







【2025版-李宏毅机器学习系列课程】https://www.bilibili.com/video/BV1YsqSY8EiW
【深度学习神经网络入门到实战】 https://www.bilibili.com/video/BV1K94y1Z7wn/
因为研究方向内含深度学习的GAN网络,所以挑重点学习了一下,捋清楚了GAN网络的生成器、判别器、损失函数的代码层面的相关内容。
1.李宏毅老师讲的GAN网络
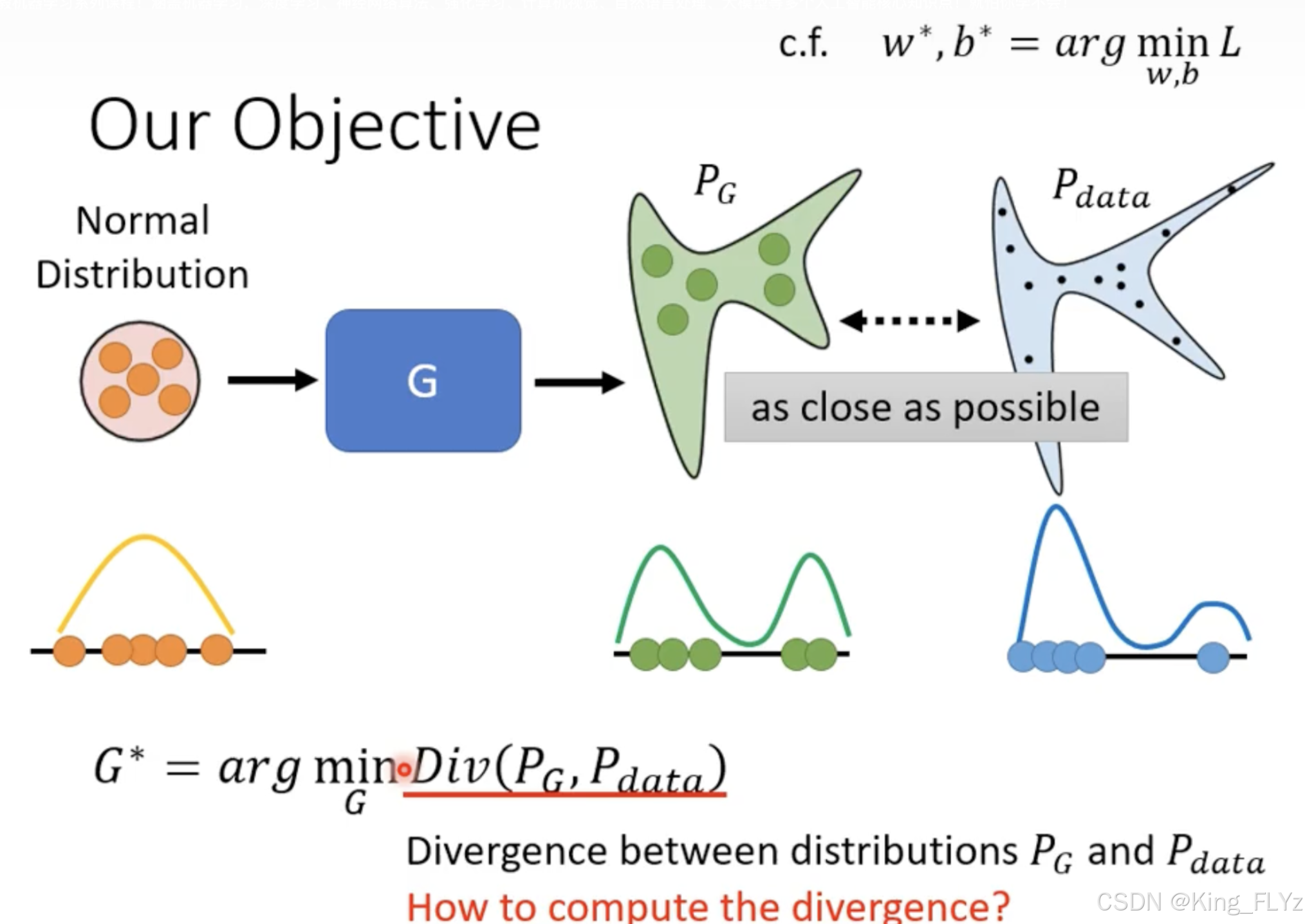
对于生成器(G),生成数据的分布和真实数据的分布之间存在一个Divergence(Div),最终使得这个Div的值越小越好(越小表示两个分布情况越接近)
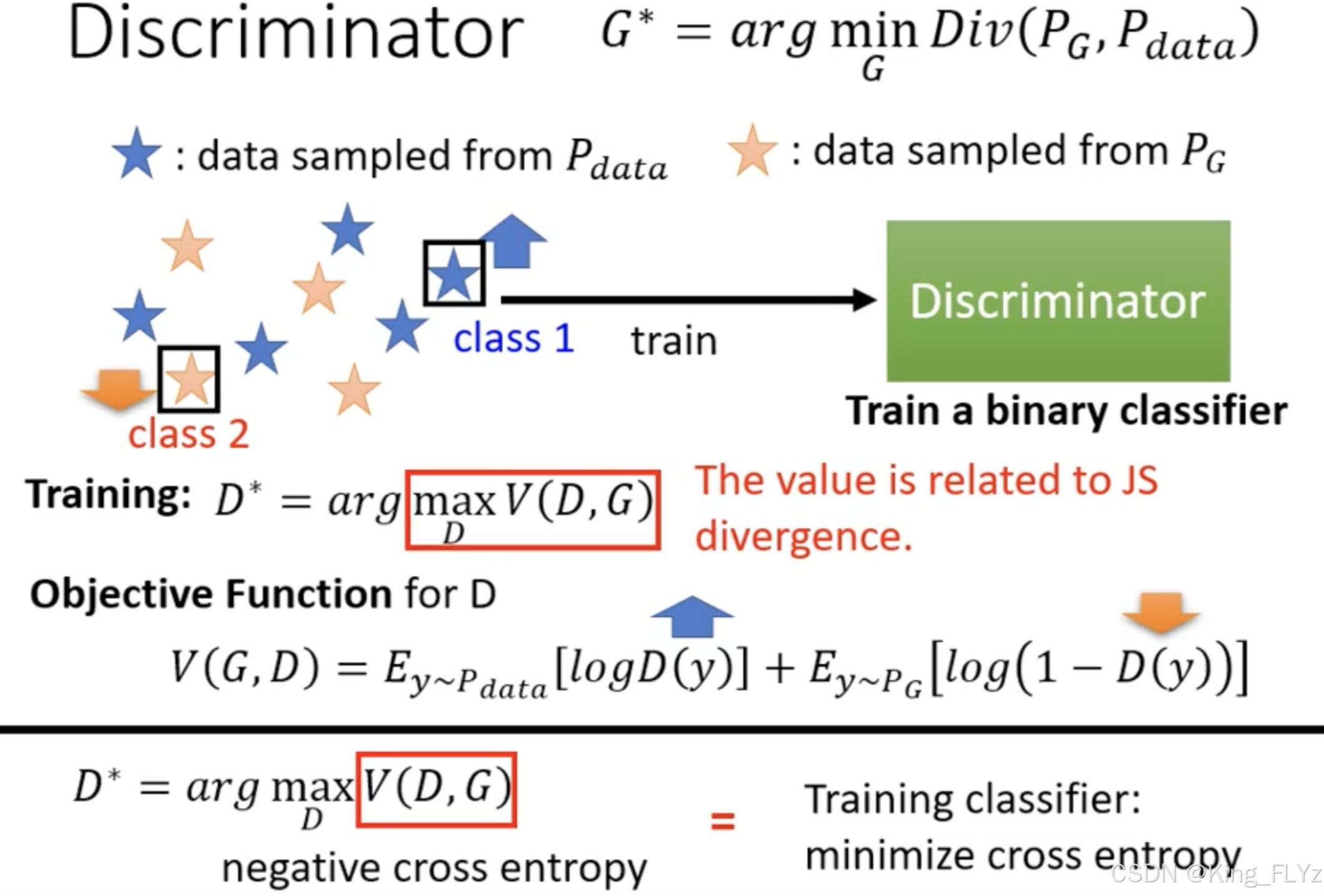
对于判别器(D),训练判别器后,能够使得其辨别真实数据分布的值变大,虚假数据分布的值变小,通过调整模型的参数,使得交叉熵(损失函数)损失最小化。

原始GAN训练困难,使用的是JS散度,P(G)和P(data)如果没有产生过多的样本,重叠的部分会非常少。

原始的二分类器、JS散度会造成一个问题,无法使用其来判断模型训练的好坏,比如说训练一次时候求出来的JS散度是log2,训练10次还是log2,但实际上模型已经变好了,他们好比两条无法相交的直线,只要不重叠,他们的JS散度就一直是log2。

引入瓦斯汀距离向量,可以很好的解决JS散度带来的问题。

D的函数应该保证很平滑(做
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2282
2282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









