






前言
源码学习资源:YOLOV5预处理和后处理,源码详细分析-CSDN博客
网络学习资源:YOLOv5网络详解_yolov5网络结构详解-CSDN博客
YOLOv5-v6.0学习笔记_yolov5的置信度损失公式-CSDN博客
本文为个人学习,整合各路大佬的资料进行V5-6.0版本的网络分析,在开始学习之前最好先去学习YOLO前面几个系列,B站有大佬讲了V1-V3:【精读AI论文】YOLO V1目标检测,看我就够了_哔哩哔哩_bilibili
YOLOV5网络分析
分析一个网络是如何的进行的,先找网络图最为直观,一目了然的知道主干、颈部、头部网络是如何进行的,下面是YOLOV5的网络图:
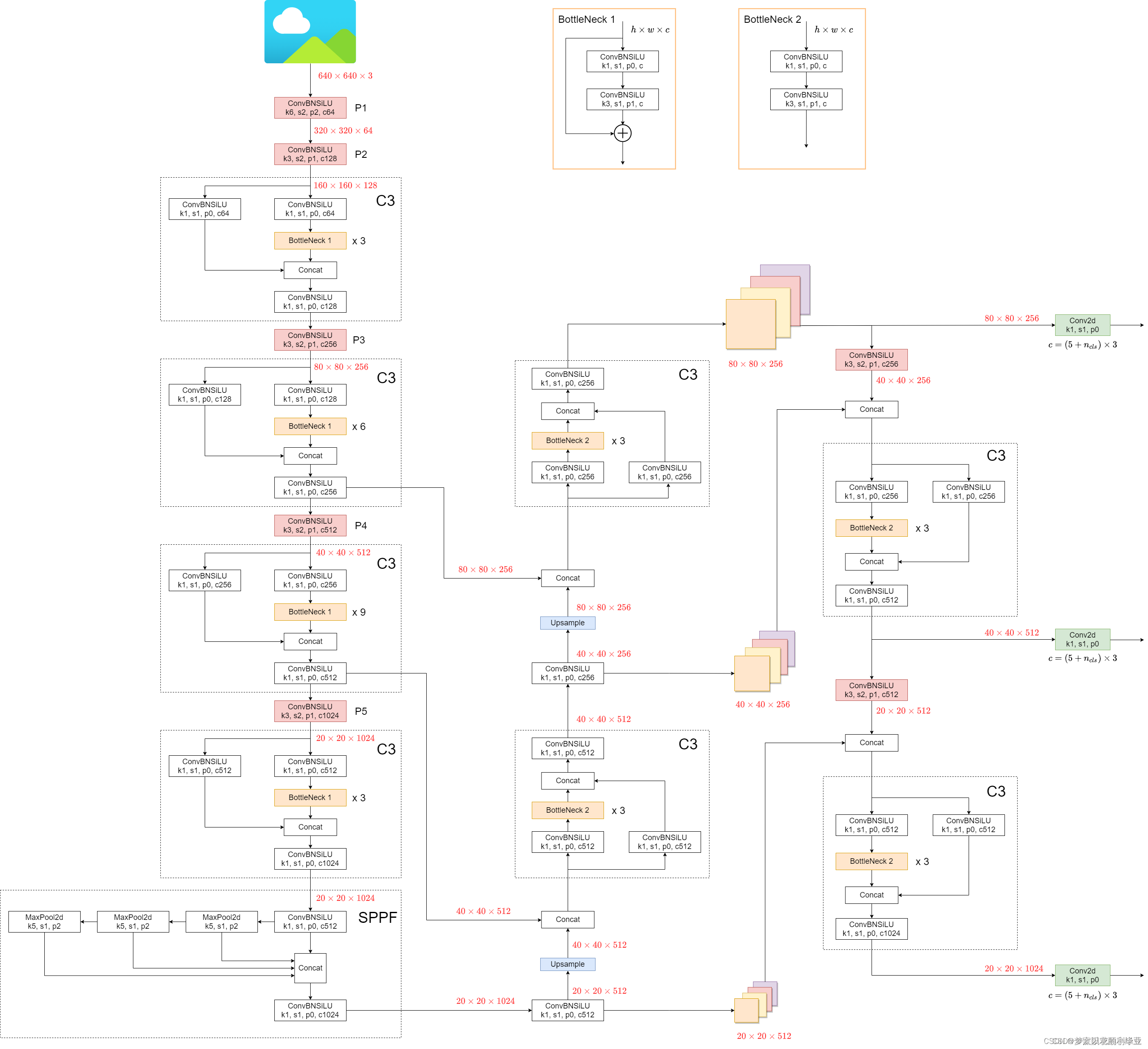
本次分析的是YOLOv5官方文档6.0版本 把整个过程看成黑箱,输入为640x640x3,输出为三个,分别为80x80x256,40x40x256,20x20x1024。80x80检测小物体,40x40检测中物体,20x20检测大物体。
把黑箱分为Backbone、Neck、Head进行分析
Backbone主要为CONV模块、CSPDarkNet53和SPFF模块
Neck主要分为FPN和PANet
Head主要为三个检测层,不同的尺度,可以进行小目标检测
主干网络
YOLOv5在Conv模块中封装了三个功能:包括卷积(Conv2d)、Batch Normalization和激活函数,同时使用autopad(k, p)实现了padding的效果。其中YOLOv5-6.0版本使用Swish(或者叫SiLU)作为激活函数,代替了旧版本中的Leaky ReLU。
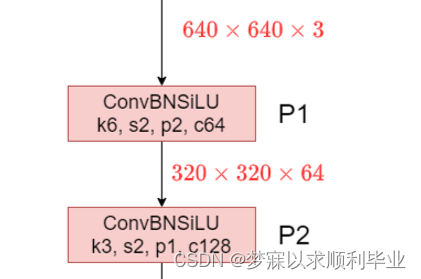
Conv/BN/SiLU 组合中的 SiLU 激活函数的主要作用是引入平滑的非线性,使网络能够学习和表示更复杂的特征,并且在训练过程中保持较好的梯度特性,从而提升网络的整体性能 K6,S2,P2,C64分别代表着卷积核的大小6x6、滑动步长2、padding填充行列数2、输出通道64(也就是这一层有64个卷积核). 640x640x3,经过k6,s2,p2,c64,怎么变成的320x320x64,首先是知道它的卷积核是6x6,通道数就是卷积核个数,64就是它的卷积核个数,其次步长为2,那么一个卷积核只会遍历三次,而且它又填充了0有2行2列,所以输出的320是( 640+2*p(乘2是考虑上下或左右两边的填充)-k(卷积核大小)/s)+1(+1是在卷积操作中,即使经过步长和填充调整,卷积核可能仍然可以在输入特征图的边缘上再放置一次,+1 就是用于这种情况,以确保不漏掉边缘上的卷积操作),即640+2X2-6=638,638/2=319如果是有小数就向下取整(不过一般长宽取32的倍数,不会出现小数),319+1=320

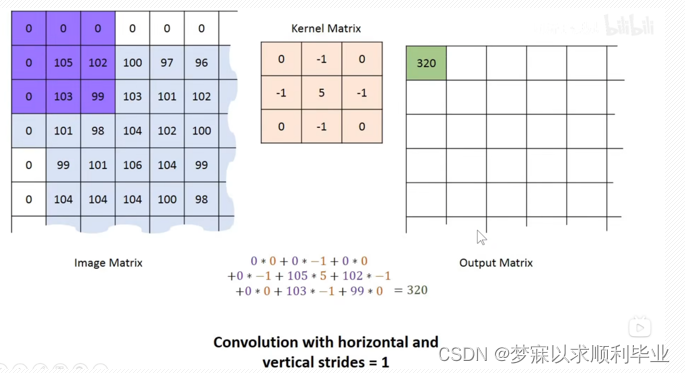
padding补0操作:为什么补一行0一列0,原因:因为不补的时候,最左上角的值105,跟卷积核操作的时候只参与了一次,而中间的值104,却每次操作都参与了,这是不公平的,这样会缺失边缘信息,所以需要补偿,补0以后左上角就参与的更多了,对于后续的特征提取就相对公平一些。 至于补多少行0是自己决定的,可以补到输入和输出的维度是一样的
用一张图可以清晰的观察到为什么进行补0操作:
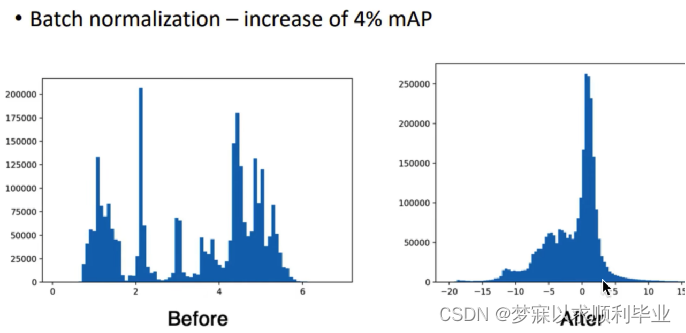
Batch Normalization,批量归一化、BN层,把神经元的输出给减去均值,除于标准差,变成以0为均值,1为标准差的一个分布,正态分布,原因:因为很多激活函数(sigmoid、tahn)在0的附近是非饱和区,如果输出太大或者太小,就陷入了激活函数的饱和区,饱和区:梯度消失、难以训练 所以BN层的作用:把神经元的输出强行集中在0附近,这是YOLOv2就提出的改进了。
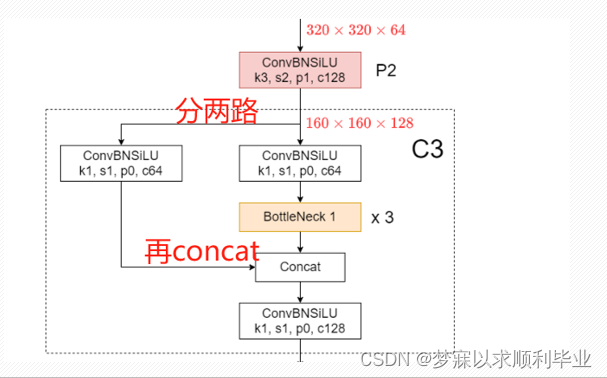
主干网络中:YOLOv5-6.0版本中使用了尺寸大小为6×6,步长为2,padding为2的卷积核代替了Focus模块,便于模型的导出,且效率更高。两个东西结果是一样的,但实验证明6x6降低了CUDA的显存,效果更好。
Bottleneck模块
每个C3模块都有,Bottleneck模块借鉴了ResNet的残差结构,其中一路先进行1 ×1 卷积将特征图的通道数减小一半,从而减少计算量,再通过3 ×3 卷积提取特征,并且将通道数加倍,其输入与输出的通道数是不发生改变的。而另外一路通过shortcut进行残差连接,与第一路的输出特征图相加,从而实现特征融合。 在YOLOv5的Backbone中的Bottleneck都默认使shortcut为True(1),而在Head中的Bottleneck都不使用shortcut。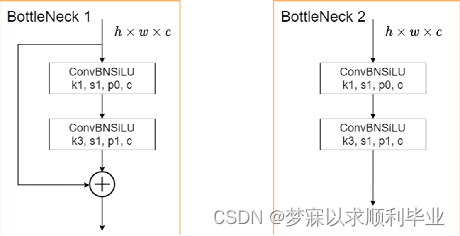
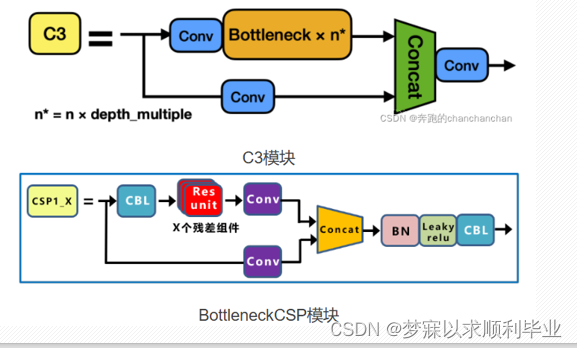
C3模块
YOLOv4和YOLOv5均借鉴了CSPNet的思想,将其运用于DarkNet53骨干网络。YOLOv5-6.0版本中使用了C3模块,替代了早期的BottleneckCSP模块。v3是DarkNet53模型、v2是DarkNet19模型、而v1是传统的DarkNet模型。 在Neck部分另外一个不同点就是New CSP-PAN了,在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP。每个C3模块里都含有CSP结构。 CSP:是将原输入分成两个分支,分别进行卷积操作使得通道数减半,然后一个分支进行Bottleneck * N操作,然后concat(相当于矩阵拼接)两个分支,使得BottlenneckCSP的输入与输出是一样的大小,这样是为了让模型学习到更多的特征。
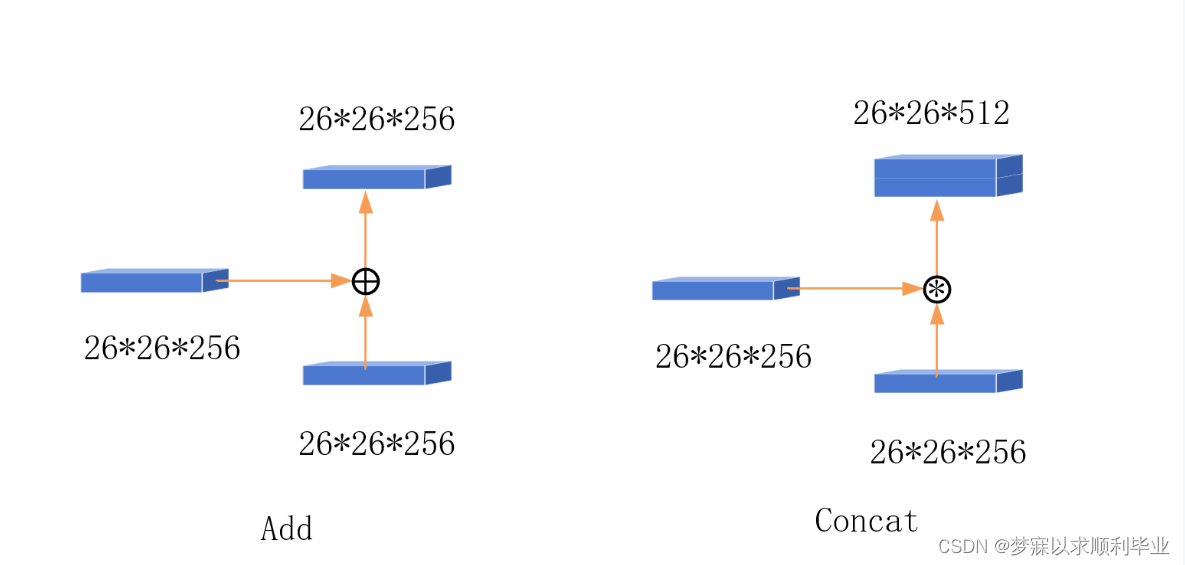
concat是一个比较重要的操作,类似矩阵拼接,但其实是张量拼接,会扩充两个张量的维度,需要区别一下ADD操作,两个是不同的概念
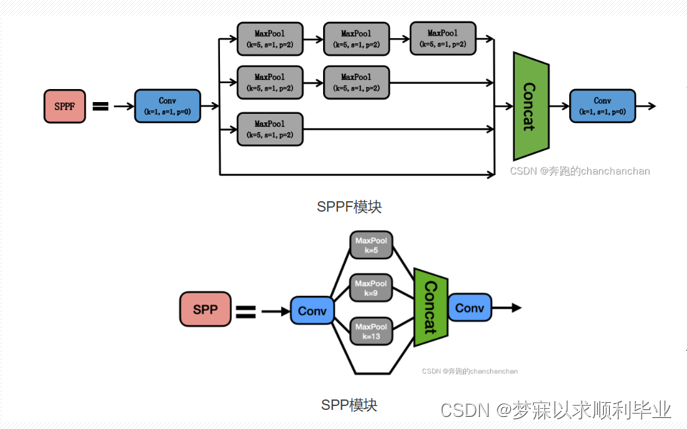
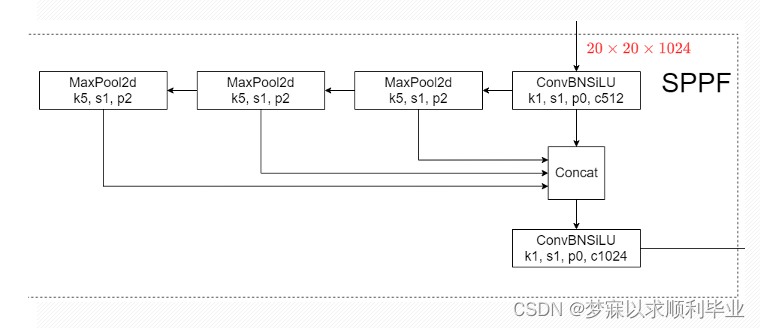
SPPF模块
YOLOv5-6.0版本使用了SPPF模块来代替V4版本的SPP模块,其中SPP是Spatial Pyramid Pooling的简称,即空间金字塔池化,YOLOv5借鉴了SPPNet的思想。 SPPF模块采用多个小尺寸池化核级联代替SPP模块中单个大尺寸池化核,从而在保留原有功能,即融合不同感受野的特征图,丰富特征图的表达能力的情况下,进一步提高了运行速度。
颈部网络
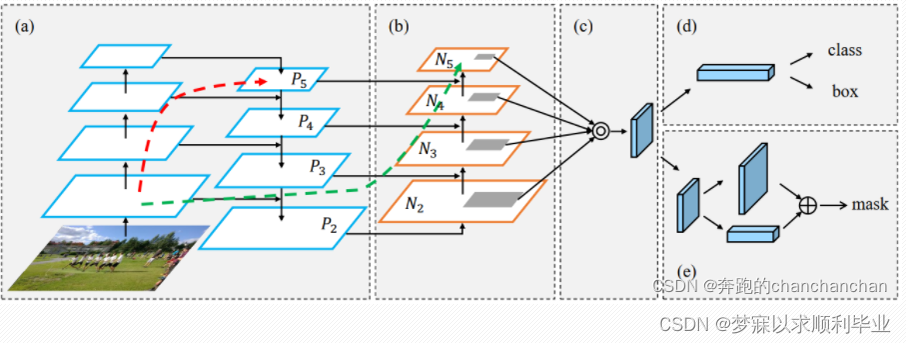
YOLOv5的Neck与YOLOV4相似,均借鉴了FPN和PANet的思想。 PANet在FPN的基础上又引入了一个自底向上(Bottom-up)的路径。经过自顶向下(Top-down)的特征融合后,再进行自底向上(Bottom-up)的特征融合,这样底层的位置信息也能够传递到深层,从而增强多个尺度上的定位能力。同时,与FPN相比(如红色线条所示),PANet中的底层特征传递所需要穿越的feature map数量大大减少(如绿色线条所示),使得底层的位置信息更容易传递到顶部。
头部网络
YOLOv5的Head对Neck中得到的不同尺度的特征图分别通过1×1卷积将通道数扩展,扩展后的特征通道数为(类别数量+5)× 每个检测层上的anchor数量,其中5分别对应的是预测框的中心点横坐标、纵坐标、宽度、高度和置信度,这里的置信度表示预测框的可信度,取值范围为( 0 , 1 ),值越大说明该预测框中越有可能存在目标。 Head中包含3个检测层,分别对应Neck中得到的3种不同尺寸的特征图。YOLOv5根据特征图的尺寸在这3种特征图上划分网格,并且给每种特征图上的每个网格都预设了3个不同宽高比的anchor,用来预测和回归目标,因此上述的通道维度可以理解为在特征图的通道维度上保存了所有基于anchor先验框的位置信息和分类信息,如下图所示。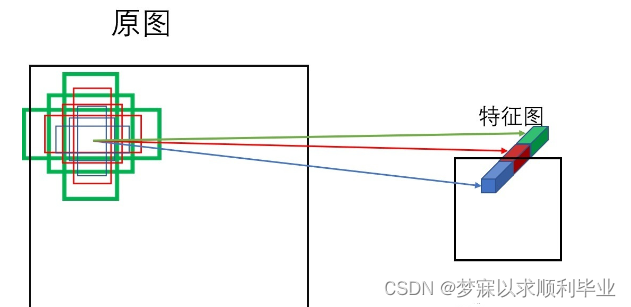
这是YOLOv3提出来的预测框公式,但是V4作者觉得不合理。原因:当真实目标中心靠近左上角点或者右下角点(σ ( t x ) 和σ ( t y )的取值需要为0或者1),直接预测出非常接近0或1的精确值是非常困难的,为了解决这个问题,V4作者引入了一个大于1的缩放系数(Scale)
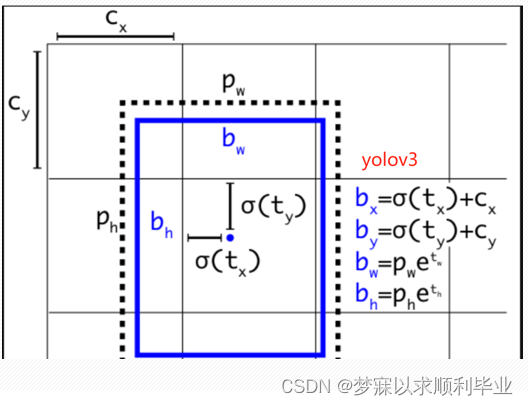
YOLOV4的公式:
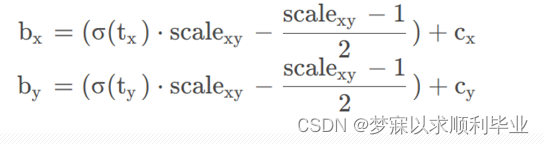
YOLOV5的公式:

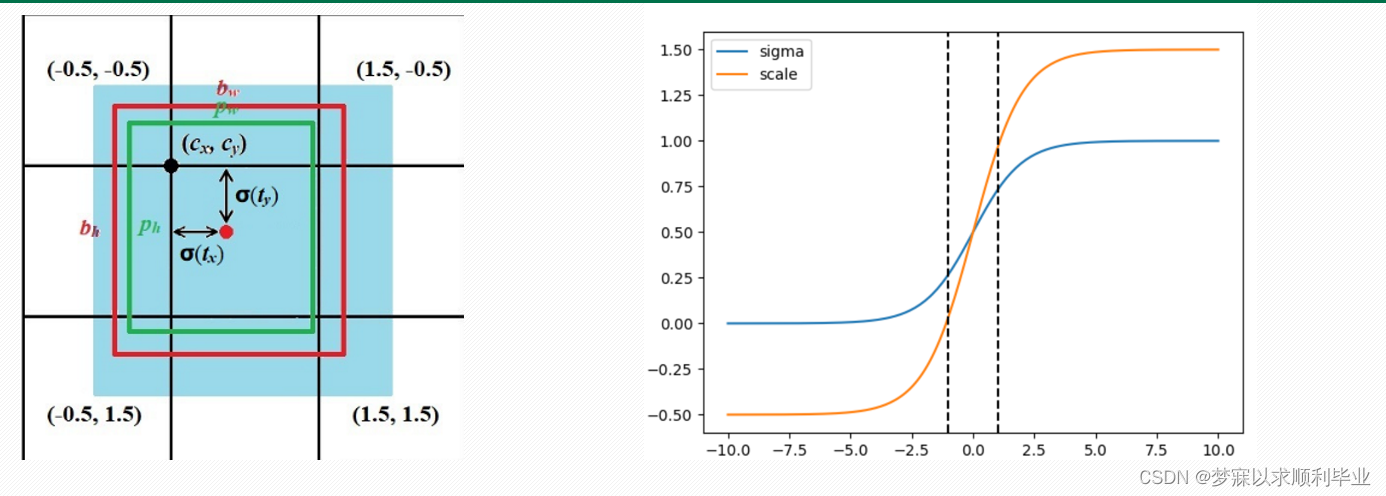
为了将预测框的中心点约束到当前网格中,使用Sigmoid函数处理偏移量,使预测的偏移值保持在 (0,1)范围内。而V5中,根据目标框回归计算公式,预测框中心点坐标的偏移量保持在(-0.5,1.5)范围内,如上图所示,scale曲线比sigmoid曲线更好,y的取值更大。
假设某个Ground Truth的中心点落在某个检测层上的某个网格中,除了中心点所在的网格之外,其左、上、右、下4个邻域的网格中,靠近Ground Truth中心点的两个网格中的anchor也会参与预测和回归,即一个目标会由3个网格的anchor进行预测,如下图所示 :
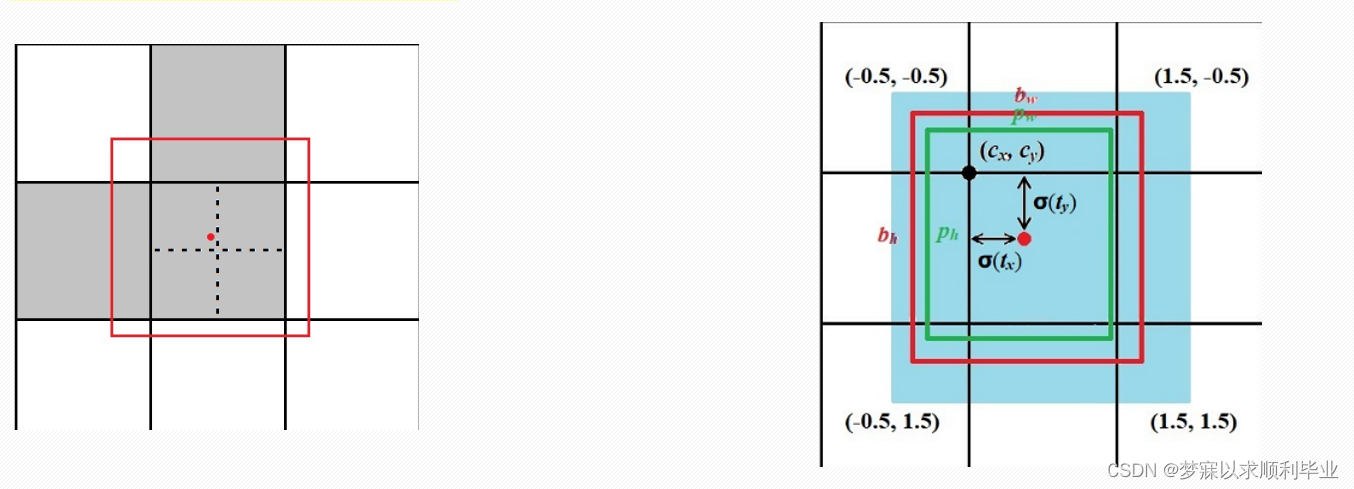
正是因为前面目标框回归做出的改进,这里才能进行邻域网格也参与预测和回归,因为左图的红点在中心点偏左上,达到了目标框范围的都需要参与检测。
YOLOV5损失函数
YOLOv5的损失函数跟V4并没有多大区别,YOLOv5的损失主要包含三个方面:边界框损失(bbox_loss)、分类损失(cls_loss)、置信度损失(obj_loss)。总损失的表达式为:

边界框损失
边界框损失IOU,交并比,它的作用是衡量目标检测中预测框与真实框的重叠程度。假设预测框为A,真实框为B
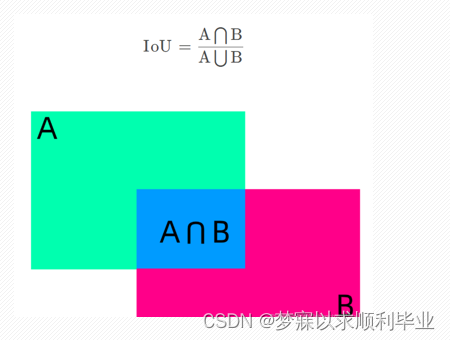
在原v3、v4基础上考虑宽高比进行改进,YOLOv5默认使用CIoU来计算边界框损失,直到V8版本,边界框损失默认依然是CIOU,CIoU的损失计算公式为: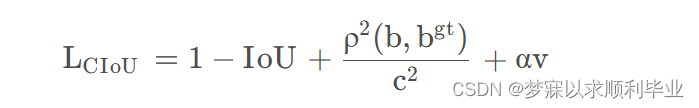
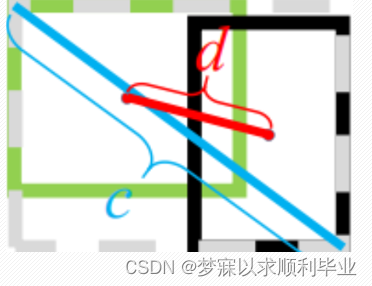
其中b和bgt 分别表示预测框和真实框的中心点,ρ表示两个中心点之间的欧式距离,c表示预测框和真实框的最小闭包区域的对角线距离,如下图所示:

分类损失
YOLOv5默认使用二元交叉熵函数来计算分类损失,直到V8,分类损失默认依然是二元交叉熵。二元交叉熵函数的定义为: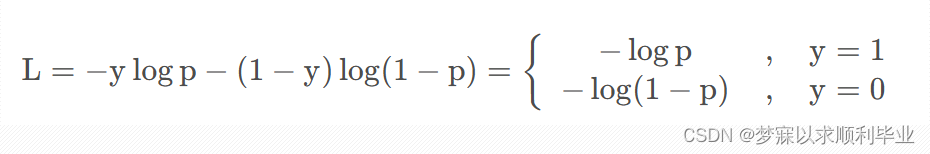
其中y为输入样本对应的标签(正样本为1,负样本为0),p为模型预测该输入样本为正样本的概率

置信度损失
YOLOv5默认使用二元交叉熵函数来计算置信度损失。除此以外,对于不同尺度的检测层上得到的置信度损失,YOLOv5分配了不同的权重系数,按照检测层尺度从大到小的顺序,对应的默认的权重系数分别为4.0、1.0、0.4,即用于检测小目标的大尺度特征图上的损失权重系数更大,从而使得网络在训练时更加侧重于小目标。
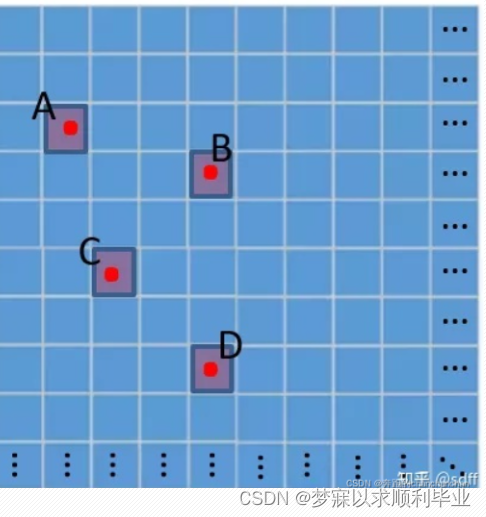
每个预测框的置信度表示这个预测框的可靠程度,值越大表示该预测框越可靠,也表示越接近真实框。如图所示,红点A 、B、C、D表示真实框的中心点,那么每个红点所在网格对应的anchor所预测和回归得到的预测框置信度应该比较大甚至接近1,而其它网格对应的预测框置信度则会比较小甚至接近0。
YOLOV5部署
我自定义的数据集是PCB的缺陷检测,数据集名称:PKU-Market-PCB(包含6种缺陷类型),首先需要了解YOLOV5的数据集是如何放置的,如下图:
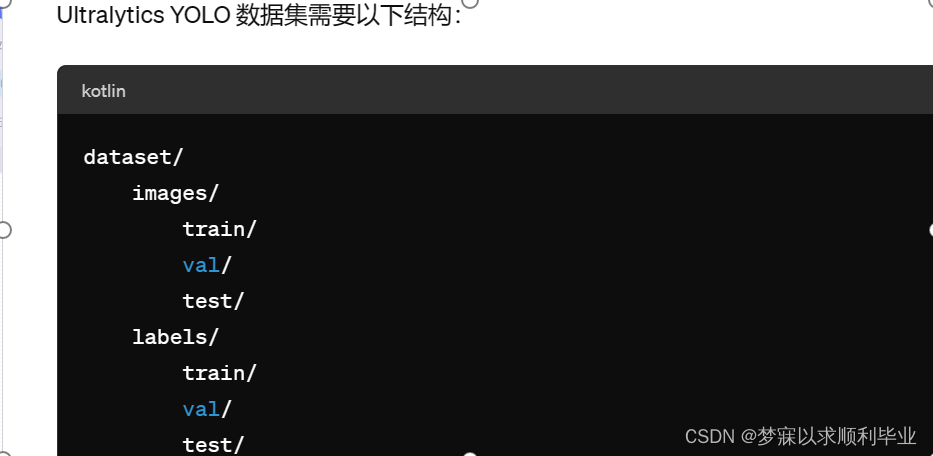
YOLO标注格式:

• 目标类别的整数编号:从0开始计数,这个编号需要与模型训练时使用的类别编号一致。
• 目标中心点的归一化图像坐标(x, y):这两个值是浮点数,范围在0到1之间,表示目标中心点在图像中的相对位置。具体来说,x是目标中心点的横坐标除以图像的宽度,y是目标中心点的纵坐标除以图像的高度。
• 目标宽度和高度的归一化值(w, h):这两个值也是浮点数,范围在0到1之间,表示目标在图像中的相对大小。具体来说,w是目标的宽度除以图像的宽度,h是目标的高度除以图像的高度。
按照自定义的格式进行训练即可,epoch选择100次,结果如下图:
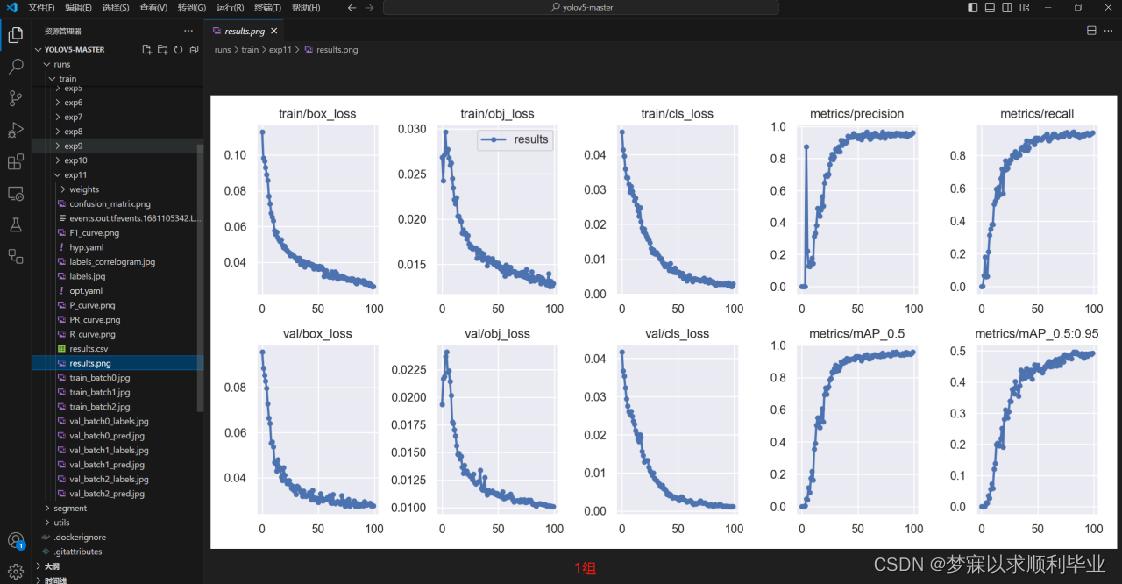
同样的操作,我又去YOLOV8进行了训练,同样的数据集,同样的平台,出来的效果是不一样的:
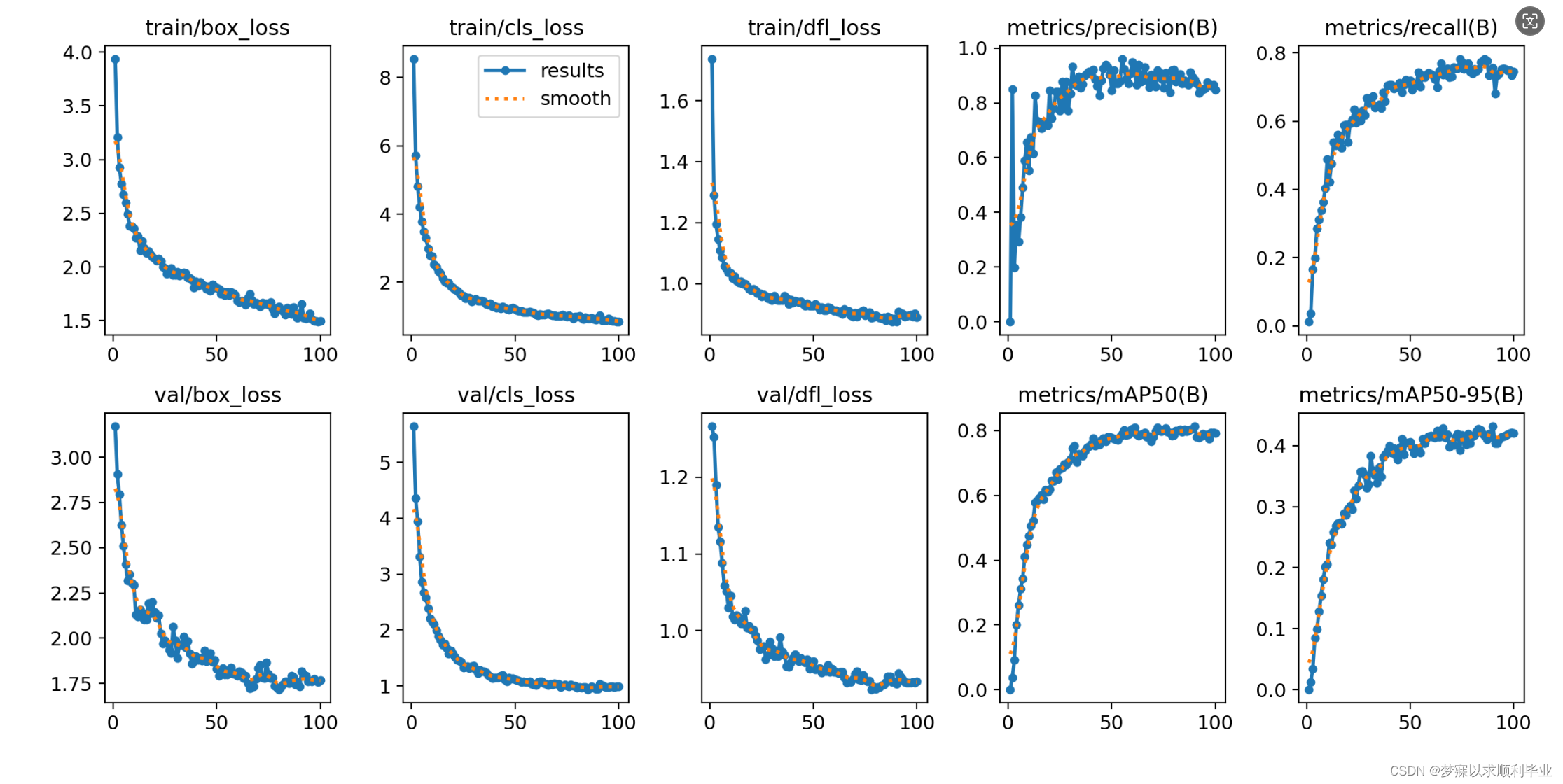
个人感觉V5的效果是比V8的效果好,并不是说版本越新越好,最近2024年5月24号已经发布了YOLOV10版本,所以有些时候版本经典更好用!下面展示验证效果图:

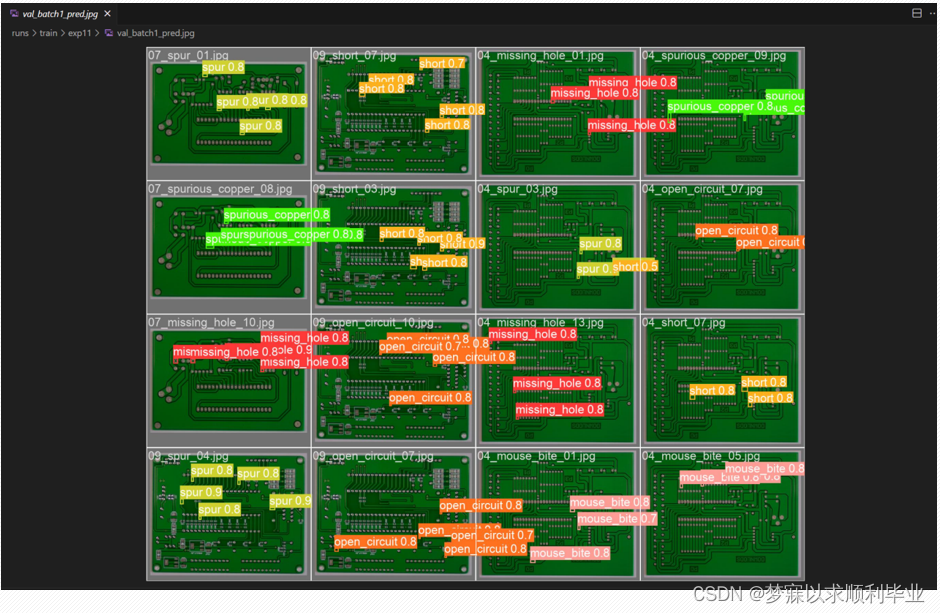
可以看到效果还是不错的,训练结果图也并没有过拟合,再次感叹YOLO系列写的实在是太好了,小白入门可以尝到甜头,增加对深度学习的学习兴趣,强烈推荐入门学习!
结论
本人纯入门小白,不懂底层代码,如有错误请各位网友批评指正。也写的太多了,有关注的话后续更新一下如何自定义数据集、训练流程、推理源码分析!















 1335
1335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









