









目录

各代比较
Point Transformer v1
背景: 初始的Point Transformer被设计用于3D点云处理,借鉴了自注意力机制(self-attention)在自然语言处理和图像分析中的成功应用。
核心创新: 引入了针对点云的自注意力层,构建了基于这些层的网络,用于执行语义场景分割、物体部分分割和物体分类等任务。这种设计使得网络能够直接在点云上操作,而无需将其转换为其他格式(如体素或图像)。
主要贡献: 设计了一种新颖的点转换器(Point Transformer)层,这个层对点云处理具有天然的适应性。通过大量实验验证了该方法在多个3D深度学习任务上的有效性,尤其是在大规模语义分割任务上,首次实现了70%以上的mIoU。
Point Transformer v2
改进: v2版本在v1的基础上进行了改进,引入了分组向量注意力(grouped vector attention)和基于分区的池化机制,以提高处理效率和模型性能。
特点: 通过对点云进行分组处理和引入更精细的注意力机制,v2版本旨在更好地捕捉局部几何结构和特征,同时保持对全局上下文的敏感度。
结果: 在一系列标准数据集上的实验表明,v2版本相较于v1有了进一步的性能提升,特别是在处理大规模点云数据时的效率和精度方面。
Point Transformer v3
主题: "更简单,更快,更强大",v3版本在保持高性能的同时,着重优化了模型的简洁性和计算效率。
核心改进:
简化设计: v3版本对Point Transformer层进行了简化,减少了模型复杂度,提高了训练和推理速度。
效率提升: 引入了新的优化算法和技术,如高效的点采样和特征提取方法,显著提升了处理速度。
性能增强: 即便在简化模型结构的同时,v3版本通过更加精细的注意力机制和改进的网络架构,依然实现了在多个3D点云处理任务上的性能提升。
作者思想来源
更强的性能、更低的内存消耗、更广泛情况下的适用性。
相比于前两代,v3考虑更多的是简单性和准确性,与之前的v2相比速度提高3倍,内存效率提升10倍。
作者认为,3D点云相对于2D视觉发展缓慢的主要原因是不同邻域的点云数据大小和多样性有显著差别,这使得点云网络在速度和精度之间无法权衡。
3D学习的最新进展:Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, and Hengshuang Zhao. Towards large scale 3d representation learning with multi-dataset point prompt training. arXiv:2308.09718, 2023.
作者提出v3的思想来源(FlatFormer、OctFormer):
Zhijian Liu, Xinyu Yang, Haotian Tang, Shang Yang, and Song Han. Flatformer: Flattened window attention for ef f icient point cloud transformer. In CVPR, 2023.
Peng-Shuai Wang. Octformer: Octree-based transformers for 3D point clouds. SIGGRAPH, 2023.
具体来说,它们开创了一种与传统点云处理方法不同的路径。这些方法通过将无结构、不规则的点云数据根据特定的模式进行排序,转换成结构化的序列,同时保留了空间近邻性。
具体来讲
OctFormer:利用八叉树(octree)结构对点云进行序列化,类似于z-order(一种空间填充曲线)。八叉树是一种常用于3D数据索引和压缩的树形数据结构,可以有效地表示3D空间中的点云数据。然而,这种方法的可扩展性受到八叉树结构本身的限制。
FlatFormer:与OctFormer不同,FlatFormer采用基于窗口的排序策略对点云中的“点柱”(point pillars)进行分组,这类似于窗口分区技术,然而这种设计的可扩展性方面存在限制。
(这些工作标志着点云序列化方法的开始)
由于点云数据的非结构化特征,点云变换器在满足排列不变性时遇到了缩放方面的挑战(之前的研究通过KNN来表示局部结构,但造成了显著的计算负担)。
点云的位置编码长通过计算两点之间的欧几里得距离,并通过学习来完成位置嵌入(计算效率底下的另一个原因)。
Point Transformer v2各部分用时占比如下所示:
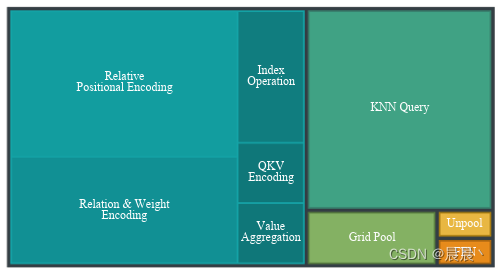
为此,作者受OctFormer和FlatFormer的启发,摆脱了将点云视为无序集的传统范式。通过将点云序列化为结构格式来打破排列不变性的约束。(设计的切入点)
Point Transformer V3
以缩放原理为指导,强调简单和速度。
点云序列化
空间填充曲线(space-filling curves)
一种特殊类型的曲线,其独特之处在于能够在有限的空间内如果连续且不重复的路径覆盖每一个点,即尽管它们是一维曲线,但能够填满多维空间(例如二维平面、三维空间)。(可以用这种曲线将多维数据映射到一维,同时保持原有数据点之间的空间邻近性)
空间填充曲线可以被定义为一个双射函数𝜑:ℤ↦ℤ𝑛,其中𝑛表示空间的维数(点云背景下为3,也可以扩展为更高维)。
作者以两条代表性的空间填充曲线为中心:Z-阶曲线和希尔伯特曲线。
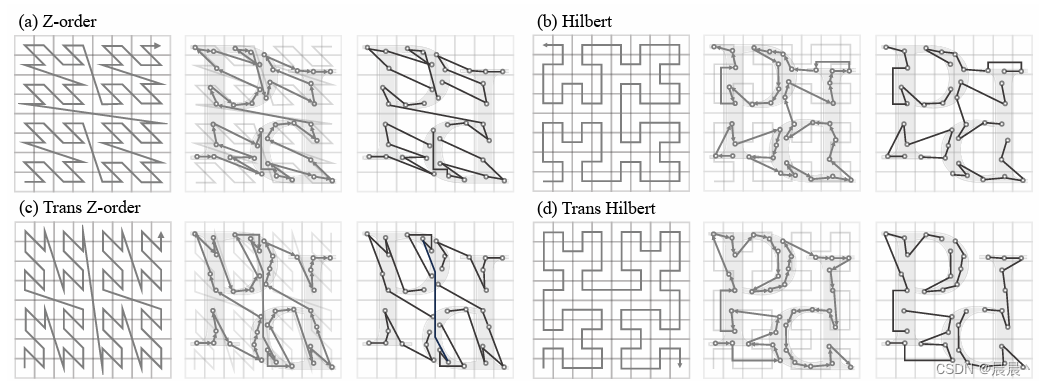
从左至右依次时空间填充曲线、序列化编码、按顺序分组形成单个patch。
Z-order曲线(Z阶曲线)- (a)
Z-order曲线,又称为Lebesgue曲线,是一种简单的空间填充曲线,通过迭代过程生成。它将空间分割成四分之一(二维)或八分之一(三维),然后按照特定的顺序(形似字母Z)连接这些区域中的点,从而生成一条连续的曲线。Z-order曲线的一个主要优点是计算简单,容易实现,但它相对于其他曲线在保持空间近邻性方面效果较差。
Hilbert曲线 - (b)
Hilbert曲线是另一种著名的空间填充曲线,由David Hilbert提出。与Z-order曲线相比,Hilbert曲线更好地保持了空间中点之间的邻近关系,这意味着如果两个点在空间中是相邻的,那么在通过Hilbert曲线映射到一维序列后,这两个点仍然会保持较近的位置。Hilbert曲线通过迭代生成,每一次迭代都会增加曲线的细节和复杂度。它在多种应用中被用来改善数据的局部性,从而提高存储和查询效率。
标准空间填充曲线通过分别沿着x、y和z轴进行顺序遍历来处理3D空间。作者将标准空间填充曲线和上述两种曲线相结合,提出了变体(Trans)Z-order和Hilbert曲线(如(c)和(d)所示)。
序列化编码


整个序列化编码的过程可以表示如下:
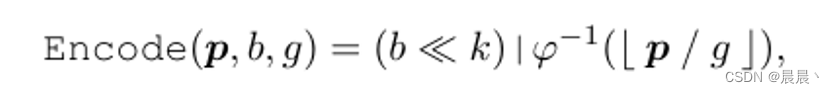
其中,<<可以表示为左位移。|表示或运算。
点云的序列化编码由代码序列化排序编码完成(排序遵循了空间排序的定义,通过空间填充曲线以一种有效的方式重新排列了点 - 空间中相邻的点在数据结构中也是接近的)。
在v3中,不会对序列的点重新进行排序(物理上),而是记录编码程序生成新的映射序列。
序列的关注
在图像Transformer中,由于像素数据结构化和规整的网格,因此更倾向于窗口和点积注意力机制。这些方法利用图像数据固定的空间关系,允许高效可扩展的本地化处理。
当面对非结构化的点云时,这种优势就消失了。为了适应这种情况,先前的点云Transformer引入了邻域注意力机制来构建大小均匀的注意力核来提高模型对空间关系复杂的点云数据的收敛性。
v3中,作者采用窗口和点积注意力机制作为基础(先前对点的处理中都是用向量注意力机制,以窗口注意力为灵感),提出patch注意力。
补丁注意力(补丁分组,相当于之间的邻域分组)--主要涉及点云序列化后的简单分组和填充
将点分组到不重叠的patch中,并在每个patch中执行注意力机制(对于patch内点不足的情况,作者从相邻的patch中借用点来填充patch)。
patch注意力的有效性主要依赖两个设计:patch分组和patch交互。
补丁分组
将点云分组为patch的一些前期探索:
Zhijian Liu, Xinyu Yang, Haotian Tang, Shang Yang, and Song Han. Flatformer: Flattened window attention for ef f icient point cloud transformer. In CVPR, 2023. 2, 3, 5, 8, 10
Peng-Shuai Wang. Octformer: Octree-based transformers for 3D point clouds. SIGGRAPH, 2023. 2, 3, 5, 6, 7, 8, 10, 11(也即是v3的主要思想来源)
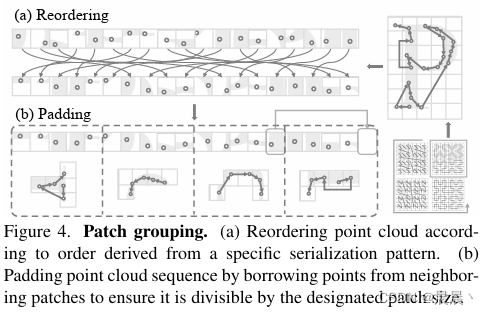
在点云序列化之后,接下来的步骤是将序列化后的点云分组成不重叠的补丁。这一过程涉及按照序列化后的顺序将点云简单分组,并在必要时进行填充以确保每个补丁具有相同数量的点(例如最后一个patch不够填充时,从周围的patch填充点作为补充)。这种分组策略与序列化模式紧密结合,设计为在保持空间邻近性的同时,通过增加补丁大小来扩展注意力机制的接受范围。
空间填充曲线、序列化编码、点云排序、分组并填充的四个步骤如下:
补丁交互
不同patch中的点云的交互对模型继承整个点云的信息至关重要。不同patch之间的交互可以克服非重叠结构的局限性。作者提出了如下所述的patch交互设计:
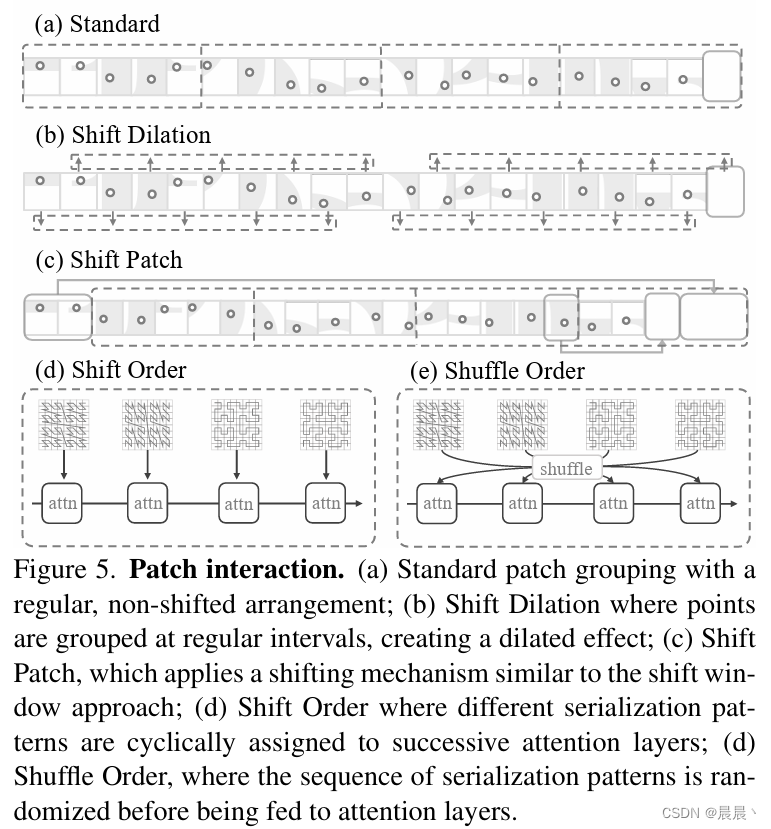
1、移位膨胀(Shift Dilation):patch分组策略为在序列化的点云上错开一个特定步骤,有效地将模型的接受野扩展到邻近点之外(在序列化点云中以特定步长交错分组点云南,扩展模型的感知范围 -- 允许模型捕捉更广泛的空间)。
Peng-Shuai Wang. Octformer: Octree-based transformers for 3D point clouds. SIGGRAPH, 2023. 2, 3, 5, 6, 7, 8, 10, 11
2、移位补丁(Shift Patch):受移动窗口的启发,在序列化点云中对补丁进行移位操作(最大限度提高了补丁之间的相互作用)。
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin trans former: Hierarchical vision transformer using shifted win dows. ICCV, 2021. 5
3、顺序移位(Shift Order):在点云数据的序列化顺序在注意力块之间动态变化(作者结合这种技术和点云序列化方式,用于放置模型过度拟合到单一模式)。
4、顺序洗牌(Shuffle Order):基于3,引入对序列化顺序的随机排列(在将顺序化序列送入注意力层前,引入随机打乱的步骤,从而增强模型对不同空间关系的理解和泛化能力 -- 使模型的每个注意力层都能以一种随机选择的序列化模式来处理点云数据)。 - 作者的主要使用方式
位置编码
传统的点云Transformer常采用相对位置编码(Relative Positional Encoding,RPE)。
RPE专注于元素之间的相对距离或位置差异,而不是它们在序列中的绝对位置。由于Transformer的自注意力(Self-Attention)机制本身是位置不变的(即对输入序列重新排序,自注意力层的输出也会以相同方式重新排列输出。若不考虑元素的相对位置,Transformer则无法理解序列的顺序意义。-- 可详细参考Transformer的正余弦位置编码)
作者认为,PRE是低效且复杂的。为此,作者认为更有效的选择是:条件位置编码(Conditional Positional Encoding,CPE)。
XiangxiangChu, Zhi Tian, BoZhang, XinlongWang, XiaolinWei, HuaxiaXia, andChunhua Shen. Con ditional positional encodings for vision transformers. arXiv:2102.10882,2021.6
Peng-Shuai Wang. Octformer: Octree-based transformers for 3D point clouds. SIGGRAPH, 2023. 2, 3, 5, 6, 7, 8, 10, 11
通过基于深度卷积的八叉树实现。
Peng-Shuai Wang, Yang Liu, Yu-Xiao Guo, Chun-Yu Sun, and Xin Tong. O-CNN: Octree-based convolutional neural networks for 3D shape analysis. SIGGRAPH, 36(4), 2017. 2, 6
然而单一的CPE并不足以达到峰值性能(即使与RPE结合使用,效果也不是很理想)。
为此,作者提出一种增强的条件位置编码(Enhanced Conditional Positional Encoding,xCPE)。通过在注意力层之前直接添加一个带有跳过连接的稀疏卷积层来实现。
设计关键在通过系数卷积层直接作用在注意力层前(没有在注意力机制中引入额外的相关位置计算)。
系数卷积层在保持输入点的结构同时,有效地为每个点引入了其在空间中的位置信息。
网络的整体架构


















 2618
2618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











