







《Point Transformer V2:分组向量注意力和基于分区的池化》的理解
PT-V2这篇文章主要基于PTv1进行了升级。Ptv1是PointTransformer的缩写。
作者认为PTv1存在过拟合。PTv1的模型深度和通道数量的增加,权重编码参数的数量也急剧增加,导致严重的过拟合,限制了模型深度。
作者在Attention算子 与 池化策略上进行了改进。
首先是 改进Attention算子:
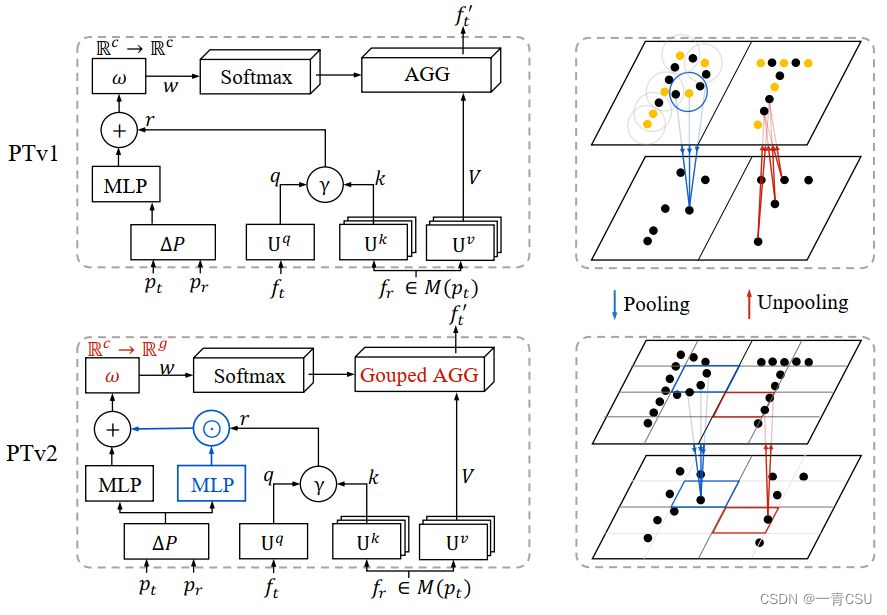
减少数据参数,利用分组向量注意公式改进Attention算子:为了减少参数,作者通过数学机理的操作进行简化注意力机制,减少了参数,增加了模型的精度。分组向量注意公式(GVC,grouped vector attention),其中向量注意被分成具有共享向量注意权重的组。如下图左下红色部分。
在上步基础上,增加位置编码改进Attention算子:PTv1中向量注意的泛化限制,在向量注意中增加更多的位置编码能力无助于提高性能。通过GVC,参数的减少,提升了模型的可用性。为了更充分利用三维点信息,在分组向量注意限制注意机制容量的情况下,通过对关系向量增加乘子mul(pi-pj),哈达玛积乘积来加强位置编码,专注于学习复杂点云位置关系。如下图左上红色部分。
评论:这块部分应该是一个典型的可插入模块,被封装成具体函数,易插入。点云模型参数的过拟合环节是一个问题。作者是意识到这个问题后设计具有共享向量注意权重的方法,并通过数学实现需要较强的数学功底与transformer的透彻理解,具有难度。在此基础上,作者又通过增加哈达玛积乘积位置编码乘数,是一个较小的创新,易于实现。
改进池化策略:
点的不规则、非均匀的空间分布对点云处理的池化模块构成了重大挑战。以前的点云池方法依赖于采样方法(如最远点采样fps[Ptv1]或网格采样[KPCONV])和邻居查询方法(如kNN或半径查询)的组合,每个点的查询集之间的信息密度和重叠是不可控制的,这是耗时的和空间对齐不良好的。为了克服这一问题,直接融合同一分区内的点。如下图右上:PTv1中基于采样的pooling和基于插值的unpooling。右下:PTv2中基于分区的池化和解池(第3.4节)。在池化Pooling时,其采取一种格网化的思想将空间分隔成不重叠的分区,来获取特征。在UnPooling时,将点特征映射到同一子集中的所有点进行融合。
评论:改进池化策略时针对已有的采样和邻居查询策略存在的耗时的和空间对齐问题的改进。策略更加简单,但是结果是有效的。这是一种新的池化策略,类似与3D的卷积。















 7839
7839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









