







基于深度学习方言语音识别检测系统GUI MATLAB代码
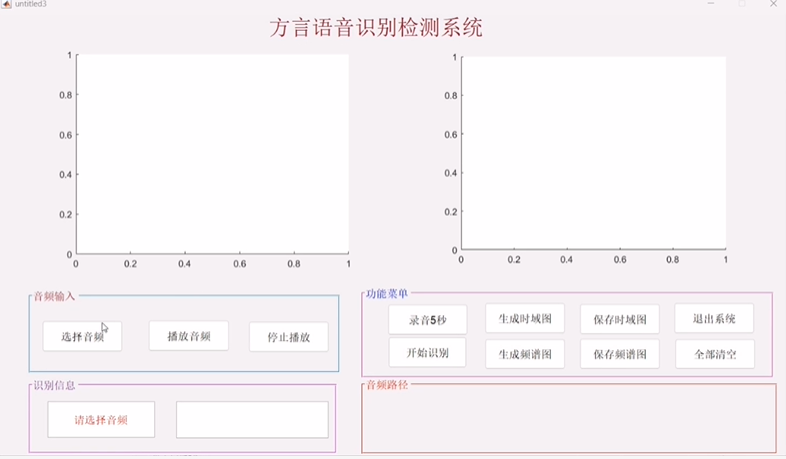
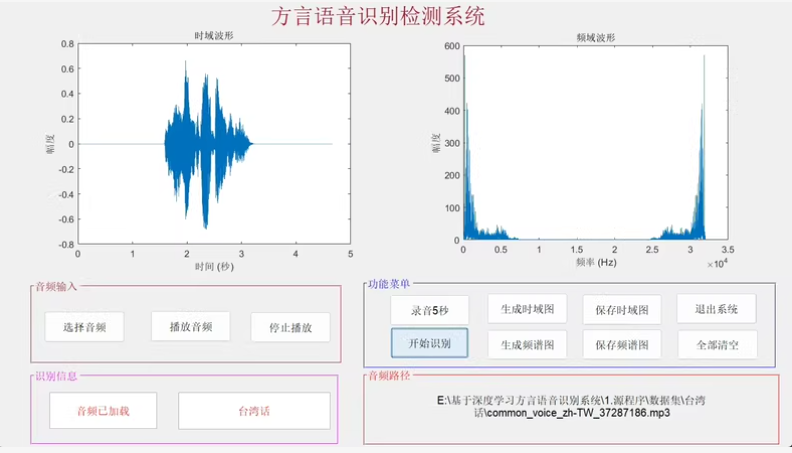
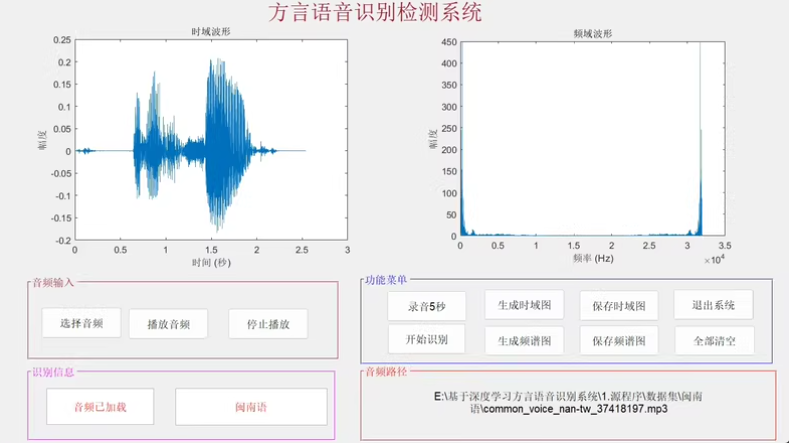
这是基于MATLAB深度学习的方言语音识别检测系统,为多语言识别与语音信号分析设计,系统融合深度学习模型与音频信号处理技术,能够识别7种典型方言语音:朝鲜语、蒙古语、闽南语、普通话、台湾话、香港话和粤语。无论是用于语言学研究、方言数据标注、语音识别教学,还是语音处理算法验证,该系统都能提供直观且智能的支持。
支持从本地导入音频数据进行分析,系统通过基于深度学习的训练模型CNN,对语音信号进行语种特征提取与分类识别,确保多方言之间的高精度判别。
在信号处理层面,系统具备时域图与频谱图生成模块,可自动对语音信号生成可视化图像:时域图反映声音波形变化特性,频谱图则展示语音能量在频率上的分布。这一功能不仅有助于语音信号分析,也为教学与研究提供了直观辅助。图像还可一键保存,便于结果归档或论文展示。
创建一个基于深度学习的方言语音识别系统是一个复杂的任务,涉及到多个步骤,包括数据收集、预处理、模型训练和评估等。下面我将给出一个简化的框架和一些示例代码来帮助你入门。请注意,实际应用中需要根据具体的方言数据集和需求进行调整。
1. 环境设置
首先,确保安装了必要的库。我们将使用Python,并且主要依赖于tensorflow或pytorch这样的深度学习框架,以及用于音频处理的librosa。
pip install tensorflow librosa numpy scipy pandas scikit-learn
或者如果你更倾向于PyTorch:
pip install torch torchaudio librosa numpy scipy pandas scikit-learn
2. 数据准备
你需要一个包含不同方言的音频文件的数据集。每个音频文件应该有一个对应的标签指示其属于哪种方言。
import librosa
import numpy as np
from sklearn.model_selection import train_test_split
def extract_features(file_name):
try:
audio, sample_rate = librosa.load(file_name, res_type='kaiser_fast')
mfccs = librosa.feature.mfcc(y=audio, sr=sample_rate, n_mfcc=40)
mfccsscaled = np.mean(mfccs.T,axis=0)
except Exception as e:
print("Error encountered while parsing file: ", file_name)
return None
return mfccsscaled
# 假设你已经有了一个包含文件路径和对应标签的列表
filenames = [...] # 文件名列表
labels = [...] # 对应的标签
features = []
for filename in filenames:
features.append(extract_features(filename))
X = np.array(features)
y = np.array(labels)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
3. 构建模型
这里我们使用一个简单的神经网络作为例子。你可以根据需要调整网络结构。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
model = Sequential()
model.add(Dense(64, input_dim=X_train.shape[1], activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(np.unique(y)), activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
4. 训练模型
history = model.fit(X_train, y_train, batch_size=32, epochs=50, validation_data=(X_test, y_test))
5. 模型评估
训练完成后,可以对模型进行评估并作出相应的调整。
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print('Accuracy: %f' % (accuracy*100))
这只是一个非常基础的例子,实际的方言语音识别系统可能会更加复杂,包括更多的特征提取方法、更复杂的模型架构(如CNN或RNN),以及详细的超参数调优等。希望这个指南能为你提供一个良好的起点。

















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









