






cache 是一种快速而小的缓存设备,cache 存储了最近需要访问的 memory 数据。 这种描述是相当准确的,但是如果了解 cache 工作的细节将对改善程序的性能有很大的帮助。
在这篇博客,我将通过代码示例来说明 cache 是如何工作的和 cache是如何影响程序性能的。
例子用 C# 描述,这并不影响分析和结论。 原文地址 Gallery of Processor Cache Effects
一、内存访问和性能
如下一段代码,相比于 Loop 1,你觉得 Loop 2 运行能有多快?
int[] arr = new int[64 * 1024 * 1024];
// Loop 1
for (int i = 0; i < arr.Length; i++)
arr[i] *= 3;
// Loop 2
for (int i = 0; i < arr.Length; i += 16)
arr[i] *= 3;很显然,Loop 2 的迭代次数大概是 Loop 1 迭代次数的 6% 。但是实验结果显示,两个 for 循环花费的时间分别︰ 80 和 78 ms。
这种现象的原因是什么?两个循环的运行时间,主要在于对数组的 memory 访问,而不是整数乘法。 总之, IO 是费时的。
实际上,Loop 1 和 Loop 2 执行了相同的 memory 访问。
二、缓存行的影响
如下一段代码,我们改变 for 循环的增长步长。
for (int i = 0; i < arr.Length; i += K)
arr[i] *= 3;以下是不同步长值 (K) 时,循环的运行时间:
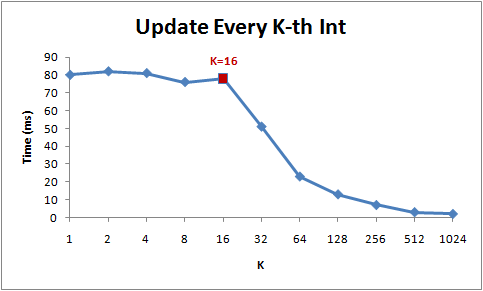
从上图可以看出,步长在1 到 16 范围内时,for 循环的运行时间几乎没有变化。但是从 16 起,每当我们增加一倍步长,运行时间减半。
出现上图现象的原因是,CPU 并不是一个字节一个字节的访问内存。相反,他们每次访存操作,都将获取一个 memory chunk(通常为 64 bytes),称为 缓存行( cache line )。所以,当你读取一个特定的内存地址时,从这个内存地址开始的整个 cache line 都将从 memory 加载到 cache 。这样的话,如果下一次要访问的数据正好在该 cache line 中的话,那么将不会产生额外的访问开销(cache 命中了,就不用去memory中获取)!
由于 16 个 int 刚好占用 64 个字节(cache line 大小),所以 for 循环在每 1~16 次迭代之间要处理的数据刚好位于同一个 cache line 中。但是一旦步长变为32,上述循环的 memory 访问次数就变成了 arr.Length / 32 , 之前是 arr.Length / 16。
理解 cache line 对于优化程序有很大的帮助。例如,数据的对齐方式将会影响一次操作中的数据是否位于不同的 cache line 中。根据上述的示例,我们可以发现,在未对齐的情况下,该操作将慢一倍。
小结: 每次读内存,都是读取一个 cache line 大小,而非单个字节。
三、L1 & L2 cache sizes
现在的计算机都有 2级或者3级 的缓存,通常被称为 L1、 L2 和 L3。如果你想要知道不同 level 缓存的大小,你可以使用 CoreInfo SysInternals工具,或者使用 GetLogicalProcessorInfo Windows API 调用。这两种方法都能获得高速缓存 cache 和 cache line 的大小。
在我的机器,CoreInfo 报告有 32 kB L1 数据缓存(data cache)、 32kb L1 指令缓存(instruction cache)和 4 MB L2 数据缓存。其中 L1 cache是每个core私有的,L2 cache是共享的︰
Logical Processor to Cache Map:
*--- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
*--- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
-*-- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
-*-- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
**-- Unified Cache 0, Level 2, 4 MB, Assoc 16, LineSize 64
--*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
--*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
---* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
---* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
--** Unified Cache 1, Level 2, 4 MB, Assoc 16, LineSize 64让我们通过实验来验证这些数字。如下一段代码,我们从下标 0 开始,然后每隔 16 个位置访问数组元素。当下标增长到最后一个值时,循环又回到了起点。通过改变数组的大小,我们会发现当数组大小超过了 cache size 时,性能开始下降。
int steps = 64 * 1024 * 1024; // Arbitrary number of steps
int lengthMod = arr.Length - 1;
for (int i = 0; i < steps; i++)
{
arr[(i * 16) & lengthMod]++; // (x & lengthMod) is equal to (x % arr.Length)
}结果如下:
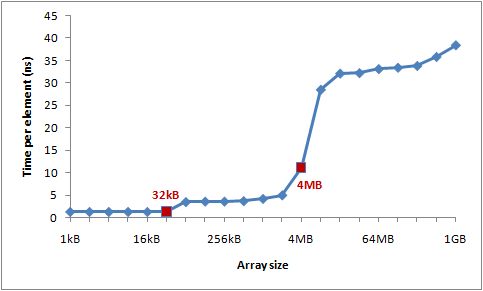
从上图可以看出,在数组大小达到 32kb 和 4MB之后,性能开始下降。 —— 32kb 对应L1 data cache的大小 , 4MB对应L2 cache的大小。
小结:L1 和 L2 的容量是有限的,当L1 被“填满时”,再有想填入L1的 cache line,就得考虑 evcit 其他已经在L1中的 cache line。
四、指令级并行
现在,让我们看看一些不同的东西。以下两个循环,你希望哪一个更快?
int steps = 256 * 1024 * 1024;
int[] a = new int[2];
// Loop 1
for (int i=0; i<steps; i++)
{
a[0]++;
a[0]++;
}
// Loop 2
for (int i=0; i<steps; i++)
{
a[0]++;
a[1]++;
}结果显示,Loop 2 比 Loop 1 快2倍,至少在我所使用的机器上是这样。为什么呢?我们来看看它的执行过程:
在Loop1中,整个执行过程如下:

在Loop2中,整个执行过程如下:

这是为什么?
随着现代处理器的发展,CPU的计算能力有了很大的改观,特别是在并行度方面。现在的单个 CPU core,它可以在同一时刻,访问两个不同内存位置的 L1 cache 或 执行两个简单的算术运算 ( 指令 )。在Loop 1中,由于访问相同的内存位置,CPU 不能利用指令级并行性,但在第二个循环中,它可以。
批注:
指令级并行,是指单个 CPU core 能同时执行多条指令。
一般而言,如果程序中相邻的一组指令是相互独立的,即不竞争同一个功能部件、不相互等待对方的运算结果、不访问同一个存储单元,那么它们就可以在处理器内部并行地执行。总之一句话就是,互不干扰 的指令才能并行执行。
指令级并行依赖的CPU技术有 流水线 、多指令发射、超标量、乱序执行 和 超长指令字。
附议: Reddit上有很多人都好奇编译器优化的问题。对于{a[0] + +; a[0] + +;},是否会优化为{[0] = 2;}。而实际上,C#编译器和CLR JIT并不会做这种优化。
五、Cache associativity
设计 cache 的关键在于 cache 与 memory 的关联性,即考虑 memory chunk 加载到 cache 时,是可以加载任何一个 cache slot 之中? 还是只可以缓存到部分 cache slot 中?
注: memory chunk 和 cache slot 大小与 cache line 一样,都是 64 bytes。(cache line 大小与CPU架构相关,目前大部分处理器都是 64 bytes)。
那么,cache slot 与 memory chunk 是该如何建立关系呢?以下是三种可行的方案:
1. Direct mapped cache
每一个 memory chunk 只能映射到一个特定的 cache slot。
一种简单的做法是,通过 chunk_index % cache_slots 求出每一个 memory chunk 对应的 cache slot。显然,这是一种“多对一”的关系。而隐含的问题是,映射到同一个 cache slot 的两个 memory chunk 是无法同时加载到同一cache中的( 你要进来,它就得出去 )。
注: 每个 memory chunk 在 cache 中只有一个候选位置。
2. N-way set associative cache
每个 memory chunk 可以映射到 N 个特定 cache slot 中的任何一个(简称N-way cache)。比如说,一个16-way cache,表示每个 memory chunk 可以映射到 16 个不同的 cache slot,so 每个 memory chunk 可以在 16 个可选cache slot 中任选其一。
注: 每个 memory chunk 在 cache 中有多个候选位置。
3. Fully associative cache
每个 memory chunk 可以映射到任何一个 cache slot 中。如此的话,cache的管理可以像 hash table 一样高效。
Direct mapped cache 方案显然很容易产生冲突 —— 当多个 value 竞争同一个 cache slot 时,将因为冲突而持续的互相 evict 对方,从而导致 cache 命中率下降。
Fully associative cache 方案是复杂的,而且开销较大。
N-way set associative caches 方案是典型的 cache 管理方案,这种方案在简单的实现和命中率之间做了折中。
本博客所涉及的实验设备是 4 MB 16-way L2 cache(即每个 memory chunk 在缓存到 L2 cache 时,那么将有 16 个可选的 cache slot 位置)。所有的 64-byte memory chunk 可划分成多个set,位于同一个 set 的 memory chunk 将会竞争 16个 候选 cache slot 。
由于 L2 cache 有 65536 slots,而 each memory set 需要 16 cache slot , 所以 memory 可以划分为 4096 sets。因此,chunk index 的低12 bit(2^12 == 4096)可以用于标定当前 memory chunk 属于哪个 memory set。但是,因此造成的后果是,以 262144 bytes(4096 * 64)为倍数差的 memory chunk 将会竞争同一个 cache slot。
为了更直观的了解 Cache associativity 的影响,需要在同样的 memory set 中重复访问超过 16 个元素。如下一段代码:
// arr 字节数组
// K 步长
public static long UpdateEveryKthByte(byte[] arr, int K)
{
Stopwatch sw = Stopwatch.StartNew();
const int rep = 1024*1024; // Number of iterations – arbitrary
int p = 0;
for (int i = 0; i < rep; i++)
{
arr[p]++;
p += K;
if (p >= arr.Length)
p = 0;
}
sw.Stop();
return sw.ElapsedMilliseconds;
}如上代码,按照步长 K,依次访问数组 arr[]。一旦到达数组尾,又从头开始。直到循环迭代 2^20 次之后。
通过传入不同大小的数组(以1MB为增量) 和 不同的步长,我们调用 UpdateEveryKthByte() 。下图是运行结果,蓝色表示运行时间长,白色表示运行时间短:
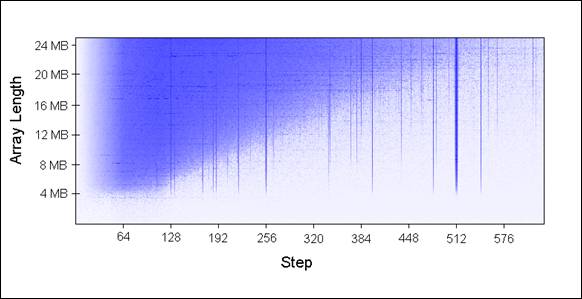
为什么会出现左边蓝色区域的情况呢?原因在于,被更新的 values ( arr[p] )被不断的从 cache 中 evict,以至于不能同时驻留在 cache 中。上图显示,最左边蓝色区域对应的运行时间接近 80 ms,而最右边的几乎白色区域对应的运行时间接近 10 ms。
原因是什么呢?
为什么会出现垂直线?
所有垂直线对应的步长,需要寻址多个内存地址。所以,所有访问的 values 无法同时全部驻留在 cache 中。
从上图可以看出,当步长值是 2 的幂(如:256、512)时,运行时间相对糟糕。例如,处理一个 8 MB 的数组,如果步长取为 512,那么,8 MB 缓存行将包含被 262144 bytes 分隔开的 32 个values。因为 262144 能被 512 整除,所以这些values,在每一次的循环都将被更新。
由于 32 > 16,那么 32 values 将一起竞争缓存中同样的 16 slots。
一些值因为不是 2 的幂,将很不幸,最终与来自同一个 set 的很多 values 竞争。这也是垂直蓝线产生的原因。
为什么垂直蓝线向下延伸到 4 MB 水平线位置?
因为,长度小于等于 4 MB 的数组,16-way cache 刚好满足前面提到的 Fully associative cache 的 cache 设计方案。
16-way cache 最多能够驻留 16 行被 262144 bytes 分隔开的 cache line。
为什么蓝色区域是一个上三角形?
在三角形区域,所有被访问的数据,并不能同时都驻留在 cache 中。则并不是因为 associativity , 而仅仅因为 L2 cache 的容量问题。
比如说,考虑一个 16 MB 的数组,步长取为 128。我们重复的更新相隔步长距离的数组元素,这也意味着,我们需要访问相邻间隔一个 chunk 单位的 memory chunk。所以,为了缓存 16 MB 数组中,这些相邻间隔一个 chunk 单位的 cache line,实际是需要 8 MB 的 cache。但是,很显然,实验所用的机器 4 MB 的 cache 是满足不了的。
所以,即使 4 MB 的 cache 采用了 fully associative 的设计方案,那它也是无法同时缓存 8 MB 数据的。
为什么蓝色三角形左边淡出?
从图中可以发现,淡出位置的区间是 0 ~ 64 bytes,刚好一个缓存行大小。正如例子一、二中解释,对于同一缓存行的访问,是几乎不会增加开销的。比如说,以 16 bytes 为步长,那么需要经过 4 次步增才会访问到下一缓存行。所以,如此产生的 4 次内存访问,实际上只访问了一次内存。
其他 64 bytes 以内的步长类似。所以,64 bytes 以内的步长,对于程序来说,运行时间会小。
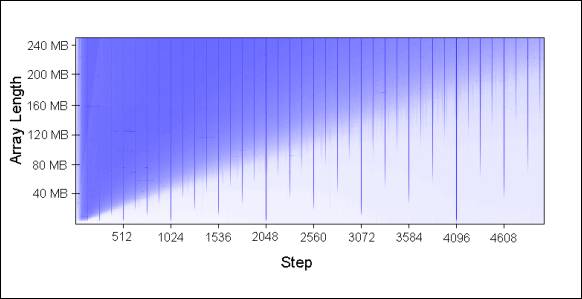
下图是该表 arr.length 和 step 之后的运行结果:
六、Cache line 假共享
在多核CPU上,cache 还会面临一个问题 —— cache 一致性。
现在大多数机器都是3级cache,其中L1 和 L2 为每个core私有的,L3是共享的。在此,为了方便说明问题,我们假设只有2级cache,其中L1私有,L2共享。
如下图,在memory中有一个 val==1 的变量,在多线程情况下,假设有2个分别运行在 core 1 和 core 2 上的线程(假设分别为 t1 和 t2),并且各自私有的 L1 cache 分别缓存了一份该变量。
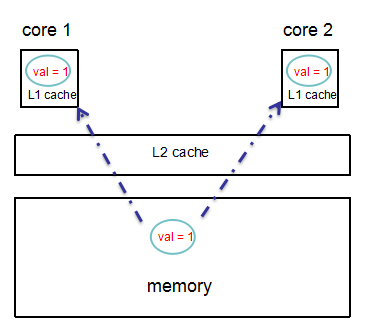
如果此时,t1线程修改 val 为 2,那么很显然,t2 和 memory 中的 val 此时都将变为无效。
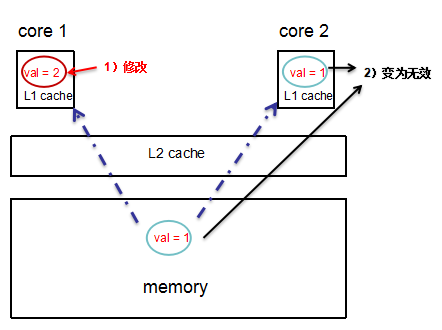
这就出现了 cache 不一致的问题。此时要做的就是,同步 memory 和 core 2 的 L1 cache 中的 val 值。(如何解决cache一致性问题不在此篇blog的讨论范围)。
我们通过下面一段代码,来看看 cache一致性 会造成多大的开销?
private static int[] s_counter = new int[1024];
private void UpdateCounter(int position)
{
for (int j = 0; j < 100000000; j++)
{
s_counter[position] = s_counter[position] + 3;
}
}在一台4-core机器上做实验,如果在4个不同的线程中分别传入参数0,1,2,3,那么4个线程全部执行完将花费4.3s。
如果传入的参数分别是 16,32,48,64,那么4个线程全部执行完只需要0.28s。
原因是什么呢?在第一个例子中,4个线程处理的数据很可能会是在同一个cache line中,那么每一次更新数组元素值的时候,就有可能会导致缓存了同样数据的 cache 出现 cache 不一致(失效)的情况。
七、硬件多样性
纵然了解了 cache 的一些特性,但是硬件之间仍然有许多差异。不同的 cpu,适应不同的优化方式。
对于某一些处理器,能够并行的访问位于不同 cache bank 中的非连续/连续cache line,和位于同一 cache bank 中的连续cache line。
如下一段代码:
private static int A, B, C, D, E, F, G;
private static void Weirdness()
{
for (int i = 0; i < 200000000; i++)
{
<something>
}
}在<something>中分别填入以下3条语句,结果如下:
<something> Time
A++; B++; C++; D++; 719 ms
A++; C++; E++; G++; 448 ms
A++; C++; 518 ms出现上述情况的原因是什么?很好奇,但是我也不清楚。如果有人能够清楚分析,我也很乐意学习。
总之,各大商家提供的硬件各有差异,硬件自有其复杂性。















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









