







目录
深度测试
深度缓冲 在每个片段中储存了信息 (通常)和颜色缓冲有着一样的宽度和高度。深度缓冲是由窗口系统自动创建的,它会以16、24或32位float的形式储存它的深度值。在大部分的系统中,深度缓冲的精度都是24位的。
当深度测试(Depth Testing)被启用的时候,OpenGL会将一个片段的深度值与深度缓冲的内容进行对比。OpenGL会执行一个深度测试,如果这个测试通过了的话,深度缓冲将会更新为新的深度值。如果深度测试失败了,片段将会被丢弃。
深度缓冲是在片段着色器运行之后(以及模板测试(Stencil Testing)运行之后,我们将在下一节中讨论)在屏幕空间中运行的。屏幕空间坐标与通过OpenGL的glViewport所定义的视口密切相关,并且可以直接使用GLSL内建变量gl_FragCoord从片段着色器中直接访问。gl_FragCoord的x和y分量代表了片段的屏幕空间坐标(其中(0, 0)位于左下角)。gl_FragCoord中也包含了一个z分量,它包含了片段真正的深度值。z值就是需要与深度缓冲内容所对比的那个值。
现在大部分的GPU都提供一个叫做提前深度测试(Early Depth Testing)的硬件特性。提前深度测试允许深度测试在片段着色器之前运行。只要我们清楚一个片段永远不会是可见的(它在其他物体之后),我们就能提前丢弃这个片段。
片段着色器通常开销都是很大的,所以我们应该尽可能避免运行它们。当使用提前深度测试时,片段着色器的一个限制是你不能写入片段的深度值。如果一个片段着色器对它的深度值进行了写入,提前深度测试是不可能的。OpenGL不能提前知道深度值。
深度测试默认是禁用的,所以如果要启用深度测试的话,我们需要用GL_DEPTH_TEST选项来启用它:
glEnable(GL_DEPTH_TEST);
当它启用的时候,如果一个片段通过了深度测试的话,OpenGL会在深度缓冲中储存该片段的z值;如果没有通过深度缓冲,则会丢弃该片段。如果你启用了深度缓冲,你还应该在每个渲染迭代之前使用GL_DEPTH_BUFFER_BIT来清除深度缓冲,否则你会仍在使用上一次渲染迭代中的写入的深度值:
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
可以想象,在某些情况下你会需要对所有片段都执行深度测试并丢弃相应的片段,但不希望更新深度缓冲。基本上来说,你在使用一个只读的(Read-only)深度缓冲。OpenGL允许我们禁用深度缓冲的写入,只需要设置它的深度掩码(Depth Mask)设置为GL_FALSE就可以了:
glDepthMask(GL_FALSE);
注意这只在深度测试被启用的时候才有效果。
深度测试函数
OpenGL允许我们修改深度测试中使用的比较运算符。这允许我们来控制OpenGL什么时候该通过或丢弃一个片段,什么时候去更新深度缓冲。我们可以调用glDepthFunc函数来设置比较运算符(或者说深度函数(Depth Function)):
glDepthFunc(GL_LESS);
表……
深度值精度
深度缓冲包含了一个介于0.0和1.0之间的深度值
所以观察空间中的平截头体中的 z 需要变到 0 到 1
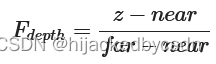
这是一个线性变换,但是我们在近处和远处需要的数据精度是不一样的,近处可以精密一些,远处可以粗糙一些,所以我们要用 1/z
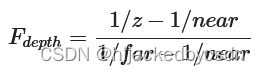
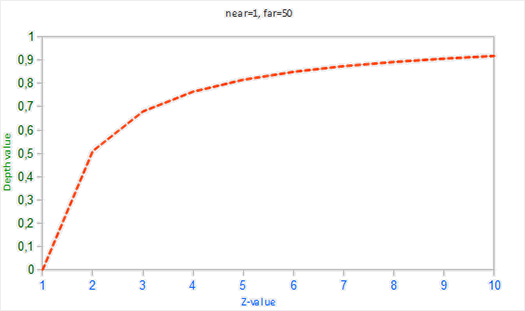
可以看到,深度值很大一部分是由很小的z值所决定的,这给了近处的物体很大的深度精度。这个(从观察者的视角)变换z值的方程是嵌入在投影矩阵中的,所以当我们想将一个顶点坐标从观察空间至裁剪空间的时候这个非线性方程就被应用了。如果你想深度了解投影矩阵究竟做了什么,我建议阅读这篇文章。https://www.songho.ca/opengl/gl_projectionmatrix.html
其实我是没懂
我之前是算过
投影矩阵的推导过程:

投影矩阵写法:
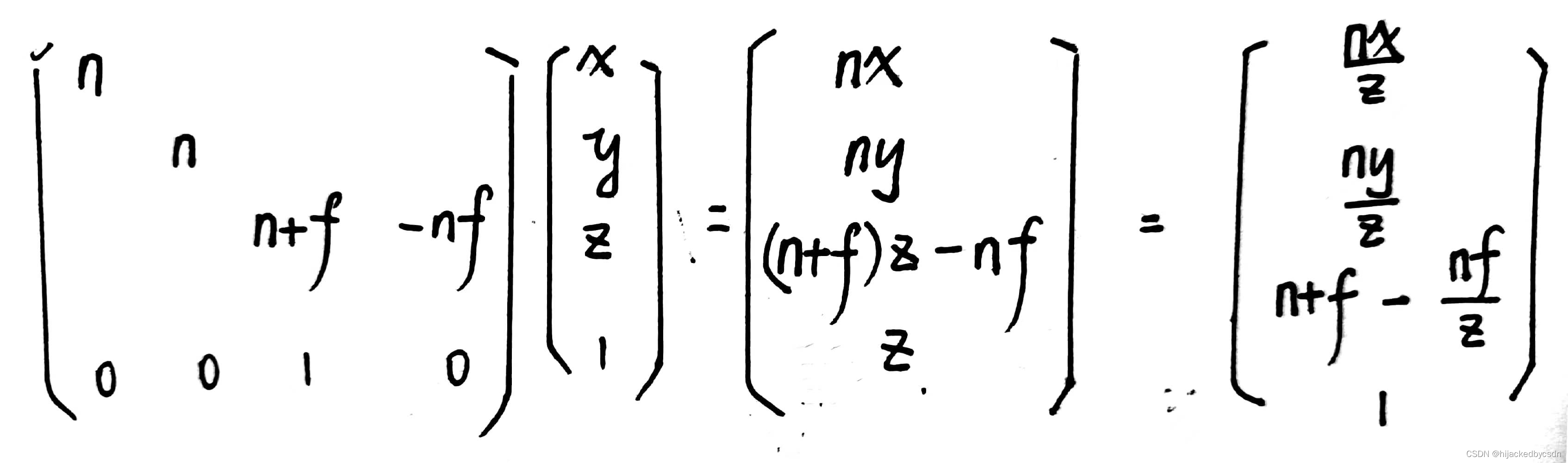
我觉得它的意思应该是,本来单独只考虑 z 的话,那么就是 depth = (1/z - 1/n)/(1/f-1/n)
但是现在我们正经推导了投影矩阵之后,正交投影就是简单的缩放,而透视投影的投影矩阵得到的结果里面自然包含了 1/z,也就自然包含了我们想要的效果
如果我们想要可视化深度缓冲的话,非线性方程的效果很快就会变得很清楚。
深度冲突
一个很常见的视觉错误会在两个平面或者三角形非常紧密地平行排列在一起时会发生,深度缓冲没有足够的精度来决定两个形状哪个在前面。结果就是这两个形状不断地在切换前后顺序,这会导致很奇怪的花纹。这个现象叫做深度冲突(Z-fighting),因为它看起来像是这两个形状在争夺(Fight)谁该处于顶端。
在我们一直使用的场景中,有几个地方的深度冲突还是非常明显的。箱子被放置在地板的同一高度上,这也就意味着箱子的底面和地板是共面的(Coplanar)。这两个面的深度值都是一样的,所以深度测试没有办法决定应该显示哪一个。
如果你将摄像机移动到其中一个箱子的内部,你就能清楚地看到这个效果的,箱子的底部不断地在箱子底面与地板之间切换,形成一个锯齿的花纹:

深度冲突是深度缓冲的一个常见问题,当物体在远处时效果会更明显(因为深度缓冲在z值比较大的时候有着更小的精度)。深度冲突不能够被完全避免,但一般会有一些技巧有助于在你的场景中减轻或者完全避免深度冲突、
防止深度冲突
第一个也是最重要的技巧是永远不要把多个物体摆得太靠近,以至于它们的一些三角形会重叠。通过在两个物体之间设置一个用户无法注意到的偏移值,你可以完全避免这两个物体之间的深度冲突。在箱子和地板的例子中,我们可以将箱子沿着正y轴稍微移动一点。箱子位置的这点微小改变将不太可能被注意到,但它能够完全减少深度冲突的发生。然而,这需要对每个物体都手动调整,并且需要进行彻底的测试来保证场景中没有物体会产生深度冲突。
第二个技巧是尽可能将近平面设置远一些。在前面我们提到了精度在靠近近平面时是非常高的,所以如果我们将近平面远离观察者,我们将会对整个平截头体有着更大的精度。然而,将近平面设置太远将会导致近处的物体被裁剪掉,所以这通常需要实验和微调来决定最适合你的场景的近平面距离。
另外一个很好的技巧是牺牲一些性能,使用更高精度的深度缓冲。大部分深度缓冲的精度都是24位的,但现在大部分的显卡都支持32位的深度缓冲,这将会极大地提高精度。所以,牺牲掉一些性能,你就能获得更高精度的深度测试,减少深度冲突。
我们上面讨论的三个技术是最普遍也是很容易实现的抗深度冲突技术了。还有一些更复杂的技术,但它们依然不能完全消除深度冲突。深度冲突是一个常见的问题,但如果你组合使用了上面列举出来的技术,你可能不会再需要处理深度冲突了。
模板测试
模板函数
略,这些细节不如看原文
物体轮廓
为物体创建轮廓的步骤如下:
-
在绘制(需要添加轮廓的)物体之前,将模板函数设置为GL_ALWAYS,每当物体的片段被渲染时,将模板缓冲更新为1。
-
渲染物体。
-
禁用模板写入以及深度测试。
-
将每个物体缩放一点点。
-
使用一个不同的片段着色器,输出一个单独的(边框)颜色。
-
再次绘制物体,但只在它们片段的模板值不等于1时才绘制。
-
再次启用模板写入和深度测试。
除了物体轮廓之外,模板测试还有很多用途,比如在一个后视镜中绘制纹理,让它能够绘制到镜子形状中,或者使用一个叫做阴影体积(Shadow Volume)的模板缓冲技术渲染实时阴影。
混合
为了取到透明度,gl 加载纹理的时候注意要选择 GL_RGBA
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, data);
丢弃片元
透明度低于某一值时可以丢弃片元
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
uniform sampler2D texture1;
void main()
{
vec4 texColor = texture(texture1, TexCoords);
if(texColor.a < 0.1)
discard;
FragColor = texColor;
}
注意,当采样纹理的边缘的时候,OpenGL会对边缘的值和纹理下一个重复的值进行插值(因为我们将它的环绕方式设置为了GL_REPEAT。这通常是没问题的,但是由于我们使用了透明值,纹理图像的顶部将会与底部边缘的纯色值进行插值。这样的结果是一个半透明的有色边框,你可能会看见它环绕着你的纹理四边形。要想避免这个,每当你alpha纹理的时候,请将纹理的环绕方式设置为GL_CLAMP_TO_EDGE:
glTexParameteri( GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri( GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
混合
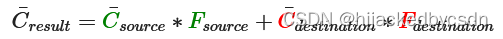
C¯source:源颜色向量。这是源自纹理的颜色向量。
C¯destination:目标颜色向量。这是当前储存在颜色缓冲中的颜色向量。
Fsource:源因子值。指定了alpha值对源颜色的影响。
Fdestination:目标因子值。指定了alpha值对目标颜色的影响。
glBlendFunc(GLenum sfactor, GLenum dfactor) 函数接受两个参数,来设置源和目标因子。OpenGL为我们定义了很多个选项,我们将在下面列出大部分最常用的选项。注意常数颜色向量C¯constant可以通过 glBlendColor 函数来另外设置。
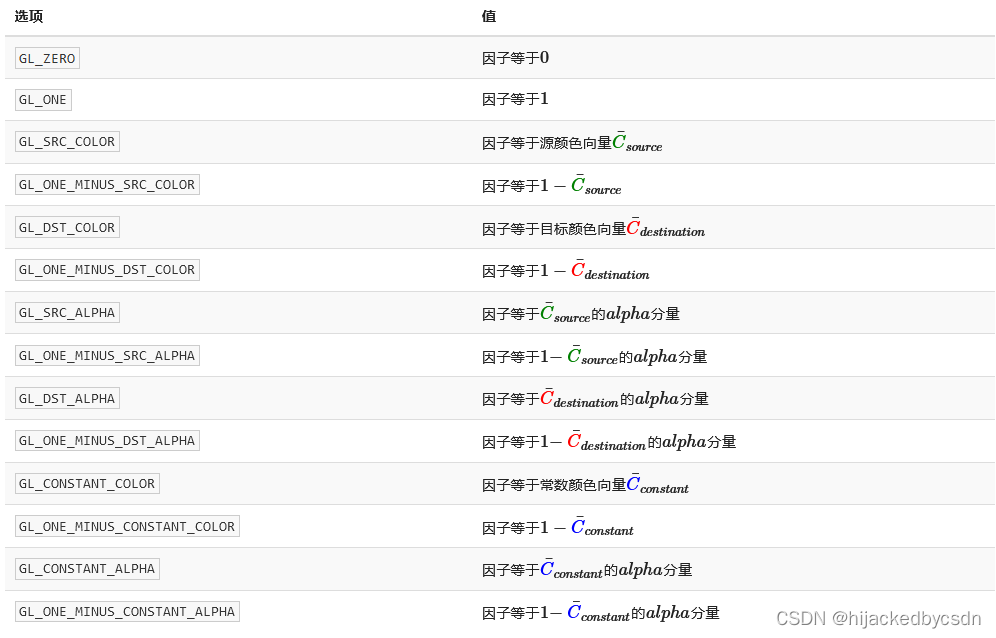
为了获得之前两个方形的混合结果,我们需要使用源颜色向量的alpha作为源因子,使用1−alpha
作为目标因子。这将会产生以下的glBlendFunc:
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
也可以使用glBlendFuncSeparate为RGB和alpha通道分别设置不同的选项:
glBlendFuncSeparate(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA, GL_ONE, GL_ZERO);
这个函数和我们之前设置的那样设置了RGB分量,但这样只能让最终的alpha分量被源颜色向量的alpha值所影响到。
OpenGL甚至给了我们更多的灵活性,允许我们改变方程中源和目标部分的运算符。当前源和目标是相加的,但如果愿意的话,我们也可以让它们相减。glBlendEquation(GLenum mode)允许我们设置运算符,它提供了三个选项:
-
GL_FUNC_ADD:默认选项,将两个分量相加:C¯result=Src+Dst。
-
GL_FUNC_SUBTRACT:将两个分量相减: C¯result=Src−Dst。
-
GL_FUNC_REVERSE_SUBTRACT:将两个分量相减,但顺序相反:C¯result=Dst−Src。
通常我们都可以省略调用glBlendEquation,因为GL_FUNC_ADD对大部分的操作来说都是我们希望的混合方程,但如果你真的想打破主流,其它的方程也可能符合你的要求。
混合与深度测试的问题
最前面窗户的透明部分遮蔽了背后的窗户?这为什么会发生呢?
发生这一现象的原因是,深度测试和混合一起使用的话会产生一些麻烦。当写入深度缓冲时,深度缓冲不会检查片段是否是透明的,所以透明的部分会和其它值一样写入到深度缓冲中。结果就是窗户的整个四边形不论透明度都会进行深度测试。即使透明的部分应该显示背后的窗户,深度测试仍然丢弃了它们。
所以我们不能随意地决定如何渲染窗户,让深度缓冲解决所有的问题了。这也是混合变得有些麻烦的部分。要想保证窗户中能够显示它们背后的窗户,我们需要首先绘制背后的这部分窗户。这也就是说在绘制的时候,我们必须先手动将窗户按照最远到最近来排序,再按照顺序渲染。
注意,对于草这种全透明的物体,我们可以选择丢弃透明的片段而不是混合它们,这样就解决了这些头疼的问题(没有深度问题)。
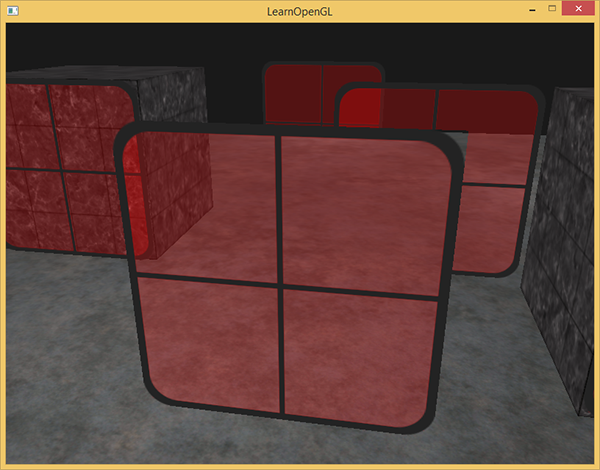
这里能看到地板是因为地板先渲染了,所以先进了深度缓冲
而后面的窗户在前面的窗户之后后渲染,所以没有通过深度测试
排序
要想让混合在多个物体上工作,我们需要最先绘制最远的物体,最后绘制最近的物体。普通不需要混合的物体仍然可以使用深度缓冲正常绘制,所以它们不需要排序。但我们仍要保证它们在绘制(排序的)透明物体之前已经绘制完毕了。当绘制一个有不透明和透明物体的场景的时候,大体的原则如下:
-
先绘制所有不透明的物体。
-
对所有透明的物体排序。
-
按顺序绘制所有透明的物体。
排序透明物体的一种方法是,从观察者视角获取物体的距离。这可以通过计算摄像机位置向量和物体的位置向量之间的距离所获得。接下来我们把距离和它对应的位置向量存储到一个STL库的map数据结构中。map会自动根据键值(Key)对它的值排序,所以只要我们添加了所有的位置,并以它的距离作为键,它们就会自动根据距离值排序了。
std::map<float, glm::vec3> sorted;
for (unsigned int i = 0; i < windows.size(); i++)
{
float distance = glm::length(camera.Position - windows[i]);
sorted[distance] = windows[i];
}
结果就是一个排序后的容器对象,它根据distance键值从低到高储存了每个窗户的位置。
之后,这次在渲染的时候,我们将以逆序(从远到近)从map中获取值,之后以正确的顺序绘制对应的窗户:
for(std::map<float,glm::vec3>::reverse_iterator it = sorted.rbegin(); it != sorted.rend(); ++it)
{
model = glm::mat4();
model = glm::translate(model, it->second);
shader.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 6);
}
我们使用了map的一个反向迭代器(Reverse Iterator),反向遍历其中的条目,并将每个窗户四边形位移到对应的窗户位置上。这是排序透明物体的一个比较简单的实现,它能够修复之前的问题,现在场景看起来是这样的:
你可以在这里找到带有排序的完整源代码。
虽然按照距离排序物体这种方法对我们这个场景能够正常工作,但它并没有考虑旋转、缩放或者其它的变换,奇怪形状的物体需要一个不同的计量,而不是仅仅一个位置向量。
在场景中排序物体是一个很困难的技术,很大程度上由你场景的类型所决定,更别说它额外需要消耗的处理能力了。完整渲染一个包含不透明和透明物体的场景并不是那么容易。更高级的技术还有次序无关透明度(Order Independent Transparency, OIT),但这超出本教程的范围了。现在,你还是必须要普通地混合你的物体,但如果你很小心,并且知道目前方法的限制的话,你仍然能够获得一个比较不错的混合实现。
面剔除
去掉那些背面
定义一个三角形顶点的环绕顺序用右手看还是左手看
默认情况下,逆时针顶点所定义的三角形将会被处理为正向三角形。也就是用右手
要想启用面剔除,我们只需要启用OpenGL的GL_CULL_FACE选项:
glEnable(GL_CULL_FACE);
从这一句代码之后,所有背向面都将被丢弃(尝试飞进立方体内部,看看所有的内面是不是都被丢弃了)。目前我们在渲染片段的时候能够节省50%以上的性能,但注意这只对像立方体这样的封闭形状有效。当我们想要绘制上一节中的草时,我们必须要再次禁用面剔除,因为它们的正向面和背向面都应该是可见的。
OpenGL允许我们改变需要剔除的面的类型。如果我们只想剔除正向面而不是背向面会怎么样?我们可以调用glCullFace来定义这一行为:
glCullFace(GL_FRONT);
glCullFace函数有三个可用的选项:
-
GL_BACK:只剔除背向面。
-
GL_FRONT:只剔除正向面。
-
GL_FRONT_AND_BACK:剔除正向面和背向面。
glCullFace的初始值是GL_BACK。除了需要剔除的面之外,我们也可以通过调用glFrontFace,告诉OpenGL我们希望将顺时针的面(而不是逆时针的面)定义为正向面:
glFrontFace(GL_CCW);
默认值是GL_CCW,它代表的是逆时针的环绕顺序,另一个选项是GL_CW,它(显然)代表的是顺时针顺序。
这个只是根据三角形定点顺序
帧缓冲
用于写入颜色值的颜色缓冲、用于写入深度信息的深度缓冲和允许我们根据一些条件丢弃特定片段的模板缓冲。这些缓冲结合起来叫做帧缓冲(Framebuffer),它被储存在内存中。OpenGL允许我们定义我们自己的帧缓冲,也就是说我们能够定义我们自己的颜色缓冲,甚至是深度缓冲和模板缓冲。
一个完整的帧缓冲需要满足以下的条件:
-
附加至少一个缓冲(颜色、深度或模板缓冲)。
-
至少有一个颜色附件(Attachment)。
-
所有的附件都必须是完整的(保留了内存)。
-
每个缓冲都应该有相同的样本数。
纹理附件
纹理附件 附加到帧缓冲的纹理
-
颜色附件
-
深度附件
-
模板附件
-
也可以一个附件用于深度和模板,例如纹理的每32位数值将包含24位的深度信息和8位的模板信息
渲染缓冲对象附件
和纹理图像一样,渲染缓冲对象是一个真正的缓冲,即一系列的字节、整数、像素等。渲染缓冲对象附加的好处是,它会将数据储存为OpenGL原生的渲染格式,它是为离屏渲染到帧缓冲优化过的。
渲染缓冲对象直接将所有的渲染数据储存到它的缓冲中,不会做任何针对纹理格式的转换,让它变为一个更快的可写储存介质。然而,渲染缓冲对象通常都是只写的,所以你不能读取它们(比如使用纹理访问)。当然你仍然还是能够使用glReadPixels来读取它,这会从当前绑定的帧缓冲,而不是附件本身,中返回特定区域的像素。
因为它的数据已经是原生的格式了,当写入或者复制它的数据到其它缓冲中时是非常快的。所以,交换缓冲这样的操作在使用渲染缓冲对象时会非常快。我们在每个渲染迭代最后使用的glfwSwapBuffers,也可以通过渲染缓冲对象实现:只需要写入一个渲染缓冲图像,并在最后交换到另外一个渲染缓冲就可以了。渲染缓冲对象对这种操作非常完美。
渲染缓冲对象通常都是只写的,它们会经常用于深度和模板附件,因为大部分时间我们都不需要从深度和模板缓冲中读取值,只关心深度和模板测试。我们需要深度和模板值用于测试,但不需要对它们进行采样,所以渲染缓冲对象非常适合它们。当我们不需要从这些缓冲中采样的时候,通常都会选择渲染缓冲对象,因为它会更优化一点。
渲染缓冲对象能为你的帧缓冲对象提供一些优化,但知道什么时候使用渲染缓冲对象,什么时候使用纹理是很重要的。通常的规则是,如果你不需要从一个缓冲中采样数据,那么对这个缓冲使用渲染缓冲对象会是明智的选择。如果你需要从缓冲中采样颜色或深度值等数据,那么你应该选择纹理附件。性能方面它不会产生非常大的影响的。
就是说,现在帧缓冲需要附件,纹理和渲染缓冲对象都可以当作这个附件,但是渲染缓冲对象一般是只写的,所以涉及到只写的可以用渲染缓冲对象,其他的用纹理
渲染到纹理
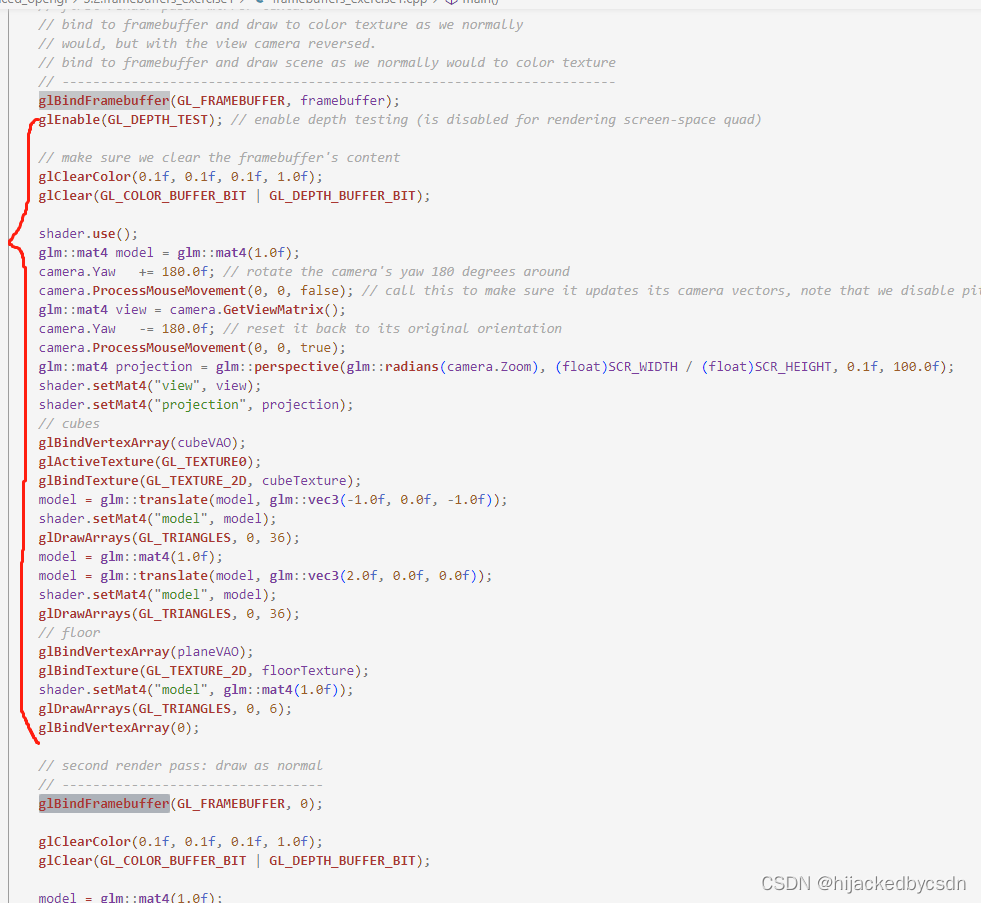
要想绘制场景到一个纹理上,我们需要采取以下的步骤:
-
将新的帧缓冲绑定为激活的帧缓冲,和往常一样渲染场景
-
绑定默认的帧缓冲
-
绘制一个横跨整个屏幕的四边形,将帧缓冲的颜色缓冲作为它的纹理。
就是绑定 VAO,使用着色程序,设置着色程序的 uniform 参数,设置 uniform sampler,最后 draw 的这一套
这一套都是对于当前缓冲来绘制的
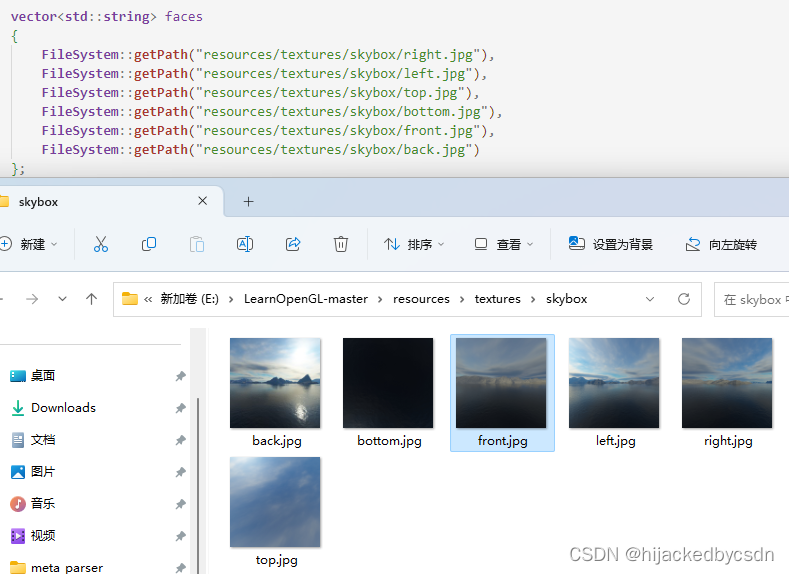
立方体贴图
创建立方体贴图
glBindTexture 中的目标点变为 GL_TEXTURE_CUBE_MAP
着色器中的 uniform 采样器的类型变为 samplerCube
六个面的枚举的 int 是线性递增的,所以可以用 for 循环来给立方体贴图的六个面上贴图
int width, height, nrChannels;
unsigned char *data;
for(unsigned int i = 0; i < textures_faces.size(); i++)
{
data = stbi_load(textures_faces[i].c_str(), &width, &height, &nrChannels, 0);
glTexImage2D(
GL_TEXTURE_CUBE_MAP_POSITIVE_X + i,
0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data
);
}
设置环绕方式用 edge,因为采样天空盒的时候,对于接缝,可能无法击中一个面(不懂)
使用一个vec3的方向向量去采样立方体贴图
in vec3 textureDir; // 代表3D纹理坐标的方向向量
uniform samplerCube cubemap; // 立方体贴图的纹理采样器
void main()
{
FragColor = texture(cubemap, textureDir);
}
天空盒
加载天空盒
显示天空盒
绑定天空盒纹理
绘制天空盒时,我们需要将它变为场景中的第一个渲染的物体,并且禁用深度写入。这样子天空盒就会永远被绘制在其它物体的背后了。
我们希望天空盒是以玩家为中心的,这样不论玩家移动了多远,天空盒都不会变近,让玩家产生周围环境非常大的印象。然而,当前的观察矩阵会旋转、缩放和位移来变换天空盒的所有位置,所以当玩家移动的时候,立方体贴图也会移动!我们希望移除观察矩阵中的位移部分,让移动不会影响天空盒的位置向量。
你可能还记得在基础光照小节中,我们通过取4x4矩阵左上角的3x3矩阵来移除变换矩阵的位移部分。我们可以将观察矩阵转换为3x3矩阵(移除位移),再将其转换回4x4矩阵,来达到类似的效果。
glm::mat4 view = glm::mat4(glm::mat3(camera.GetViewMatrix()));
这将移除任何的位移,但保留旋转变换,让玩家仍然能够环顾场景。
优化
目前我们是首先渲染天空盒,之后再渲染场景中的其它物体。这样子能够工作,但不是非常高效。如果我们先渲染天空盒,我们就会对屏幕上的每一个像素运行一遍片段着色器,即便只有一小部分的天空盒最终是可见的。可以使用提前深度测试(Early Depth Testing)轻松丢弃掉的片段能够节省我们很多宝贵的带宽。
所以,我们将会最后渲染天空盒,以获得轻微的性能提升。这样子的话,深度缓冲就会填充满所有物体的深度值了,我们只需要在提前深度测试通过的地方渲染天空盒的片段就可以了,很大程度上减少了片段着色器的调用。问题是,天空盒很可能会渲染在所有其他对象之上,因为它只是一个1x1x1的立方体(译注:意味着距离摄像机的距离也只有1),会通过大部分的深度测试。不用深度测试来进行渲染不是解决方案,因为天空盒将会复写场景中的其它物体。我们需要欺骗深度缓冲,让它认为天空盒有着最大的深度值1.0,只要它前面有一个物体,深度测试就会失败。
在坐标系统小节中我们说过,透视除法是在顶点着色器运行之后执行的,将gl_Position的xyz坐标除以w分量。我们又从深度测试小节中知道,相除结果的z分量等于顶点的深度值。使用这些信息,我们可以将输出位置的z分量等于它的w分量,让z分量永远等于1.0,这样子的话,当透视除法执行之后,z分量会变为w / w = 1.0。
输入顶点 -> 顶点着色器 -> 传入模型矩阵,观察矩阵,投影矩阵到顶点着色器中 -> 在顶点着色器中完成顶点坐标的 MVP 变换,得到的结果赋到 gl_Position -> 顶点着色器结束 -> OpenGL 对 gl_Position 执行透视除法,将位置向量 gl_Position 的x,y,z分量分别除以向量的齐次w分量 -> gl_Position 变为 3D 标准化设备坐标
gl_Position 仅能在顶点着色器中使用
void main()
{
TexCoords = aPos;
vec4 pos = projection * view * vec4(aPos, 1.0);
gl_Position = pos.xyww;
}
最终的标准化设备坐标将永远会有一个等于1.0的z值:最大的深度值。结果就是天空盒只会在没有可见物体的地方渲染了(只有这样才能通过深度测试,其它所有的东西都在天空盒前面)。
我们还要改变一下深度函数,将它从默认的GL_LESS改为GL_LEQUAL。深度缓冲将会填充上天空盒的1.0值,所以我们需要保证天空盒在值小于或等于深度缓冲而不是小于时通过深度测试。
(这句话我还是不懂什么意思,什么叫作填充 1 所以要小于等于而不是小于)
(应该是 glClear 清理深度缓冲的时候,默认是把深度缓冲全赋为 1,然后现在天空盒的深度经过一番操作后也是 1,所以我们需要小于或等于,才能通过与 1 的比较)
环境映射
在计算物体的 shading 的时候,在片元着色器计算片元颜色时,从环境贴图采样颜色
这里是直接用视线方向反射得到的向量去采样环境贴图,得到的效果就是物体颜色是完全反射环境贴图的
#version 330 core
out vec4 FragColor;
in vec3 Normal;
in vec3 Position;
uniform vec3 cameraPos;
uniform samplerCube skybox;
void main()
{
vec3 I = normalize(Position - cameraPos);
vec3 R = reflect(I, normalize(Normal));
FragColor = vec4(texture(skybox, R).rgb, 1.0);
}
这里是把折射的向量用来采样环境贴图
void main()
{
float ratio = 1.00 / 1.52;
vec3 I = normalize(Position - cameraPos);
vec3 R = refract(I, normalize(Normal), ratio);
FragColor = vec4(texture(skybox, R).rgb, 1.0);
}
跟之前的 phong shading 还不一样,我还以为他会把反射/折射环境贴图的颜色作为 diffuse 呢
动态环境贴图
现在我们使用的都是静态图像的组合来作为天空盒,看起来很不错,但它没有在场景中包括可移动的物体。我们一直都没有注意到这一点,因为我们只使用了一个物体。如果我们有一个镜子一样的物体,周围还有多个物体,镜子中可见的只有天空盒,看起来就像它是场景中唯一一个物体一样。
通过使用帧缓冲,我们能够为物体的6个不同角度创建出场景的纹理,并在每个渲染迭代中将它们储存到一个立方体贴图中。之后我们就可以使用这个(动态生成的)立方体贴图来创建出更真实的,包含其它物体的,反射和折射表面了。这就叫做动态环境映射(Dynamic Environment Mapping),因为我们动态创建了物体周围的立方体贴图,并将其用作环境贴图。
虽然它看起来很棒,但它有一个很大的缺点:我们需要为使用环境贴图的物体渲染场景6次,这是对程序是非常大的性能开销。现代的程序通常会尽可能使用天空盒,并在可能的时候使用预编译的立方体贴图,只要它们能产生一点动态环境贴图的效果。虽然动态环境贴图是一个很棒的技术,但是要想在不降低性能的情况下让它工作还是需要非常多的技巧的。
摄像机看到的是天空盒内部
摄像机看到的是天空盒内部,而天空盒内部应该是背面,那么天空盒内部看到的应该是左右颠倒的纹理
但是实际上我看到的是没有左右颠倒的
这是因为代码中的天空盒的顶点设置就是,从内部看过去,看到的就是逆时针的面,在 opengl 中这被判断为正面
例如 -Z 面是这样的
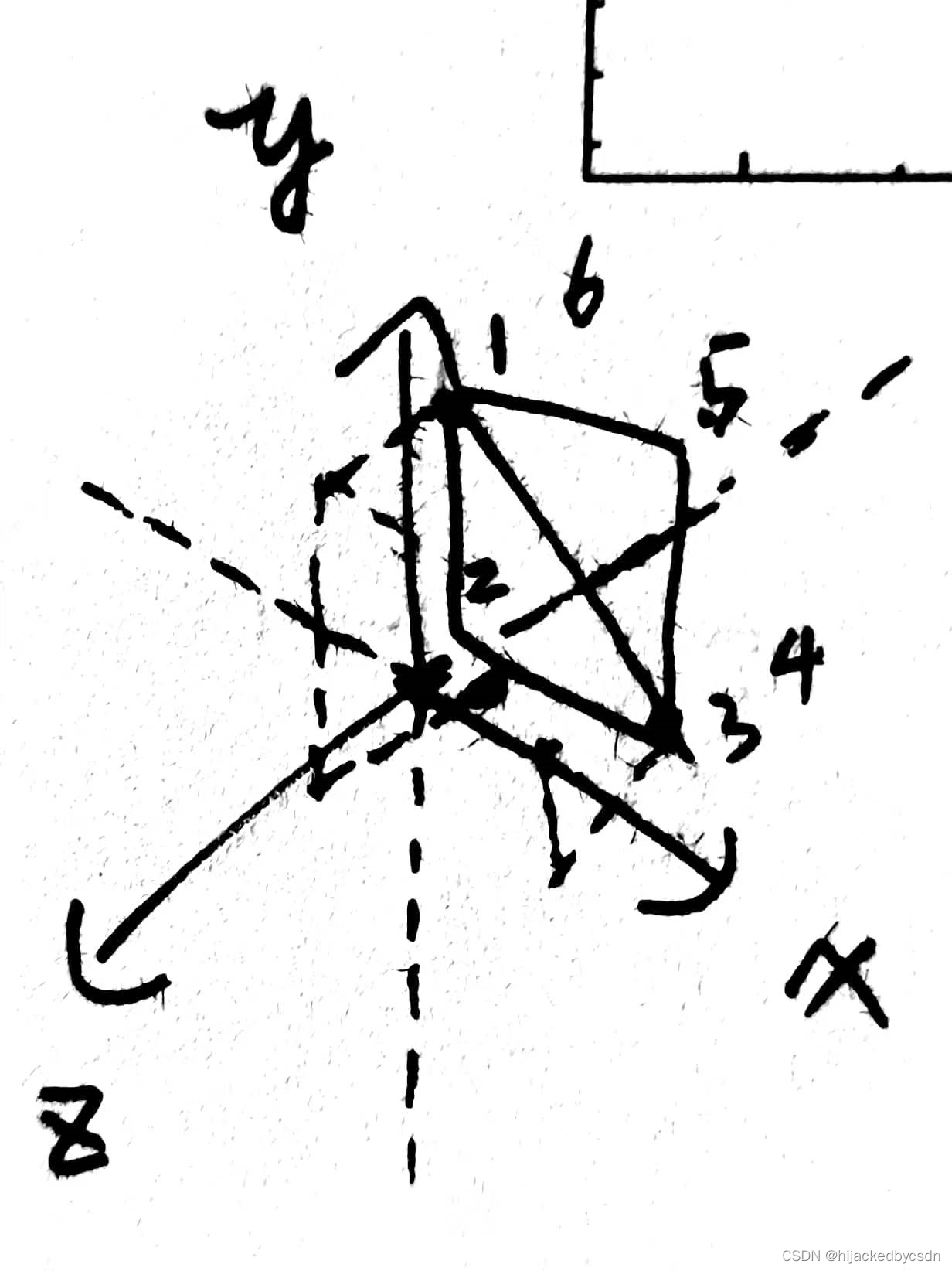
可见,摄像机默认 (0,0,0) 的时候看向 -Z,看到的是正面
然后他这个教程里面展示的天空盒的 front 和 back 是跟实际代码仓库里面的是不一样的
教程里面:

那么他 GL_TEXTURE_CUBE_MAP_POSITIVE_Z 是 front 的话,那么我应该是在后面看到那个蓝色的山,实际上我是在前面就看到蓝色的山
实际上他这里把 back 设成蓝色的山了……
高级数据
glBufferData 分配一块内存,将数据复制到这个内存
如果没有传入数据,那么就只是分配一块内存
glBufferSubData 填充缓冲的特定区域。这个函数需要一个缓冲目标、一个偏移量、数据的大小和数据本身作为它的参数
这个函数不同的地方在于,我们可以提供一个偏移量,指定从何处开始填充这个缓冲。这能够让我们插入或者更新缓冲内存的某一部分。要注意的是,缓冲需要有足够的已分配内存,所以对一个缓冲调用glBufferSubData之前必须要先调用glBufferData。
glBufferSubData(GL_ARRAY_BUFFER, 24, sizeof(data), &data); // 范围: [24, 24 + sizeof(data)]
当然,glBufferData 和 glBufferSubData 都是对 glBindBuffer 绑定的缓冲对象来操作
通过调用glMapBuffer函数,OpenGL会返回当前绑定缓冲的内存指针
使用 glUnmapBuffer 解除指针
如果要直接映射数据到缓冲,而不事先将其存储到临时内存中,glMapBuffer 这个函数会很有用。比如说,你可以从文件中读取数据,并直接将它们复制到缓冲内存中。
分批顶点属性
以前都是对数据进行交错处理
我们可以做的是,将每一种属性类型的向量数据打包(Batch)为一个大的区块,而不是对它们进行交错储存。与交错布局123123123123不同,我们将采用分批(Batched)的方式111122223333。
因为当从文件中加载顶点数据的时候,你通常获取到的是一个位置数组、一个法线数组和/或一个纹理坐标数组。所以要交错放置还比较麻烦,如果使用分批的方式,就可以不用处理了
float positions[] = { ... };
float normals[] = { ... };
float tex[] = { ... };
// 填充缓冲
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(positions), &positions);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions), sizeof(normals), &normals);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions) + sizeof(normals), sizeof(tex), &tex);
设置顶点属性指针来解释缓冲
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), 0);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)(sizeof(positions)));
glVertexAttribPointer(
2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)(sizeof(positions) + sizeof(normals)));
对比以前坐标和 uv 交替放置的:
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)0);
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)(3 * sizeof(float)));
最后的 offset,分批方式的话,是以整个数据的大小为 offset,而交错方式的话,是以坐标的 3 个 float 的大小为 offset,这就看出差别了
复制缓冲
当你的缓冲已经填充好数据之后,你可能会想与其它的缓冲共享其中的数据,或者想要将缓冲的内容复制到另一个缓冲当中。glCopyBufferSubData能够让我们相对容易地从一个缓冲中复制数据到另一个缓冲中。这个函数的原型如下:
void glCopyBufferSubData(GLenum readtarget, GLenum writetarget, GLintptr readoffset,
GLintptr writeoffset, GLsizeiptr size);
readtarget和writetarget参数需要填入复制源和复制目标的缓冲目标。比如说,我们可以将VERTEX_ARRAY_BUFFER缓冲复制到VERTEX_ELEMENT_ARRAY_BUFFER缓冲,分别将这些缓冲目标设置为读和写的目标。当前绑定到这些缓冲目标的缓冲将会被影响到。
但如果我们想读写数据的两个不同缓冲都为顶点数组缓冲该怎么办呢?我们不能同时将两个缓冲绑定到同一个缓冲目标上。正是出于这个原因,OpenGL提供给我们另外两个缓冲目标,叫做GL_COPY_READ_BUFFER和GL_COPY_WRITE_BUFFER。我们接下来就可以将需要的缓冲绑定到这两个缓冲目标上,并将这两个目标作为readtarget和writetarget参数。
接下来glCopyBufferSubData会从readtarget中读取size大小的数据,并将其写入writetarget缓冲的writeoffset偏移量处。下面这个例子展示了如何复制两个顶点数组缓冲:
float vertexData[] = { ... };
glBindBuffer(GL_COPY_READ_BUFFER, vbo1);
glBindBuffer(GL_COPY_WRITE_BUFFER, vbo2);
glCopyBufferSubData(GL_COPY_READ_BUFFER, GL_COPY_WRITE_BUFFER, 0, 0, sizeof(vertexData));
我们也可以只将writetarget缓冲绑定为新的缓冲目标类型之一:
float vertexData[] = { ... };
glBindBuffer(GL_ARRAY_BUFFER, vbo1);
glBindBuffer(GL_COPY_WRITE_BUFFER, vbo2);
glCopyBufferSubData(GL_ARRAY_BUFFER, GL_COPY_WRITE_BUFFER, 0, 0, sizeof(vertexData));
有了这些关于如何操作缓冲的额外知识,我们已经能够以更有意思的方式使用它们了。当你越深入OpenGL时,这些新的缓冲方法将会变得更加有用。在下一节中,在我们讨论Uniform缓冲对象(Uniform Buffer Object)时,我们将会充分利用glBufferSubData。
高级GLSL
GLSL的内建变量
我们已经在前面教程中接触过其中的两个了:顶点着色器的输出向量gl_Position,和片段着色器的gl_FragCoord。
顶点着色器变量
gl_Position
之前我们用的图元是三角形,如果用的图元是点的话 GL_POINTS,那么可以修改这个点图元的大小
在顶点着色器中修改点大小的功能默认是禁用的,如果你需要启用它的话,你需要启用OpenGL的GL_PROGRAM_POINT_SIZE:
glEnable(GL_PROGRAM_POINT_SIZE);
顶点着色器中有一个 gl_PointSize 用于设置点图元的大小
可用于粒子生成
整型变量gl_VertexID储存了正在绘制顶点的当前ID。当(使用glDrawElements)进行索引渲染的时候,这个变量会存储正在绘制顶点的当前索引。当(使用glDrawArrays)不使用索引进行绘制的时候,这个变量会储存从渲染调用开始的已处理顶点数量。
片段着色器变量
gl_FragCoord的x和y分量是片段的窗口空间(Window-space)坐标,其原点为窗口的左下角。我们已经使用glViewport设定了一个800x600的窗口了,所以片段窗口空间坐标的x分量将在0到800之间,y分量在0到600之间。
gl_FrontFacing变量是一个bool,如果当前片段是正向面的一部分那么就是true,否则就是false
注意,如果你开启了面剔除,你就看不到箱子内部的面了,所以现在再使用gl_FrontFacing就没有意义了。
gl_FragCoord 是只读的,但是我们可以用 gl_FragDepth 修改深度
要想设置深度值,我们直接写入一个0.0到1.0之间的float值到输出变量就可以了:
如果着色器没有写入值到gl_FragDepth,它会自动取用gl_FragCoord.z的值。
然而,由我们自己设置深度值有一个很大的缺点,只要我们在片段着色器中对gl_FragDepth进行写入,OpenGL就会(像深度测试小节中讨论的那样)禁用所有的提前深度测试(Early Depth Testing)。它被禁用的原因是,OpenGL无法在片段着色器运行之前得知片段将拥有的深度值,因为片段着色器可能会完全修改这个深度值。
在写入gl_FragDepth时,你就需要考虑到它所带来的性能影响。然而,从OpenGL 4.2起,我们仍可以对两者进行一定的调和,在片段着色器的顶部使用深度条件(Depth Condition)重新声明gl_FragDepth变量:
layout (depth_<condition>) out float gl_FragDepth;
condition可以为下面的值:
| 条件 | 描述 |
|---|---|
| any | 默认值。提前深度测试是禁用的,你会损失很多性能 |
| greater | 你只能让深度值比gl_FragCoord.z更大 |
| less | 你只能让深度值比gl_FragCoord.z更小 |
| unchanged | 如果你要写入gl_FragDepth,你将只能写入gl_FragCoord.z的值 |
通过将深度条件设置为greater或者less,OpenGL就能假设你只会写入比当前片段深度值更大或者更小的值了。这样子的话,当深度值比片段的深度值要小的时候,OpenGL仍是能够进行提前深度测试的。
下面这个例子中,我们对片段的深度值进行了递增,但仍然也保留了一些提前深度测试:
#version 420 core // 注意GLSL的版本!
out vec4 FragColor;
layout (depth_greater) out float gl_FragDepth;
void main()
{
FragColor = vec4(1.0);
gl_FragDepth = gl_FragCoord.z + 0.1;
}
注意这个特性只在OpenGL 4.2版本或以上才提供。
我有个疑惑,为什么这里说的是深度值比片段的深度值要小的时候
我看了原文说的是
By specifying greater or less as the depth condition, OpenGL can make the assumption that you’ll only write depth values larger or smaller than the fragment’s depth value. This way OpenGL is still able to do early depth testing when the depth buffer value is part of the other direction of gl_FragCoord.z.
我也不知道“另一个方向的一部分”是什么意思……
我觉得它的意思就是,如果不限定 gl_FragDepth,那么就不能用 early z 因为不知道你之后会把深度值改成什么样子
但是如果限定 gl_FragDepth 不会干扰 early z,那么就可以发生 early z
并且我的理解是,只要开启了深度测试,是硬件来决定是否 early z 的
然后什么限定 gl_FragDepth 来能不干扰 early z 呢,就是遵循确定性的原则,假设深度测试函数是 GL_LESS,那么 gl_FragDepth 就应该是 layout (depth_greater),这样,不管片元着色器中的 z 干了什么,early z 的结果都是对的,因为片元着色器只会让 z 更大,那么 early z 中被剔除的始终会被剔除,那么硬件就会开启 early z
(但是问题是,如果两个东西的 z 的变大的幅度不一样,那么这两个东西的 z 之间的大小关系仍然可能不一样呀,例如物体 A 中某个片元的 z 是 0.1,B 中某个片元 z 是 0.2,那么如果 0.1 变到 0.4,0.2 变到 0.3,那不就会是 B 遮挡 A?感觉我不能这么想,early z 之后 B 这个片元已经不会渲染了,怎么还能修改……)
相关的还有 early z 和 z prepass 的区别
接口块
到目前为止,每当我们希望从顶点着色器向片段着色器发送数据时,我们都声明了几个对应的输入/输出变量。将它们一个一个声明是着色器间发送数据最简单的方式了,但当程序变得更大时,你希望发送的可能就不只是几个变量了,它还可能包括数组和结构体。
为了帮助我们管理这些变量,GLSL为我们提供了一个叫做接口块(Interface Block)的东西,来方便我们组合这些变量。接口块的声明和struct的声明有点相像,不同的是,现在根据它是一个输入还是输出块(Block),使用in或out关键字来定义的。
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec2 aTexCoords;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
out VS_OUT
{
vec2 TexCoords;
} vs_out;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
vs_out.TexCoords = aTexCoords;
}
这次我们声明了一个叫做vs_out的接口块,它打包了我们希望发送到下一个着色器中的所有输出变量。这只是一个很简单的例子,但你可以想象一下,它能够帮助你管理着色器的输入和输出。当我们希望将着色器的输入或输出打包为数组时,它也会非常有用,我们将在下一节讨论几何着色器(Geometry Shader)时见到。
之后,我们还需要在下一个着色器,即片段着色器,中定义一个输入接口块。块名(Block Name)应该是和着色器中一样的(VS_OUT),但实例名(Instance Name)(顶点着色器中用的是vs_out)可以是随意的,但要避免使用误导性的名称,比如对实际上包含输入变量的接口块命名为vs_out。
#version 330 core
out vec4 FragColor;
in VS_OUT
{
vec2 TexCoords;
} fs_in;
uniform sampler2D texture;
void main()
{
FragColor = texture(texture, fs_in.TexCoords);
}
只要两个接口块的名字一样,它们对应的输入和输出将会匹配起来。这是帮助你管理代码的又一个有用特性,它在几何着色器这样穿插特定着色器阶段的场景下会很有用。
Uniform缓冲对象 UBO
我们已经使用OpenGL很长时间了,学会了一些很酷的技巧,但也遇到了一些很麻烦的地方。比如说,当使用多于一个的着色器时,尽管大部分的uniform变量都是相同的,我们还是需要不断地设置它们,所以为什么要这么麻烦地重复设置它们呢?
OpenGL为我们提供了一个叫做Uniform缓冲对象(Uniform Buffer Object)的工具,它允许我们定义一系列在多个着色器中相同的全局Uniform变量。当使用Uniform缓冲对象的时候,我们只需要设置相关的uniform一次。当然,我们仍需要手动设置每个着色器中不同的uniform。并且创建和配置Uniform缓冲对象会有一点繁琐。
因为Uniform缓冲对象仍是一个缓冲,我们可以使用glGenBuffers来创建它,将它绑定到GL_UNIFORM_BUFFER缓冲目标,并将所有相关的uniform数据存入缓冲。在Uniform缓冲对象中储存数据是有一些规则的,我们将会在之后讨论它。首先,我们将使用一个简单的顶点着色器,将projection和view矩阵存储到所谓的Uniform块(Uniform Block)中:
#version 330 core
layout (location = 0) in vec3 aPos;
layout (std140) uniform Matrices
{
mat4 projection;
mat4 view;
};
uniform mat4 model;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
}
在我们大多数的例子中,我们都会在每个渲染迭代中,对每个着色器设置projection和view Uniform矩阵。这是利用Uniform缓冲对象的一个非常完美的例子,因为现在我们只需要存储这些矩阵一次就可以了。
这里,我们声明了一个叫做Matrices的Uniform块,它储存了两个4x4矩阵。Uniform块中的变量可以直接访问,不需要加块名作为前缀。接下来,我们在OpenGL代码中将这些矩阵值存入缓冲中,每个声明了这个Uniform块的着色器都能够访问这些矩阵。
你现在可能会在想layout (std140)这个语句是什么意思。它的意思是说,当前定义的Uniform块对它的内容使用一个特定的内存布局。这个语句设置了Uniform块布局(Uniform Block Layout)。
Uniform块布局
内存对齐的原则
std140 布局规则:
| 类型 | 布局规则 |
|---|---|
| 标量,比如int和bool | 每个标量的基准对齐量为N。 |
| 向量 | 2N或者4N。这意味着vec3的基准对齐量为4N。 |
| 标量或向量的数组 | 每个元素的基准对齐量与vec4的相同。 |
| 矩阵 | 储存为列向量的数组,每个向量的基准对齐量与vec4的相同。 |
| 结构体 | 等于所有元素根据规则计算后的大小,但会填充到vec4大小的倍数。 |
例子:
layout (std140) uniform ExampleBlock
{
// 基准对齐量 // 对齐偏移量
float value; // 4 // 0
vec3 vector; // 16 // 16 (必须是16的倍数,所以 4->16)
mat4 matrix; // 16 // 32 (列 0)
// 16 // 48 (列 1)
// 16 // 64 (列 2)
// 16 // 80 (列 3)
float values[3]; // 16 // 96 (values[0])
// 16 // 112 (values[1])
// 16 // 128 (values[2])
bool boolean; // 4 // 144
int integer; // 4 // 148
};
通过在Uniform块定义之前添加layout (std140)语句,我们告诉OpenGL这个Uniform块使用的是std140布局。除此之外还可以选择两个布局,但它们都需要我们在填充缓冲之前先查询每个偏移量。我们已经见过shared布局了,剩下的一个布局是packed。当使用紧凑(Packed)布局时,是不能保证这个布局在每个着色程序中保持不变的(即非共享),因为它允许编译器去将uniform变量从Uniform块中优化掉,这在每个着色器中都可能是不同的。
就是说,用 uniform 块并且确定了布局方式,就可以在 cpp 中手动计算出来某个值的偏移,然后在 cpp 中赋值
-
packed 不仅不同OpenGL实现存在布局差异,不同program也可能存在布局差异
-
shared(默认布局) 不同OpenGL实现存在布局差异,不同program如果使用相同定义没有布局差异
-
std140 不同OpenGL实现不存在布局差异
通常来说,我们的相机和光源会使用UBO存储,方便在多个不同的program进行绑定,因为不同program布局差异,所以无法使用packed布局。
而使用shared布局需要我们先编译一个代理program来获取具体布局,虽然可以在不同的program中使用,但不方便离线处理。
(感觉应该是,我们不知道shared布局具体规则,然后可以先搞一个空的着色程序,然后)
std140布局则保证不同OpenGL实现满足同样的布局规则,使用更为方便。
使用Uniform缓冲
glGenBuffers 创建缓冲
glBindBuffer 把缓冲绑定到 GL_UNIFORM_BUFFER
glBufferData 指定 GL_UNIFORM_BUFFER,分配内存
glBufferSubData 由程序员根据 std140 布局计算好 offset, 赋 uniform 块中某个成员的值
然后需要将着色器绑定到绑定点,将 UBO 绑定到绑定点
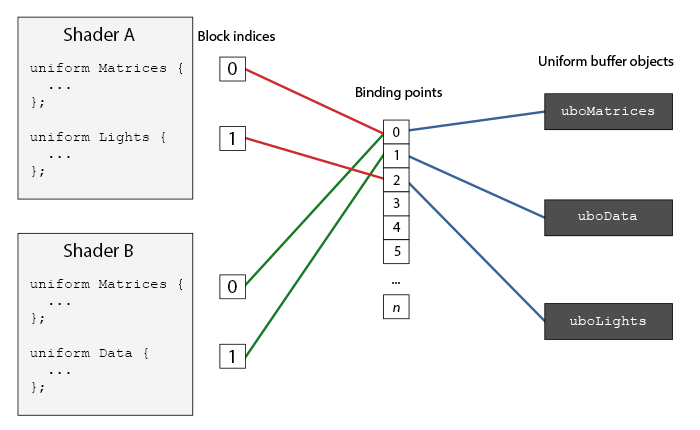
将着色器绑定到绑定点有两种方法:
第一种方法是用 glGetUniformBlockIndex 从着色器获得某个 uniform block 的 id,然后用 glUniformBlockBinding 指定这个着色器,和 uniform block 的 id,绑定到指定的绑定点
第二种方法是从OpenGL 4.2版本起,在着色器代码中添加一个布局标识符,显式地将Uniform块的绑定点储存在着色器中,这样就不用再调用glGetUniformBlockIndex和glUniformBlockBinding了。下面的代码显式地设置了Lights Uniform块的绑定点。
layout(std140, binding = 2) uniform Lights { ... };
另一方面,将 UBO 绑定到绑定点:
可以使用glBindBufferBase或glBindBufferRange来完成。
glBindBufferBase(GL_UNIFORM_BUFFER, 2, uboExampleBlock);
// 或
glBindBufferRange(GL_UNIFORM_BUFFER, 2, uboExampleBlock, 0, 152);
glBindbufferBase需要一个目标,一个绑定点索引和一个Uniform缓冲对象作为它的参数。这个函数将uboExampleBlock链接到绑定点2上,自此,绑定点的两端都链接上了。你也可以使用glBindBufferRange函数,它需要一个附加的偏移量和大小参数,这样子你可以绑定Uniform缓冲的特定一部分到绑定点中。通过使用glBindBufferRange函数,你可以让多个不同的Uniform块绑定到同一个Uniform缓冲对象上。
现在,所有的东西都配置完毕了,我们可以开始向Uniform缓冲中添加数据了。只要我们需要,就可以使用glBufferSubData函数,用一个字节数组添加所有的数据,或者更新缓冲的一部分。要想更新uniform变量boolean,我们可以用以下方式更新Uniform缓冲对象:
glBindBuffer(GL_UNIFORM_BUFFER, uboExampleBlock);
int b = true; // GLSL中的bool是4字节的,所以我们将它存为一个integer
glBufferSubData(GL_UNIFORM_BUFFER, 144, 4, &b);
glBindBuffer(GL_UNIFORM_BUFFER, 0);
同样的步骤也能应用到Uniform块中其它的uniform变量上,但需要使用不同的范围参数。
Uniform缓冲对象比起独立的uniform有很多好处。第一,一次设置很多uniform会比一个一个设置多个uniform要快很多。第二,比起在多个着色器中修改同样的uniform,在Uniform缓冲中修改一次会更容易一些。最后一个好处可能不会立即显现,如果使用Uniform缓冲对象的话,你可以在着色器中使用更多的uniform。OpenGL限制了它能够处理的uniform数量,这可以通过GL_MAX_VERTEX_UNIFORM_COMPONENTS来查询。当使用Uniform缓冲对象时,最大的数量会更高。所以,当你达到了uniform的最大数量时(比如再做骨骼动画(Skeletal Animation)的时候),你总是可以选择使用Uniform缓冲对象。
几何着色器
几何着色器的 glsl 的内建变量:
in gl_Vertex
{
vec4 gl_Position;
float gl_PointSize;
float gl_ClipDistance[];
} gl_in[];
看原文就好了
原文可能没有细讲的是,几何着色器中 EmitVertex(); 的效果
例子:
几何着色器:
#version 330 core
layout (points) in;
layout (triangle_strip, max_vertices = 5) out;
in VS_OUT {
vec3 color;
} gs_in[];
out vec3 fColor;
void build_house(vec4 position)
{
fColor = gs_in[0].color; // gs_in[0] since there's only one input vertex
gl_Position = position + vec4(-0.2, -0.2, 0.0, 0.0); // 1:bottom-left
EmitVertex();
gl_Position = position + vec4( 0.2, -0.2, 0.0, 0.0); // 2:bottom-right
EmitVertex();
gl_Position = position + vec4(-0.2, 0.2, 0.0, 0.0); // 3:top-left
EmitVertex();
gl_Position = position + vec4( 0.2, 0.2, 0.0, 0.0); // 4:top-right
EmitVertex();
gl_Position = position + vec4( 0.0, 0.4, 0.0, 0.0); // 5:top
fColor = vec3(1.0, 1.0, 1.0);
EmitVertex();
EndPrimitive();
}
void main() {
build_house(gl_in[0].gl_Position);
}
片元着色器:
#version 330 core
out vec4 FragColor;
in vec3 fColor;
void main()
{
FragColor = vec4(fColor, 1.0);
}
他这里每一次 EmitVertex(); 都会发出 gl_Position 和 fColor,我猜这可能是因为几何着色器中定义了 out vec3 fColor;,所以发送的顶点是包含这个 out 的属性的
实例化
假设你有一个绘制了很多模型的场景,而大部分的模型包含的是同一组顶点数据,只不过进行的是不同的世界空间变换。想象一个充满草的场景:每根草都是一个包含几个三角形的小模型。你可能会需要绘制很多根草,最终在每帧中你可能会需要渲染上千或者上万根草。因为每一根草仅仅是由几个三角形构成,渲染几乎是瞬间完成的,但上千个渲染函数调用却会极大地影响性能。
如果我们需要渲染大量物体时,代码看起来会像这样:
for(unsigned int i = 0; i < amount_of_models_to_draw; i++)
{
DoSomePreparations(); // 绑定VAO,绑定纹理,设置uniform等
glDrawArrays(GL_TRIANGLES, 0, amount_of_vertices);
}
如果像这样绘制模型的大量实例(Instance),你很快就会因为绘制调用过多而达到性能瓶颈。与绘制顶点本身相比,使用glDrawArrays或glDrawElements函数告诉GPU去绘制你的顶点数据会消耗更多的性能,因为OpenGL在绘制顶点数据之前需要做很多准备工作(比如告诉GPU该从哪个缓冲读取数据,从哪寻找顶点属性,而且这些都是在相对缓慢的CPU到GPU总线(CPU to GPU Bus)上进行的)。所以,即便渲染顶点非常快,命令GPU去渲染却未必。
如果我们能够将数据一次性发送给GPU,然后使用一个绘制函数让OpenGL利用这些数据绘制多个物体,就会更方便了。这就是实例化(Instancing)。
实例化这项技术能够让我们使用一个渲染调用来绘制多个物体,来节省每次绘制物体时CPU -> GPU的通信,它只需要一次即可。如果想使用实例化渲染,我们只需要将glDrawArrays和glDrawElements的渲染调用分别改为glDrawArraysInstanced和glDrawElementsInstanced就可以了。这些渲染函数的实例化版本需要一个额外的参数,叫做实例数量(Instance Count),它能够设置我们需要渲染的实例个数。这样我们只需要将必须的数据发送到GPU一次,然后使用一次函数调用告诉GPU它应该如何绘制这些实例。GPU将会直接渲染这些实例,而不用不断地与CPU进行通信。
这个函数本身并没有什么用。渲染同一个物体一千次对我们并没有什么用处,每个物体都是完全相同的,而且还在同一个位置。我们只能看见一个物体!处于这个原因,GLSL在顶点着色器中嵌入了另一个内建变量,gl_InstanceID。
在使用实例化渲染调用时,gl_InstanceID会从0开始,在每个实例被渲染时递增1。比如说,我们正在渲染第43个实例,那么顶点着色器中它的gl_InstanceID将会是42。因为每个实例都有唯一的ID,顶点着色器中的 gl_InstanceID 可以用于作为 uniform 数组的索引,使得各个实例有所不同。例如,我们可以建立一个数组,将ID与位置值对应起来,将每个实例放置在世界的不同位置。
实例化数组
使用顶点属性时,顶点着色器的每次运行都会让GLSL获取新一组适用于当前顶点的属性。而当我们将顶点属性定义为一个实例化数组时,顶点着色器就只需要对每个实例,而不是每个顶点,更新顶点属性的内容了。这允许我们对逐顶点的数据使用普通的顶点属性,而对逐实例的数据使用实例化数组。
也就是,shader 中写的属性仍然是一样的
但是不再定义一个 uniform 的数组,然后用 gl_InstanceID 去取
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aOffset;
out vec3 fColor;
void main()
{
gl_Position = vec4(aPos + aOffset, 0.0, 1.0);
fColor = aColor;
}
反之,我们在 glVertexAttribPointer 这里作特殊处理
要看这个特殊处理,分两步,第一步创建 VBO
unsigned int instanceVBO;
glGenBuffers(1, &instanceVBO);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, 0);
第二步解释顶点属性
glEnableVertexAttribArray(2);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glVertexAttribDivisor(2, 1);
这段代码很有意思的地方在于最后一行,我们调用了glVertexAttribDivisor。这个函数告诉了OpenGL该什么时候更新顶点属性的内容至新一组数据。它的第一个参数是需要的顶点属性,第二个参数是属性除数(Attribute Divisor)。默认情况下,属性除数是0,告诉OpenGL我们需要在顶点着色器的每次迭代时更新顶点属性。将它设置为1时,我们告诉OpenGL我们希望在渲染一个新实例的时候更新顶点属性。而设置为2时,我们希望每2个实例更新一次属性,以此类推。我们将属性除数设置为1,是在告诉OpenGL,处于位置值2的顶点属性是一个实例化数组。
同时因为我们用的绘制函数是 glDrawArraysInstanced,所以也可以用 gl_InstanceID 配合实例化数组
此外需要注意的就是,glVertexAttribPointer 不能一次设置超过 4 个数据,所以对于 mat4 需要调用 4 次 glVertexAttribPointer,每一个设置 4 个 float
同时,glVertexAttribPointer 的序号是 layout 中的 location +0 +1 +2 +3 glVertexAttribDivisor 同理
layout (location = 3) in mat4 aInstanceMatrix;
glBindVertexArray(VAO);
// set attribute pointers for matrix (4 times vec4)
glEnableVertexAttribArray(3);
glVertexAttribPointer(3, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)0);
glEnableVertexAttribArray(4);
glVertexAttribPointer(4, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(sizeof(glm::vec4)));
glEnableVertexAttribArray(5);
glVertexAttribPointer(5, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(2 * sizeof(glm::vec4)));
glEnableVertexAttribArray(6);
glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(3 * sizeof(glm::vec4)));
glVertexAttribDivisor(3, 1);
glVertexAttribDivisor(4, 1);
glVertexAttribDivisor(5, 1);
glVertexAttribDivisor(6, 1);
glBindVertexArray(0);
抗锯齿
请问FXAA、FSAA与MSAA有什么区别?效果和性能上哪个好? - 文刀秋二的回答 - 知乎
https://www.zhihu.com/question/20236638/answer/44821615
大多数的窗口系统都应该提供了一个多重采样缓冲,用以代替默认的颜色缓冲。GLFW同样给了我们这个功能,我们所要做的只是提示(Hint) GLFW,我们希望使用一个包含N个样本的多重采样缓冲。这可以在创建窗口之前调用glfwWindowHint来完成。
glfwWindowHint(GLFW_SAMPLES, 4);
现在再调用glfwCreateWindow创建渲染窗口时,每个屏幕坐标就会使用一个包含4个子采样点的颜色缓冲了。GLFW会自动创建一个每像素4个子采样点的深度和样本缓冲。这也意味着所有缓冲的大小都增长了4倍。
现在我们已经向GLFW请求了多重采样缓冲,我们还需要调用glEnable并启用GL_MULTISAMPLE,来启用多重采样。在大多数OpenGL的驱动上,多重采样都是默认启用的,所以这个调用可能会有点多余,但显式地调用一下会更保险一点。这样子不论是什么OpenGL的实现都能够正常启用多重采样了。
glEnable(GL_MULTISAMPLE);
只要默认的帧缓冲有了多重采样缓冲的附件,我们所要做的只是调用glEnable来启用多重采样。因为多重采样的算法都在OpenGL驱动的光栅器中实现了,我们不需要再多做什么。如果现在再来渲染本节一开始的那个绿色的立方体,我们应该能看到更平滑的边缘:
离屏MSAA
由于GLFW负责了创建多重采样缓冲,启用MSAA非常简单。然而,如果我们想要使用我们自己的帧缓冲来进行离屏渲染,那么我们就必须要自己动手生成多重采样缓冲了。
有两种方式可以创建多重采样缓冲,将其作为帧缓冲的附件:纹理附件和渲染缓冲附件,这和在帧缓冲教程中所讨论的普通附件很相似。
多重采样纹理附件
为了创建一个支持储存多个采样点的纹理,我们使用glTexImage2DMultisample来替代glTexImage2D,它的纹理目标是GL_TEXTURE_2D_MULTISAPLE。
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, tex);
glTexImage2DMultisample(GL_TEXTURE_2D_MULTISAMPLE, samples, GL_RGB, width, height, GL_TRUE);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, 0);
它的第二个参数设置的是纹理所拥有的样本个数。如果最后一个参数为GL_TRUE,图像将会对每个纹素使用相同的样本位置以及相同数量的子采样点个数。
我们使用glFramebufferTexture2D将多重采样纹理附加到帧缓冲上,但这里纹理类型使用的是GL_TEXTURE_2D_MULTISAMPLE。
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D_MULTISAMPLE, tex, 0);
当前绑定的帧缓冲现在就有了一个纹理图像形式的多重采样颜色缓冲。
多重采样渲染缓冲对象
和纹理类似,创建一个多重采样渲染缓冲对象并不难。我们所要做的只是在指定(当前绑定的)渲染缓冲的内存存储时,将glRenderbufferStorage的调用改为glRenderbufferStorageMultisample就可以了。
glRenderbufferStorageMultisample(GL_RENDERBUFFER, 4, GL_DEPTH24_STENCIL8, width, height);
函数中,渲染缓冲对象后的参数我们将设定为样本的数量,在当前的例子中是4。
渲染到多重采样帧缓冲
多重采样帧缓冲 framebuffer 先渲染,渲染之后用 glBlitFramebuffer 移动到普通帧缓冲 intermediateFBO,这个普通帧缓冲有一个颜色纹理部件 screenTexture,然后 glBindFramebuffer(GL_FRAMEBUFFER, 0); 切换到默认帧缓冲,这是窗口显示的帧缓冲,这里把 screenTexture 传入着色程序,就可以用上 多重采样帧缓冲 framebuffer 的结果了
// 1. draw scene as normal in multisampled buffers
glBindFramebuffer(GL_FRAMEBUFFER, framebuffer);
glClearColor(0.1f, 0.1f, 0.1f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glEnable(GL_DEPTH_TEST);
// set transformation matrices
shader.use();
glm::mat4 projection = glm::perspective(glm::radians(camera.Zoom), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 1000.0f);
shader.setMat4("projection", projection);
shader.setMat4("view", camera.GetViewMatrix());
shader.setMat4("model", glm::mat4(1.0f));
glBindVertexArray(cubeVAO);
glDrawArrays(GL_TRIANGLES, 0, 36);
// 2. now blit multisampled buffer(s) to normal colorbuffer of intermediate FBO. Image is stored in screenTexture
glBindFramebuffer(GL_READ_FRAMEBUFFER, framebuffer);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, intermediateFBO);
glBlitFramebuffer(0, 0, SCR_WIDTH, SCR_HEIGHT, 0, 0, SCR_WIDTH, SCR_HEIGHT, GL_COLOR_BUFFER_BIT, GL_NEAREST);
// 3. now render quad with scene's visuals as its texture image
glBindFramebuffer(GL_FRAMEBUFFER, 0);
glClearColor(1.0f, 1.0f, 1.0f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
glDisable(GL_DEPTH_TEST);
// draw Screen quad
screenShader.use();
glBindVertexArray(quadVAO);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, screenTexture); // use the now resolved color attachment as the quad's texture
glDrawArrays(GL_TRIANGLES, 0, 6);
自定义抗锯齿算法
将一个多重采样的纹理图像不进行还原直接传入着色器也是可行的。GLSL提供了这样的选项,让我们能够对纹理图像的每个子样本进行采样,所以我们可以创建我们自己的抗锯齿算法。在大型的图形应用中通常都会这么做。
要想获取每个子样本的颜色值,你需要将纹理uniform采样器设置为sampler2DMS,而不是平常使用的sampler2D:
uniform sampler2DMS screenTextureMS;
使用texelFetch函数就能够获取每个子样本的颜色值了:
vec4 colorSample = texelFetch(screenTextureMS, TexCoords, 3); // 第4个子样本
我们不会深入探究自定义抗锯齿技术的细节,这里仅仅是给你一点启发。















 3735
3735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









