







文章目录
PointTransformerV1
ICCV 2021
paper:https://openaccess.thecvf.com/content/ICCV2021/papers/Zhao_Point_Transformer_ICCV_2021_paper.pdf
论文讲解:
这篇文章主要介绍了如何将transformer应用于点云处理。
Introduction
Introduction部分作者有提到关于transformer的优势:“ The transformer family of models is particularly appropriate for point cloud processing because the self-attention operator, which is at the core of transformer networks, is in essence a set operator: it is invariant to permutation and cardinality of the input elements. The application of self-attention to 3D point clouds is therefore quite natural, since point clouds are essentially sets embedded in 3D space.”
他认为transformer适合点云处理,因为其核心的自注意力机制本质上是一种集合操作,具有排列不变性和基数不变性,非常适合处理点云数据。这里解释一下:
- 排列不变性:点云是无序的点集,点的排列顺序并不包含任何有意义的信息。Transformer 的自注意力机制天然具有排列不变性,因为它计算的是所有点对之间的关系,而不依赖于输入的顺序。这种特性使得 Transformer 非常适合处理点云数据
- 基数不变性:点云中的点数量可能变化很大(例如,场景中的稀疏或密集区域)。自注意力机制可以处理任意大小的点集,因此对点数量的变化具有鲁棒性。这种灵活性对于处理真实世界中的点云数据非常重要,因为点云的密度和分辨率往往不一致。
这个基数不变性,我个人认为它确实是transformer具备的,但是这不是独有的,卷积也可以处理不同大小的输入,所以其实卷积也具备基数不变性。如果说transformer与卷积相比在处理点云上的优势,我觉得更多的还是transformer对排列关系的鲁棒性。
另外就是自注意力机制可以捕捉全局上下文信息,而卷积通常只能捕捉局部信息,这与其他领域从卷积发展到transformer的理由一样,点云并无特殊。
Related work
回顾了现有的点云处理方法,并将其分为以下几类:
1、基于投影的网络(Projection-based Networks)
- 多视图投影:将3D点云投影到多个2D图像平面,然后使用2D卷积神经网络(CNN)提取特征,最后通过多视图特征融合生成最终表示。
- 优点:可以利用成熟的2D CNN技术。
- 缺点:投影过程中会丢失几何信息,且对投影平面的选择敏感。
- 代表作:MVCNN(Multi-View CNN)[34]、TangentConv [35]
2、基于体素的网络(Voxel-based Networks)
- 体素化:将3D点云量化为规则的体素网格,然后在体素网格上应用3D卷积。
- 优点:可以利用3D卷积操作。
- 缺点:体素化会导致几何细节丢失,且计算和内存开销较大。
- 代表工作:VoxNet [23]、OctNet [29]
3、基于点的网络(Point-based Networks)
- 直接处理点云:设计能够直接处理点云的深度学习模型,避免了投影或体素化带来的信息损失。
- 优点:保留了点云的几何细节,计算效率较高。
- 缺点:需要设计特殊的操作来处理无序点集。
- 代表工作:
- PointNet [25]:使用点级的MLP和池化操作来聚合特征。
- PointNet++ [27]:在PointNet的基础上引入了层次化结构,增强了对局部几何的敏感性。
- DGCNN [44]:基于图卷积的动态图CNN。
- PointCNN [20]:通过特殊的操作对点云进行重新排序。
- KPConv [37]:基于点云的连续卷积操作。
4、基于图的网络(Graph-based Networks)
- 图结构:将点云表示为图结构,并在图上进行消息传递或图卷积操作。
- 优点:能够捕捉点云中点与点之间的关系。
- 缺点:图结构的构建和计算可能较为复杂。
- 代表工作:
- DGCNN [44]:在k近邻图上进行图卷积。
- PointWeb [55]:在局部邻域内密集连接点。
- SPG [15]:基于超点图的语义分割方法。
5、基于连续卷积的网络(Continuous Convolution Networks)
- 连续卷积:直接在点云上定义卷积操作,避免了体素化或投影。
- 优点:保留了点云的几何信息,适合处理不规则数据。
- 缺点:卷积核的设计和计算可能较为复杂。
- 代表工作:
- PCCN [42]:将卷积核表示为MLP。
- SpiderCNN [49]:使用参数化的多项式函数定义卷积核。
- PointConv [46]:基于输入坐标构造卷积权重。
6、Transformer与自注意力机制(Transformer and Self-Attention)
- 点云中的注意力机制 [48, 21, 50, 17]:一些工作尝试将注意力机制应用于点云处理,但通常是全局注意力,计算开销较大。
Point Transformer
在说本文的方法之前,作者先介绍了两种自注意力机制:
1、scalar attention:这个就是transformer中的标准的缩放点积注意力
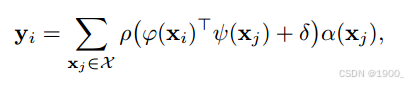
这个公式可能看起来跟平常我们看到的自注意力机制公式有点不一样。
其中 X i X_i Xi 是输入的特征, φ ( ⋅ ) \varphi(·) φ(⋅), ψ ( ⋅ ) \psi(·) ψ(⋅))和 α ( ⋅ ) \alpha(·) α(⋅)分别表示特征变换(比如 MLP),那么对输入特征进行特征变化以后,也就是我们平常看到的transformer中的Q,、K、V
ρ ( ⋅ ) \rho(·) ρ(⋅)表示归一化操作,比如 softmax。
那这样看起来,就跟我们平常看到的transforme公式差不多一样了,区别就是里面还加了一个 δ \delta δ
δ
\delta
δ表示位置编码。
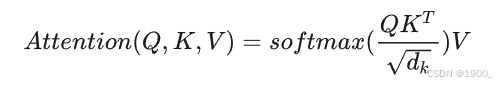
transformer论文中对于位置编码,是独立处理的。没有显式的位置编码函数,因为位置信息是通过独立的位置编码直接添加到输入特征中的。而这里的位置编码特征是嵌入到自注意力机制里面的(为什么这么做,后面作者有解释)
2、vector attention:
刚才说那那种标量注意力,计算得到的注意力权重 Q K T QK^T QKT是一个标量点积。
它有一个弊端,我们把计算过程拆开看就会发现。
注意力分数与Value进行计算的时候,如下图所示
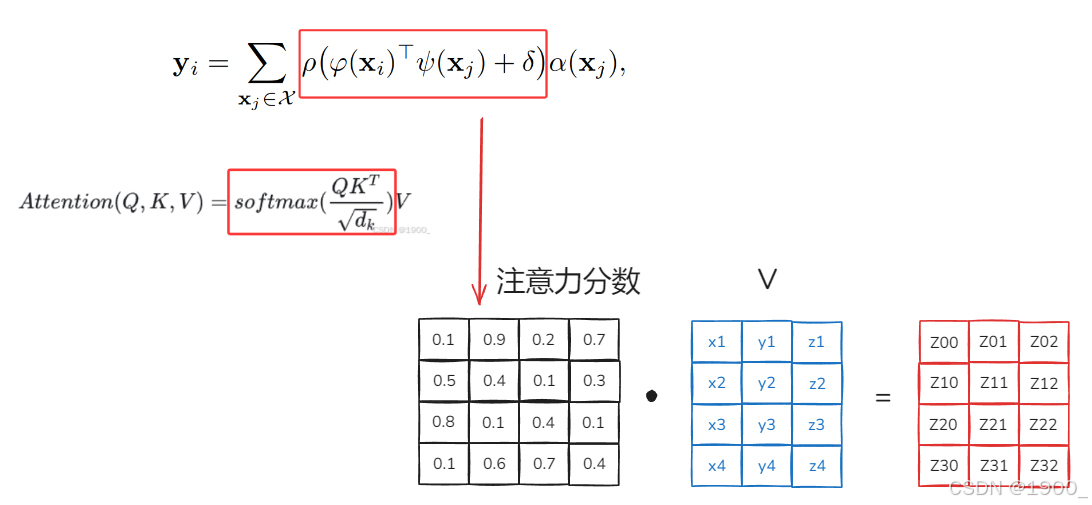
由于我们现在是对点云数据进行计算,所以假设V代表n个点,每个点xyz三个坐标,故是n行3列,注意力权重为nxn
把这个矩阵乘法计算分步骤来看
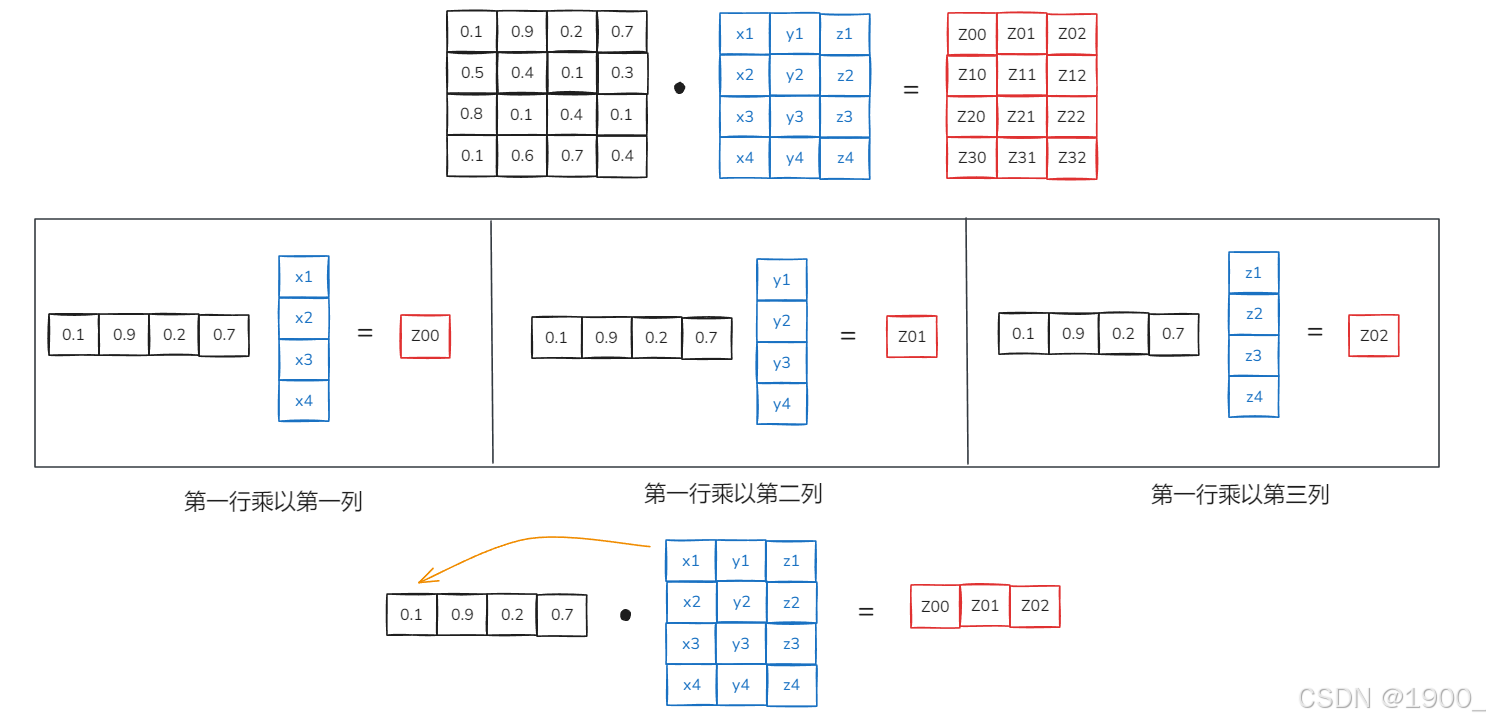
你就会发现,在这个计算过程中,V中的第一个点(第一行xyz),只和权重0.1进行了相乘,换句话说,这个点只赋予了一个权重,就是0.1
点向量的三个通道没有区别,都直接乘以同一个权重值
也就是说:所有特征通道共享相同的注意力权重。
因此提出了另一种自注意力机制—向量注意力,其目的是为每个特征通道计算独立的注意力权重,而不是共享一个全局的标量权重。(其实不用了解前面那种注意力机制,现在基本上都用第二种方式)
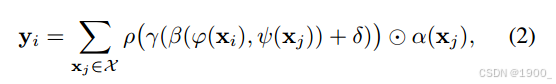
如(2)式所示这里计算出来的注意力权重是NxD的,因此与Value是一样的。所以不用矩阵乘法,而是直接对应位置相乘。因此一个点的特征向量的每一个元素获得的权重是不相同的,这就是所谓的向量注意力。
本文就采用了向量注意力的方式来设计注意力层,公式如下:
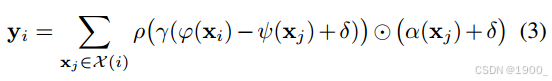
式中的
X
(
i
)
X(i)
X(i)是点
X
i
X_i
Xi的局部邻域(根据k-最近邻(KNN)选定)。
对于一个点 X ( i ) X(i) X(i),选出他的k近邻后,每一个邻居 X j X_j Xj都与 X i X_i Xi进行一次向量注意力计算,最终将j个向量自注意力求和,就是输出特征 y i y_i yi。
在最内层,使用的是减法,表示距离关系。
这就是本文设计的自注意力机制。
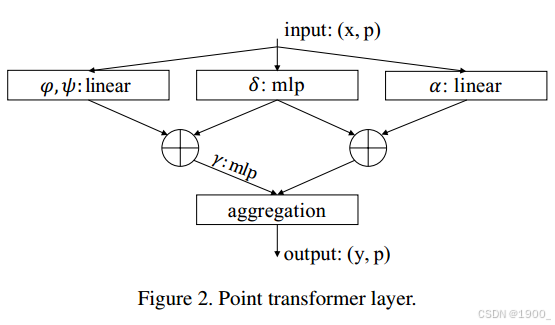
Transformer中作者指出了position coding可以通过两种方式得到,一种是通过可训练的网络得到,另一种则是按照给定的公式计算得到。transformer采用了后者,即传统的正余弦编码方案。
本文中,作者解释由于3D点云本身的相对位置关系就可以作为很好的编码,因此采取前一种方式。
在本文中,位置编码是基于点的相对位置计算的,并通过一个可训练的MLP进行映射。(就是做减法然后过一个MLP)
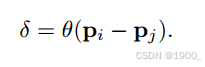
这种相对位置编码的优势:
1、能够直接捕捉点与点之间的几何关系(如距离、方向等),从而增强模型对局部结构的感知能力。
2、可训练性:通过使用可训练的MLP,位置编码可以适应点云数据的特性,并在训练过程中优化。
本文的Point Transformer中,位置编码被同时添加到注意力生成分支和特征变换分支中。

把这个注意力层,前后各加一个线形层,外加一个残差连接。就是一个transformer block
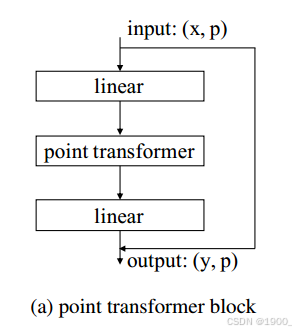
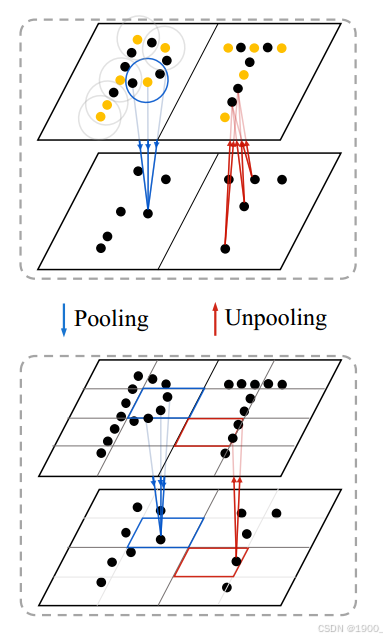
这是本文设计的上采样和下采样模块
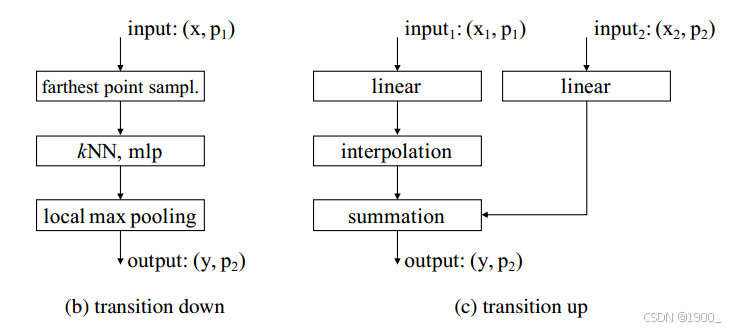
对于分割任务和分类任务作者设计了两个输出部分:
对于分类任务,不包含上采样部分,在经过四次下采样,将点云分辨率减小到N/256之后,直接执行全局平均池化,得到一个长度为512的向量,这就是经过之前point transformer block和transition down之后提取到的点云全局特征向量,最终将这个特征向量输入到最后的MLP中,输出分类标签。
对于分割任务,经过上下采样过程后,得到尺寸为N×32的矩阵,矩阵的一个行向量都是一个点的特征向量,一共包含N个点的特征向量。将这个矩阵输入到最后的MLP中,输出为每一个点的分割标签
参考:https://zhuanlan.zhihu.com/p/681682833
PointTransformerV2
NeurIPS 2022
paper:https://arxiv.org/pdf/2210.05666
code:https://github.com/Pointcept/PointTransformerV2
对比V1有三处改进:
1、分组向量注意力GVA
在V1中使用了向量注意力,矩阵Value中每一个向量的所有通道的权重值是不同的,这样就导致了参数的增加。
标量注意力的方法虽然参数少,但是可能无法获得向量中通道之间的关系,向量注意力的方法却可以关注到向量中通道之间的关系,调整每个通道的权重,但随之而来的问题就是参数数量的大量增加。
所以V2提出了分组的方法。将Value矩阵中每个向量的通道均匀的分成 g 组(1 ≤ g ≤ c),并且在每组内共享同一个权重参数。这样减少计算量增加效率。
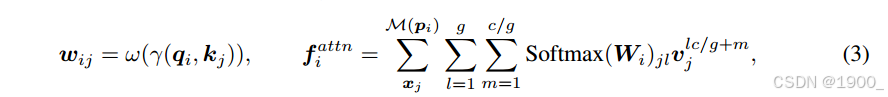
2、位置编码
比原来多了一个这个
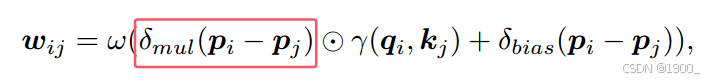
由于分组向量注意力限制了注意力机制的容量,作者通过将一个额外的乘子
δ
m
u
l
\delta_{mul}
δmul 添加到关系向量中来加强位置编码,该乘子侧重于学习复杂的点云位置关系
3、分区池化
之前的方法在采样阶段,使用最远点采样(Farthest Point Sampling, FPS)或网格采样(Grid Sampling)来为后续编码阶段保留采样点。
对于每个采样点,执行邻域查询以从邻近点聚合信息。
在这些基于采样的池化过程中,查询点集在空间上是不对称的,因为每个查询集之间的信息密度和重叠是不可控的。
为此,作者提出基于分区的池化方法。
池化的时候,将整个空间划分为相同大小且不重叠的区域,对每个区域内点的信息进行MaxPooling,采样点的坐标为区域内所有点的平均坐标。
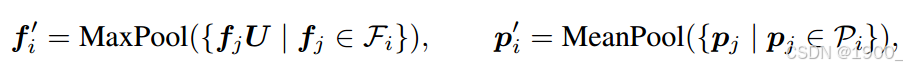
上采样的时候,直接复制
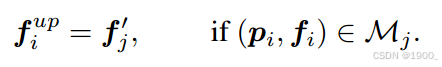
其网络的整体结构,跟V1大致一样。主要的改进点就是这三个地方。
PointTransformerV3
CVPR 2024
paper:https://arxiv.org/pdf/2312.10035
code:https://github.com/Pointcept/PointTransformerV3
V3没有继续在注意力机制方面寻求创新。而是专注于保持点云背景下准确性和效率之间的平衡。
作者提出v3的思想来源(FlatFormer、OctFormer):
Zhijian Liu, Xinyu Yang, Haotian Tang, Shang Yang, and Song Han. Flatformer: Flattened window attention for ef f icient point cloud transformer. In CVPR, 2023.
具体来说,它们开创了一种与传统点云处理方法不同的路径。这些方法通过将无结构、不规则的点云数据根据特定的模式进行排序,转换成结构化的序列,同时保留了空间近邻性。
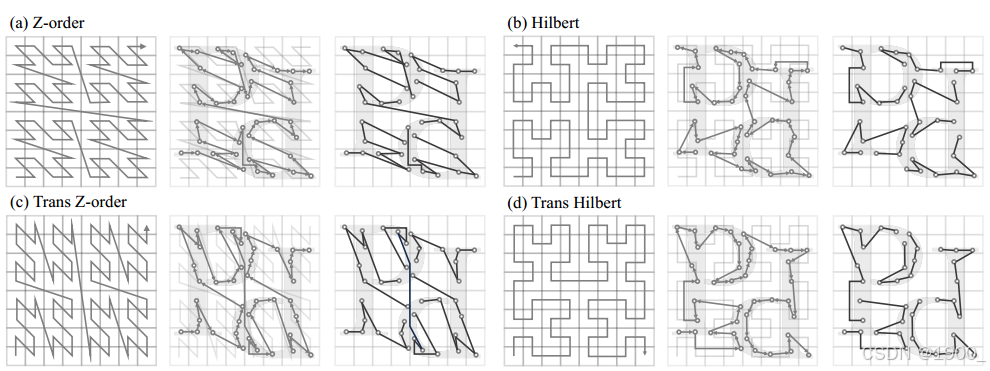
1、点云序列化–空间填充曲线
比如Z-order序列化(Z-ordering)是一种用于多维数据的方法,它可以将多维空间中的点映射到一维空间中,同时保持点之间的相对邻近性。在处理点云数据时,Z-order序列化可以有效地组织数据以优化存储和访问。
比如Hilbert曲线,由David Hilbert提出。与Z-order曲线相比,Hilbert曲线更好地保持了空间中点之间的邻近关系,这意味着如果两个点在空间中是相邻的,那么在通过Hilbert曲线映射到一维序列后,这两个点仍然会保持较近的位置。Hilbert曲线通过迭代生成,每一次迭代都会增加曲线的细节和复杂度。它在多种应用中被用来改善数据的局部性,从而提高存储和查询效率。
2、序列化编码
将点的位置转换为一个整数序列,反映其在给定空间填充曲线中的顺序。
具体来说,通过将点的位置投影到一个离散空间,并使用空间填充曲线的逆映射
φ
−
1
φ^{-1}
φ−1来生成序列化代码

3、序列化注意力
先前的point transformers采用了向量注意力vector attention是因为缩放点积注意力有一些缺点。
现在使用了序列化的点云数据后,点云序列化的结构化特性,让作者选择重新审视并采用高效的窗口window和点积注意力机制作为基础方法。
将点分组为不重叠patch并在每个单独patch内执行注意力的机制。
这个分组是根据序列化的点云数据排序后分组的。如下图所示。八个点一组,分组的时候按照顺序,0-7,8-15等等
最后的不足八个,则进行填充。
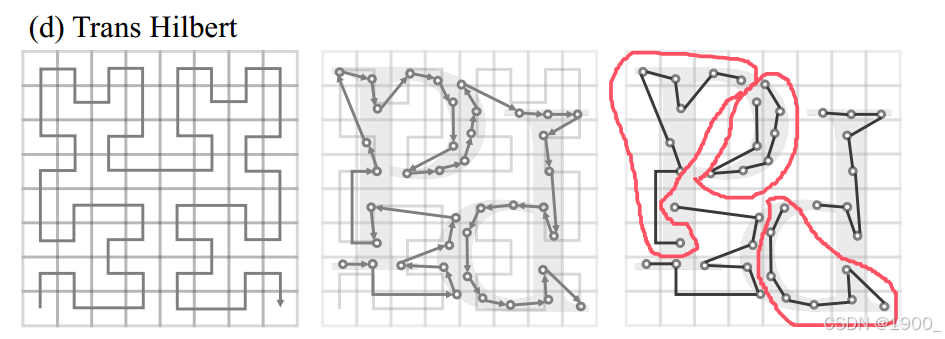
与KNN相比,这种方法可能会牺牲一些邻居搜索精度,但效率和可扩展性的提高远远超过邻域精度的微小损失
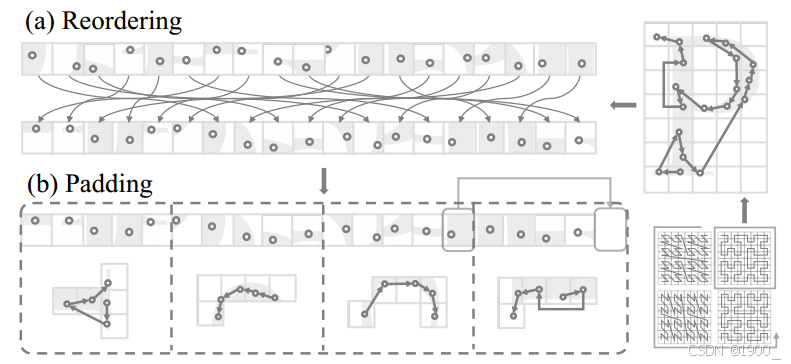
(a)根据从特定序列化模式派生的顺序对点云进行重新排序。 (b)通过借用相邻patch的点来填充点云序列,以确保它可以被指定的patch大小整除。
4、Patch之间的交互 Patch interaction
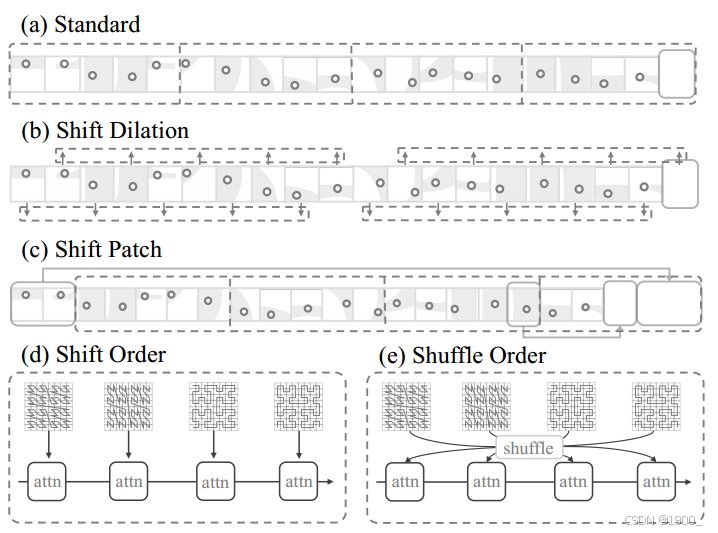
Shift Dilation策略通过在序列化点云中以固定步长移动补丁来实现扩张效果。这种方法类似于卷积神经网络中的膨胀卷积,可以增加模型的感受野,使其能够捕捉到更广泛的空间关系。
Shift Patch策略受到图像处理中窗口滑动注意力机制的启发。在这种策略中,补丁的位置在序列化点云中进行位移,以最大化不同补丁之间的交互。
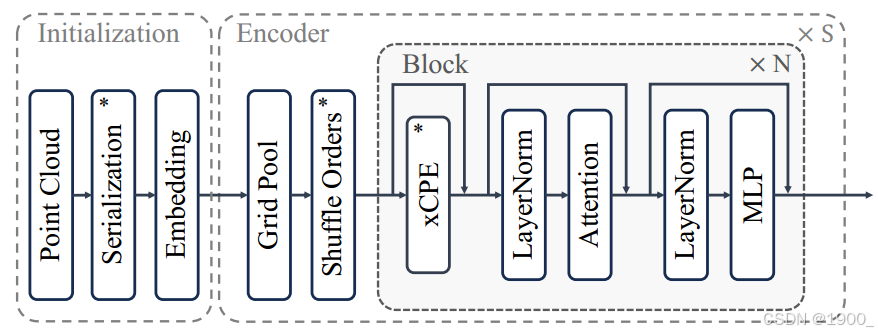
5、增强条件位置编码
xCPE,它通过在注意力层之前直接插入一个稀疏卷积层来实现,该层具有跳跃连接(skip connection)。
整体网络结构如下所示:


















 8748
8748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











