







文章目录
在本文中:
- 会实战一个机器学习项目,这个项目包含从数据导入到生成模型,以及通过模型对数据进行分类的全部过程。通过这个项目我们会了解机器学习项目中的各个步骤。
- 会对python的机器学习库有一个使用上的认识,比如在这个项目中,我们
- 使用pandas数据摄入与分析)进行了数据摄入、求统计值
- 使用sklearn(提供了哪些模型)进行了模型准确度的测试、模型的导出
- 使用matplotlib(图形化展示):展示了数据的直方、箱线、散点矩阵图等
之后的文章会系统性地介绍这些机器学习库。
但是具体的模型逻辑(算法的基本原理)、
一. 项目概述
这个项目是针对鸢尾花(Iris Flower)进行分类的一个项目,数据集是含鸢尾花的三个亚属的分类信息,通过机器学习算法生成一个模型,自动分类新数据到这三个亚属的某一个中。
数据特点
- 所有的特征数据都是数字,不需要考虑如何导入和处理数据。
- 这是一个分类问题,可以很方便地通过有监督学习算法来解决问题。
- 这是一个多分类问题,也许需要一些特殊的处理。所有的特征的数值采用相同的单位,不需要进行尺度的转换。
本文按照下面的步骤实现这个项目:导入数据、概述数据、数据可视化、评估算法、实施预测。
二. 项目实现
1. 导入数据集
先设置一个能够运行的SciPy环境。 具体见: ing
导入数据时为每个字段设定了名字,这有助于后面对数据的展示工作。代码如下:
# 导入数据
filename = 'iris.data.csv'
names = ['separ-length', 'separ-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(filename, names=names)
- 在这里将使用
Pandas来导入数据和对数据进行描述性统计分析,并利用Matplotlib实现数据可视化。- 如上数据在UCI机器学习仓库下载鸢尾花(Iris Flower)数据集(http://archive.ics.uci.edu/ml/datasets/Iris),下载完成后保存在项目的统计目录中。
2. 概述数据 - 查看数据特征
我们从以下几个角度来审查数据,增加对数据的理解,以便选择合适的算法,如下几种维度来选择数据:
- 数据的维度(了解数据集特征)、
- 数据自身、
- 数据特征(行数中位值、最大值、最小值、均值、四分位值)、
- 数据分类的分布情况(各个分类的数据分布是否均衡)
# 显示数据维度
print('数据维度: 行 %s,列 %s' % dataset.shape)
# 查看数据的前10行
print(dataset.head(10))
# 统计描述数据信息
print(dataset.describe())
# 分类分布情况
print(dataset.groupby('class').size())
separ-length separ-width petal-length petal-width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
class
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
可以看到鸢尾花的三个亚属的数据各50条,分布非常平衡。如果数据的分布不平衡时,可能会影响到模型的准确度。(怎么处理数据不均衡的问题ing)
3. 数据可视化
使用单变量图表可以更好地理解每一个特征属性。多变量图表用于理解不同特征属性之间的关系。
# 箱线图
dataset.plot(kind='box', subplots=True, layout=(2, 2), sharex=False, sharey=False)
pyplot.show()
# 直方图
dataset.hist()
pyplot.show()
# 散点矩阵图
scatter_matrix(dataset)
pyplot.show()
- 单变量图表可以显示每一个单独的特征属性,因为每个特征属性都是数字,因此我们可以通过箱线图来展示属性与中位值的离散速度。
- 通过直方图来显示每个特征属性的分布状况。在输出的图表中,我们看到separ-length和separ-width符合高斯分布。
- 多变量图表通过多变量图表可以查看不同特征属性之间的关系。我们通过散点矩阵图来查看每个属性之间的影响关系。

4. 评估算法
这里通过不同的算法来创建模型,并评估它们的准确度,以便找到最合适的算法。
算法评估按照如下来步骤来进行:
- 分离出评估数据集、
- 采用
10折交叉验证来评估算法模型、- 生成6个不同的模型来预测新数据、
- 选择最优模型。
4.1. 分离出评估数据集
模型被创建后需要知道创建的模型是否足够好。在选择算法的过程中会采用统计学方法来评估算法模型。
因为我们更想知道算法
模型对真实数据的准确度如何,所以我们保留一部分数据来评估算法模型。下面将按照80%的数据来训练数据集,20%的数据评估数据集。
# 分离数据集
array = dataset.values
X = array[:, 0:4]
Y = array[:, 4]
validation_size = 0.2
seed = 7
X_train, X_validation, Y_train, Y_validation = \
train_test_split(X, Y, test_size=validation_size, random_state=seed)
现在就分离出了X_train和Y_train用来训练算法创建模型,X_validation和Y_validation在后面会用来验证评估模型。
4.2. 评估模式
在这里将通过10折交叉验证来分离训练数据集,并评估算法模型的准确度。
10折交叉验证是随机地将数据分成10份:9份用来训练模型,1份用来评估算法。后面我们会使用相同的数据对每一种算法进行训练和评估,并从中选择最好的模型。
对任何问题来说,不能仅通过对数据进行审查,就判断出哪个算法最有效。通过前面的图表,发现有些数据特征符合线性分布,所以可以期待算法会得到比较好的结果。(这里的原因是?为什么数据符合线性分布,结果就会好)
接下来评估六种不同的算法:
- 线性回归(LR)。
- 线性判别分析(LDA)。
- K近邻(KNN)。
- 分类与回归树(CART)。
- 贝叶斯分类器(NB)。
- 支持向量机(SVM)。
这个算法列表中包含了线性算法(LR和LDA)和非线性算法(KNN、CART、NB和SVM)。在每次对算法进行评估前都会重新设置随机数的种子,以确保每次对算法的评估都使用相同的数据集(这里怎么理解),保证算法评估的准确性。接下来就创建并评估这六种算法模型。
代码如下:
# 算法审查
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
# 评估算法
results = []
for key in models:
# K折交叉验证器。
# 将数据集拆分为k个连续的折叠(默认情况下不进行洗牌)。
# 然后,每个折叠都被用作一次验证,而剩下的k - 1个折叠形成训练集。
kfold = KFold(n_splits=10, random_state=seed, shuffle=True)
# 通过交叉验证评估得分。
cv_results = cross_val_score(models[key], X_train, Y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
print('%s: %f (%f)' % (key, cv_results.mean(), cv_results.std()))
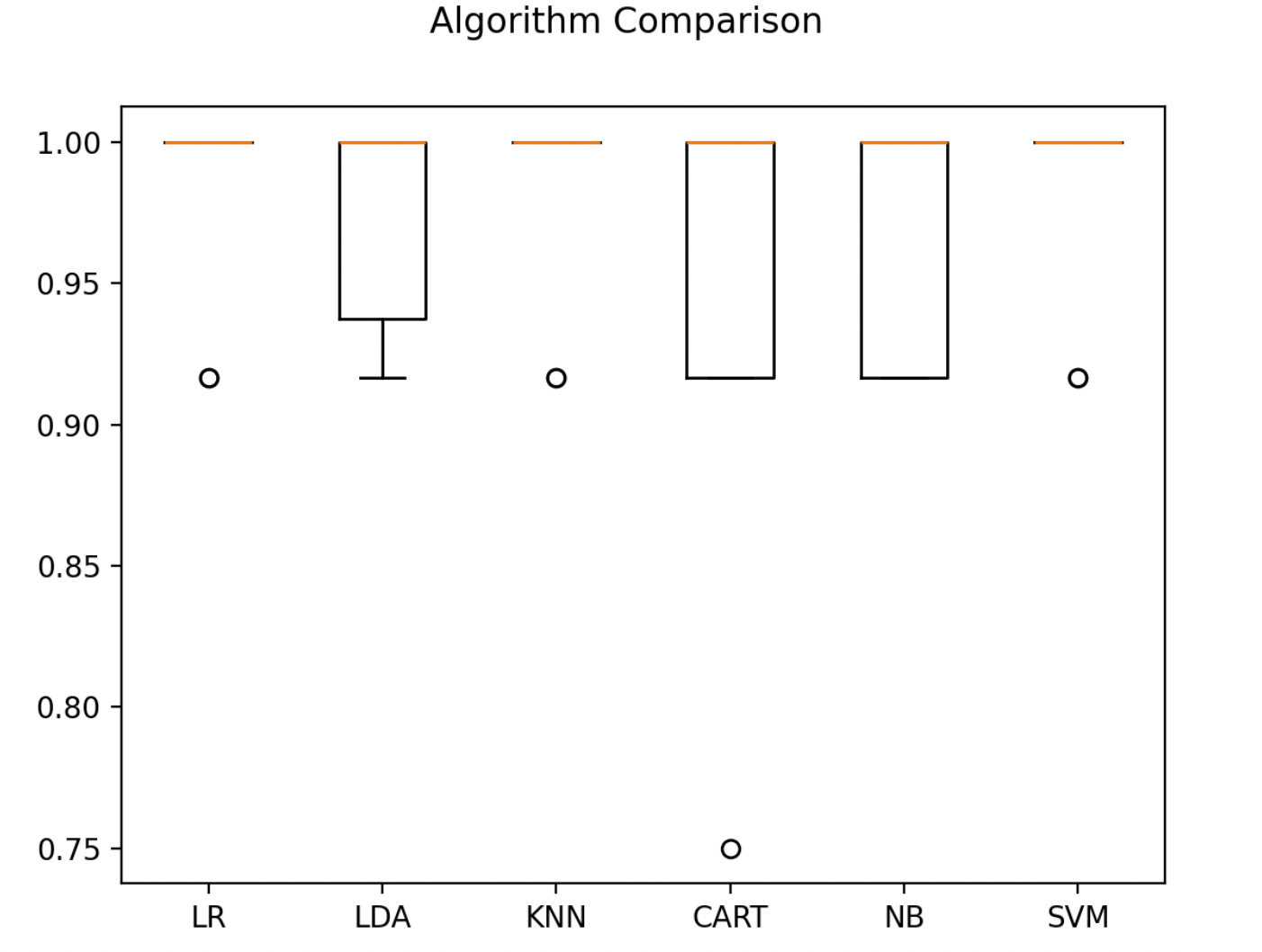
# 箱线图比较算法
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()
4.3. 选择最优模型
通过上面的结果,很容易看出SVM算法具有最高的准确度得分。
LR: 0.966667(0.040825)
LDA: 0.975000(0.038188)
KNN: 0.983333(0.033333)
ART: 0.975000(0.038188)
NB: 0.975000(0.053359)
SVM: 0.991667(0.025000)
这里创建一个箱线图,通过图表来比较算法的评估结果。
5. 模型验证与模型报告
评估的结果显示,支持向量机(SVM)是准确度最高的算法。现在使用预留的评估数据集来验证这个算法模型。这将会对生成的算法模型的准确度有一个更加直观的认识。现在使用全部训练集的数据生成支持向量机(SVM)的算法模型,并用预留的评估数据集给出一个算法模型的报告。代码如下:
# 使用评估数据集评估算法
svm = SVC()
svm.fit(X=X_train, y=Y_train)
predictions = svm.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
执行程序后,看到算法模型的准确度是0.93。通过冲突矩阵看到只有两个数据预测错误。最后还提供了一个包含精确率(precision)、召回率(recall)、F1值(F1-score)等数据的报告。结果如下:
0.933333333333
[[ 7 0 0]
[ 0 10 2]
[ 0 0 11]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 1.00 0.83 0.91 12
Iris-virginica 0.85 1.00 0.92 11
avg / total 0.94 0.93 0.93 30
参考:《机器学习- python实战》- 魏贞原















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











