权重的连接进行传递。
(7)神经元接收到的总输入值将与神经元的阈值进行比较,然后通过激活函数处理以产生神经输出。
(8)理论上激活函数为越阶函数。
4、感知机只有输出层神经元进行激活函数处理,即只有一层功能神经元。而输入层神经元并不进行激活函数处理。
5、多层前馈神经网络:
感知机只有一层功能神经元,它只能处理线性可分问题。如果向解决非线性可分问题,则可以使用多层功能神经元。如图:

(1)每层神经元与下一层神经元全部互连。
(2)同层神经元不存在互连。
(3)跨层神经元也不存在互连。
这样的神经网络结构称为"多层前馈神经网络”,其中输出层与输入层的一层神经元被称为隐层或隐含层。它的特点是:
(1)隐含层和输出层神经元都是拥有激活函数的功能神经元。
(2)输入层接收外界输入信号,不进行激活函数处理。
(3)最终结果由输出层神经元给出。
6、神经网络的学习就是根据训练数据集来调整神经元之间的连接权重,以及每个功能神经元的阈值。
7、多层前馈神经网络学习通常采用误差逆传播算法:该算法是训练多层神经网络的经典算法。
误差你传播算法:https://www.cnblogs.com/nolonely/p/7323868.html















 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









