




 本文深入探讨并查集的概念、基本操作、实现方法及实际应用案例,包括小米校招笔试题、食物链分析和抓帮派分子问题,旨在帮助读者理解和掌握并查集在不同场景下的使用。
本文深入探讨并查集的概念、基本操作、实现方法及实际应用案例,包括小米校招笔试题、食物链分析和抓帮派分子问题,旨在帮助读者理解和掌握并查集在不同场景下的使用。
并查集:也叫 合并 - 查询集合 。常用于对一组元素进行类别划分(归类,划分集合)。
一、基本概念
举例说明:
假设现在有5个学生(分别为A,B,C,D,E),每个人都有且只属于某一个班级。但是往往一开始并不清楚这5个学生分布于哪几个班级,而且也不完全知道自己与其他人是否同属一个班级,只提供一些零零碎碎的信息,比如说,A和B是一个班的,A和C是一个班的,D和E是一个班的。
并差集要解决的问题就是,通过这样一些零零碎碎的信息,来推断出这5个学生分布于几个班级,并且判断两两之间是否同属一个班级。根据上述例子,我们最后会发现ABC同属一个班级,DE同属一个班级。
那这之间,确定的过程是什么样的呢?
1. 算法思路
接着上述例子。为了方便写代码和描述,我们对这5个学生重新编号(1~5),并且首先假设分别属于1~5班。也就是,1号学生属于1班,2号同学属于2班。。。
int arr[6]; // 下标为 i 的班级为 arr[i]
for(int i = 0; i <= 5; i++)
{
arr[i] = i; //学生 i 的所属班级为 arr[i]
}那么接下来,就可以根据零零碎碎的信息重新组合了。假设总的信息如下:
① : 1 2 // 1 和 2 同学同属一个班级
② : 3 2
③ : 4 5
④ : 2 4
所以,根据信息①,我们可以得知 1号和2号 学生属于同一个班级,但是此时 arr[1] == 1 且 arr[2] == 2, 也就是说此时,1号学生是属于1班的,2号学生属于2班。那么当得知1和2属于同一个班级时,到底该怎么合并呢?此时,我们不妨设定一个规则,让右边的学生并入到左边学生所在的班级(比如第一条信息,让2号学生并入到1班)。
对于信息②,理论上2号学生应该是并入到3班,但是由于2号学生此时属于1班了,所以需要让2号并入到3班,并且把1号学生也并入到3班,也就是要让等式 (arr[1] == 3 && arr[2] == 3 && arr[3] == 3) 成立。但是每次修改,如果要将所有涉及到的学生信息都进行更新时,花费是挺大的,因为需要遍历一遍整个数组,然后找出所有班级为1的学生,再修改为3。
通常的做法是“追踪溯源”。接着信息②,首先找到2号学生的班级,如果不是初始班级(2班),那就看看他“爹”(arr[idx])属于哪个班级,并更新为他”爹 ” 所在的班级 ,这是一个递归的过程。
int getset(int idx)
{
if (idx == arr[idx] )
return idx;
arr[idx] = getset(arr[idx]); // 看看“爹”属于哪一个班级,跟着“爹”走。
return arr[idx];
}找到2号学生所在的班级之后,如果发现2号、3号学生不是一个班级的,那么就将右边学生的更新左边学生的班级。
void merge(int u,int v)
{
int us = getset(u); //首先获得两位学生u,v所在的班级
int vs = getset(v);
if( us != vs) // 如果 u 和 v 不是一个班级的
arr[vs] = us; //将右边学生的班级
}
综上所述,通常并差集包含两个基本操作:
- 查询:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
- 合并:将两个子集合并成同一个集合。
其余概念参考 维基百科 - 并查集
- 初始化
void init()
{
for_each(begin(arr),end(arr),[](int &val){
static int i = 0;
val = i++;
});
}- 查询
int getset(int idx)
{
if(arr[idx] == idx)
return idx;
else
{
arr[idx] = getset(arr[idx]);
return arr[idx];
}
} - 合并
void mergeset(int v,int u)
{
int vset = getset(v);
int uset = getset(u);
if(vset != uset )
arr[uset] = vset;
}测试代码:
#include <iostream>
#include <algorithm> // for_each
#include <iterator> // ostream_iterator
using namespace std;
#define MAX 100
int arr[MAX];
void init()
{
for_each(begin(arr), end(arr), [](int & val){
static int i = 0;
val = i++;
});
}
int getset(int idx)
{
if (arr[idx] == idx)
return idx;
else
{
arr[idx] = getset(arr[idx]);
return arr[idx];
}
}
void mergeset(int v, int u)
{
int vset = getset(v);
int uset = getset(u);
if (vset != uset)
arr[uset] = vset;
}
int main()
{
init();
int n, m; //n个人,m行数据
cin >> n >> m;
int u, v;
for (int i = 0; i < m; i++)
{
cin >> u >> v;
mergeset(u, v);
}
for (int i = 1; i <= n; i++)
{
getset(i);
cout << arr[i] << " ";
}
cout << endl;
return 0;
}测试数据:
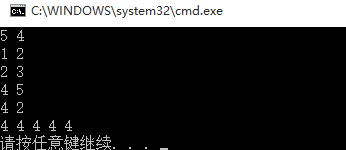
5 4
1 2
2 3
4 5
4 2
结果:
二、应用举例
1. 小米校招笔试题
问题描述
假如已知有n个人和m对好友关系(存于数字r)。如果两个人是直接或间接的好友(好友的好友的好友…),则认为他们属于同一个朋友圈,请写程序求出这n个人里一共有多少个朋友圈。
假如:n = 5 , m = 3 , r = {{1 , 2} , {2 , 3} , {4 , 5}},表示有5个人,1和2是好友,2和3是好友,4和5是好友,则1、2、3属于一个朋友圈,4、5属于另一个朋友圈,结果为2个朋友圈。
输入:
输入包含多个测试用例,每个测试用例的第一行包含两个正整数 n、m
输出:
对应每个测试用例,输出在这n个人里一共有多少个朋友圈。
样例输入:
// 5个人 3对好友关系
5 3
1 2
2 3
4 5
// 3 个人 3对好友关系
3 3
1 2
1 3
2 3
样例输出:
2
1
测试代码
#include <iostream>
#include <algorithm>
using namespace std;
int arr[100];
void init()
{
for_each(begin(arr),end(arr),[](int & val){
static int i = 0;
val = i++;
});
}
int getset(int idx)
{
if(arr[idx] == idx)
return idx;
else
{
arr[idx] = getset(arr[idx]);
return arr[idx];
}
}
void mergeset(int v,int u)
{
int vset = getset(v);
int uset = getset(u);
if(vset != uset )
arr[uset] = vset;
}
int main()
{
// 初始化并差集
init();
int n,m; // n个人,m对好友关系
while( cin >> n >> m )
{
int u,v; // 一对好友关系中的两个人的编号
for(int i = 0; i < m ; i++)
{
cin >> u >> v;
mergeset(u,v); // 对两个人的编号进行归类 , 靠左
}
int cnt = 0;
for(int i = 1; i <= n; i++)
{
// 统计朋友圈个数
if(i == arr[i])
cnt++;
}
cout << cnt << endl;
}
return 0;
}结果:

2. 食物链
问题描述
动物王国中有三类动物A,B,C,这三类动物的食物链构成了有趣的环形。A吃B, B吃C,C吃A。
现有N个动物,以1-N编号。每个动物都是A,B,C中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这N个动物所构成的食物链关系进行描述:
第一种说法是”1 X Y”,表示X和Y是同类。
第二种说法是”2 X Y”,表示X吃Y。
此人对N个动物,用上述两种说法,一句接一句地说出K句话,这K句话有的是真的,有的是假的。当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
1) 当前的话与前面的某些真的话冲突,就是假话;
2) 当前的话中X或Y比N大,就是假话;
3) 当前的话表示X吃X,就是假话。
你的任务是根据给定的N(1 <= N <= 50,000)和K句话(0 <= K <= 100,000),输出假话的总数。 原题链接
输入:
第一行是两个整数N和K,以一个空格分隔。
以下K行每行是三个正整数 D,X,Y,两数之间用一个空格隔开,其中D表示说法的种类。
若D=1,则表示X和Y是同类。
若D=2,则表示X吃Y。
输出:
只有一个整数,表示假话的数目。
样列输入:
100 7
1 101 1
2 1 2
2 2 3
2 3 3
1 1 3
2 3 1
1 5 5
样列输出:
3
测试代码
#include <iostream>
using namespace std;
struct {
int kind;
int parent;
}animal[50010];
void MakeSet(int SizeOfSet)
{
//初始化并查集,将每个结点的根结点设置为自己
//相互之间关系确定的结点才放入一个集合里
//一句话都没有输入之前所有节点之间的关系都不确定,所以各自单独一个集合
//每个结合的根节点kind都是0,有利于合并时kind值的计算
for (int i = 1; i <= SizeOfSet; i++)
{
animal[i].parent = i;
animal[i].kind = 0;
}
}
void Union(int RootOfX, int RootOfY, int NodeX, int NodeY, int D)
{
//此函数作用:1.将Y的根节点的根节点设置为X的根结点
//2.由于设置后RootOfY已经不再是根节点,所以要保证其kind相对于RootOfX的正确性
//在此函数里,D==0说明NodeX与NodeY同类,
//D==1说明NodeX吃NodeY,因此传参前要将D减一
//将Y所在树依附到X所在树上
animal[RootOfY].parent = RootOfX;
//更新RootOfY的kind,保证其kind相对于RootOfX的正确性
//原始公式为animal[NodeX].kind-(animal[NodeY].kind+amimal[RootOfY].kind)=D;
animal[RootOfY].kind = (-D + (animal[NodeX].kind - animal[NodeY].kind) + 3) % 3;
}
int Find(int NodeToFind)
{
//此函数作用:1找到NodeToFind所在集合,即找到其根节点
//2.查找的过程是一个递归过程,递归出口是遇到一个根节点为自身的结点,即当前集合的根节点
//然后递归返回的路径上依次将各个各个结点的根节点设置为此节点,并继续返回此根结点,这样就可以
//把集合中所有结点的根节点设置为同一个根结点,这叫做“路径压缩”,
//是为了使并查集稳定而做的一种改进,目的是避免并查集成为接近于链表的结构,因为并查集的优势体现在
//树的深度较浅,查找容易,此举可看作对并查集深度的控制。
//递归返回路径上,除了要做更新途径结点(按照距根从近到远的顺序)的根结点外,还要依次修正
//途径结点的kind。这是因为在Union操作中只是保证了直接和根节点相连的
//结点(即未作Union操作前的某一树的根)kind的正确性,其他节点kind的正确性就需要在这里修正
//从近到远进行修正恰好保证了每次修正都有理有据。
//每次修正都要依仗其原根节点kind的正确性,因为这是一个相对计算的关系
if (animal[NodeToFind].parent == NodeToFind)
return NodeToFind;
int temp = animal[NodeToFind].parent;
animal[NodeToFind].parent = Find(animal[NodeToFind].parent);
//更新NodeToFind结点kind的正确性,因为原来的kind是相对于0(根节点kind都为0),
//原来的根节点现在已经不是根节点了,所以只需要根据原根节点现有的kind值即可更新
animal[NodeToFind].kind = (animal[NodeToFind].kind + animal[temp].kind + 3) % 3;
return animal[NodeToFind].parent;
}
int main()
{
int n, k;
cin >> n >> k;
MakeSet(n);
int x, y, d;
int NumOfLies = 0;
while (k--)
{
//cin>>d>>x>>y; //cin导致TLE
scanf("%d%d%d", &d, &x, &y);
if (x > n || y > n)
NumOfLies++;
else if (x == y&&d == 2)
NumOfLies++;
else
{
int rootx = Find(x);
int rooty = Find(y);
if (rootx == rooty)
{
//如果两节点的根相等,说明根据以往结论,这两点的关系已经确定,可以开始判断
if (d == 1 && animal[x].kind != animal[y].kind)
NumOfLies++;
if (d == 2 && (animal[x].kind - animal[y].kind + 3) % 3 != 1)
NumOfLies++;
}
else
{
//x和y不在一个集合里,说明两者关系尚未确定,则将两者关系进行确定,
//即将两者所在集合进行合并操作Union,Union操作只保证了和根结点相连的结点kind
//的正确性,不要担心,由于并查集的特点(根节点表示法的树)所以无法从根向下找到
//子节点,因此子节点即使有错误也是安全的,到了需要访问(Find)的时候再修正也不迟
Union(rootx, rooty, x, y, d - 1); //别忘了d要减一才符合我们规定的含义
}
}
}
cout << NumOfLies << endl;
}关于食物链题目的分析可以参考: 并查集 - 食物链分析
3. 抓帮派分子
问题描述
The police office in Tadu City decides to say ends to the chaos, as launch actions to root up the TWO gangs in the city, Gang Dragon and Gang Snake. However, the police first needs to identify which gang a criminal belongs to. The present question is, given two criminals; do they belong to a same clan? You must give your judgment based on incomplete information. (Since the gangsters are always acting secretly.)
Assume N (N <= 10^5) criminals are currently in Tadu City, numbered from 1 to N. And of course, at least one of them belongs to Gang Dragon, and the same for Gang Snake. You will be given M (M <= 10^5) messages in sequence, which are in the following two kinds:
D [a] [b]
where [a] and [b] are the numbers of two criminals, and they belong to different gangs.A [a] [b]
where [a] and [b] are the numbers of two criminals. This requires you to decide whether a and b belong to a same gang.
输入:
The first line of the input contains a single integer T (1 <= T <= 20), the number of test cases. Then T cases follow. Each test case begins with a line with two integers N and M, followed by M lines each containing one message as described above.
输出:
For each message “A [a] [b]” in each case, your program should give the judgment based on the information got before. The answers might be one of “In the same gang.”, “In different gangs.” and “Not sure yet.”
样例输入:
1
5 5
A 1 2
D 1 2
A 1 2
D 2 4
A 1 4
样例输出:
Not sure yet.
In different gangs.
In the same gang
测试代码:
#include <iostream>
#include <stdio.h>
using namespace std;
struct _cri{
int parent;
int gang; //0 for the same as SetRoot,1 for different from it
}cri[100010];
void MakeSet(int SizeOfSet)
{
for (int i = 1;i <= SizeOfSet;i++)
{
cri[i].parent = i;
cri[i].gang = 0;
}
}
void Union(int RootOfX,int RootOfY,int NodeX,int NodeY,int SorD)
{
cri[RootOfY].parent = RootOfX;
cri[RootOfY].gang = cri[NodeX].gang==cri[NodeY].gang?SorD:(1-SorD);
}
int Find(int NodeToFind)
{
if(cri[NodeToFind].parent==NodeToFind)
return NodeToFind;
int temp = cri[NodeToFind].parent;
cri[NodeToFind].parent = Find(cri[NodeToFind].parent);
cri[NodeToFind].gang = cri[temp].gang==0?cri[NodeToFind].gang:(1-cri[NodeToFind].gang);
return cri[NodeToFind].parent;
}
int main()
{
int NumOfCases;
cin>>NumOfCases;
while (NumOfCases--)
{
int N,M;
char AorD;
int cri_a,cri_b;
cin>>N>>M;
MakeSet(N);
while (M--)
{
scanf("/n%c%d%d",&AorD,&cri_a,&cri_b);
int rootx =Find(cri_a);
int rooty = Find(cri_b);
if (AorD=='D')
Union(rootx,rooty,cri_a,cri_b,1);
else
{
if (rootx==rooty)
{
if (cri[cri_a].gang==cri[cri_b].gang)
cout<<"In the same gang."<<endl;
else
cout<<"In different gangs."<<endl;
}
else
cout<<"Not sure yet."<<endl;
}
}
}
}说明
其余关于并查集的题目可参考: 北京大学 acm

















 1843
1843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









