







Abstract:本文意在讲解语音识别的方法,主要包括语音特征提取(Mel频率倒谱系数的提取), softmax 分类器进行四分类,数据库为京剧。
1.Mel频率倒谱系数的提取
人的听觉系统可以看成一组滤波器族,可以通过这些滤波器得到不同频率的声音,不同的滤波器对不同频率的信号的灵敏程度不一样,Mel频率倒谱系数(MFCC)是一种充分利用人耳感知特性的参数。MFCC和线性频率之间的转换关系如下:
MFCC参数提取如图1所示。该过程分为预加重,分帧,加窗函数,FFT运算,Mel频率滤波器组滤波,取对数能量,DCT求倒谱。

下面来看一段语音信号:
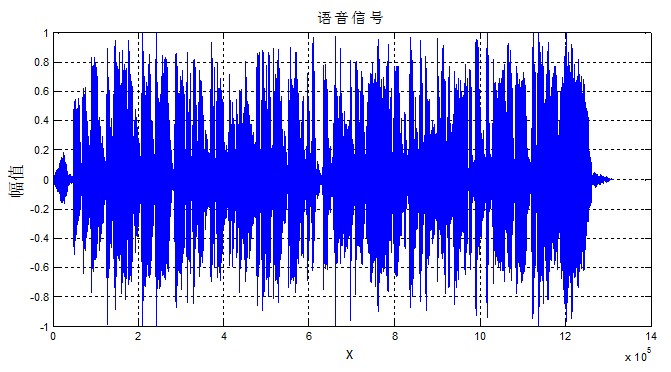
1.1 预加重
预加重是将语音信号
s(n)
通过一格高通滤波器。此高通滤波器的
z
域如下面的形式:
系数其中 a 介于 0.9 和 1.0 之间。若以时域的表达式来表示,预强调后的讯号 s2(n) 为:
这个是为了补偿语音受到发声系统所压抑的高频部分,使高频信号突显出来。
temp=double(signal);
x=filter([1 -0.9],1,temp);可以得到下面经过高通滤波器后的语音信号。
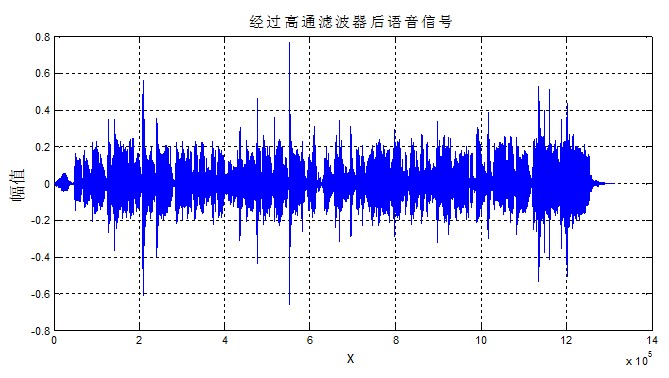
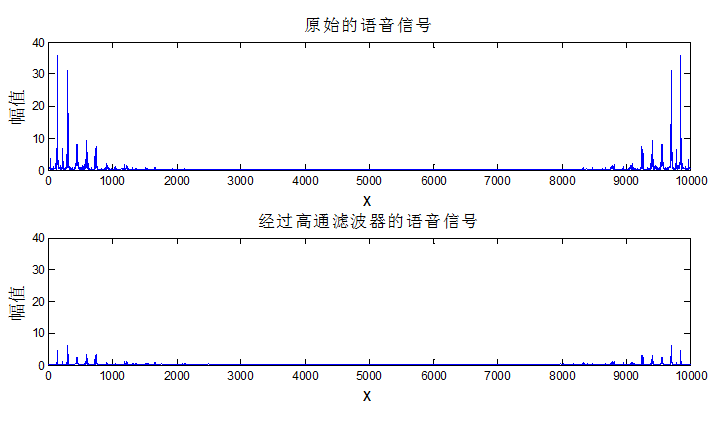
图3为原始语音信号的频谱和经过高通滤波器的语音信号的频谱。
1.2 分帧
分帧是把一段语音信号分成 n 帧来处理,每一帧可以为128,256,512,1024。比如说10240点个语音信号,256个点为一帧,那么就有40帧,但是事实上不是40帧,因为帧与帧之间有交叉重叠的区域,假设非重叠区域为80个点,那么一共就有125帧。
signal=enframe(signal,256,80);1.3 加窗函数
窗函数的目的是为了只处理某一段信号,而屏蔽其他的信号,也叫短时信号处理。加窗函数,可以加hamming窗,hanning窗,blackman窗等窗函数,将每一帧的语音信号乘以窗函数,以增加音框左端和右端的连续性。假设一帧信号为256个点,那么窗函数也为256的点。这里我们采用的是hamming窗。那么得到的加窗语音信号为如下:
W(n) 的形式如下所示:
不同 a 得到不同窗函数。
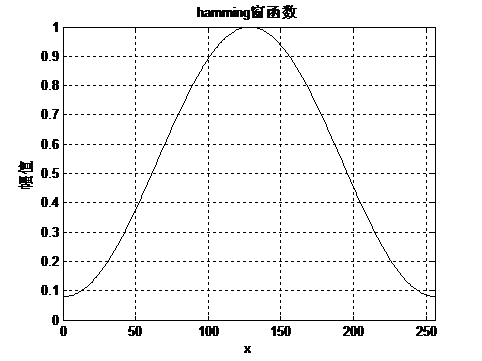
汉明窗如图4所示:
现在我只取前256个语音信号来加窗函数。
s = y' .* hamming(256);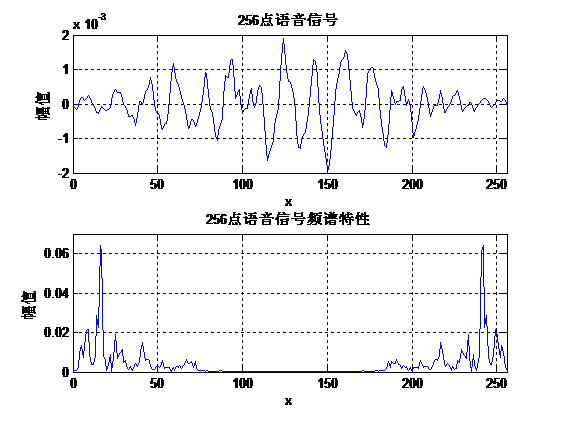
1.5 Mel频率滤波器组
加窗函数后信号通过FFT得到其能量后进入Mel频率滤波器组再进行
Log
对数能量,如下所示:
其中 Mel 系数通过工具箱( mp3_toolbox_v2.0)求得。
bank=melbankm(24,256,44100,0,0.5,'m');
bank=full(bank);
bank=bank/max(bank(:));1.6 DCT求倒谱
对
F(m)
进行离散余弦转换(DCT)变换。我们需要得到DCT的系数。DCT系数可以通过下式求得:
其中 N 为Mel滤波器的个数。
最终得到的倒谱为:
那么 N 帧信号就会得到
1.7 求解差分系数
差分系数用
J
表示,那么:
这样倒谱系数和差分系数就组成了 MFCC 系数。
2.Softmax分类
softmax 分类器适合于多分类,这里不多讲。前面的博文已经有涉及。主要分京剧为4类, happy,angry,sad,grateful .只需要自己准备好输入数据即可。
3.GUI
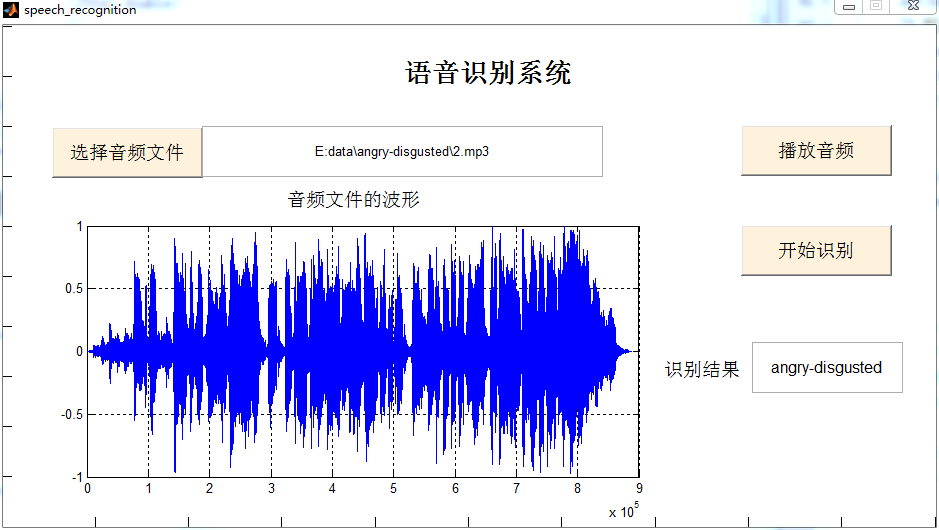
具体程序见资源。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









