







预处理
图片的预处理就是每一个像素减去了均值,算是比较简单的处理。
卷积核
整体使用的卷积核都比较小(3x3),3x3是可以表示「左右」、「上下」、「中心」这些模式的最小单元了。
3 × 3 which is the smallest size to capture the notion of left/right, up/down, center
还有比较特殊的1x1的卷积核(Inception-v1也有这个东西),可看做是空间的线性映射。
前面几层是卷积层的堆叠,后面几层是全连接层,最后是softmax层。所有隐层的激活单元都是ReLU,论文中会介绍好几个网络结构,只有其中一个应用了局部响应归一化层(Local Response Normalisation)。
使用多个较小卷积核的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面作者认为相当于是进行了更多的非线性映射,可以增加网络的拟合/表达能力。
具体结构

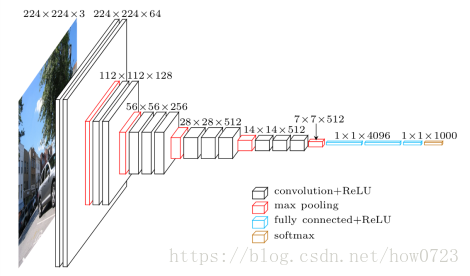
vgg16的由来,从上图可知,该结构有13个卷积层,3个全链接层。一共13+3=16
训练
训练速度变快的猜测
- 隐含的正则项,就是将5x5和7x7这样的卷积分解为多个3x3的卷积的堆叠
- 对一些层的预初始化
训练数据生成
如果要使用224x224的图作为训练的输入,用S表示图片最小边的值,当S=224时这个图就直接使用,直接将多余的部分减掉(我的理解);对于S远大于224的,可以通过剪切这个图片中包含object的子图作为训练数据。
这部分看了半天都没有理解,没有看过以前的论文真是考验理解能力(捂脸)~,来子这里的解释
Multi-scale 训练
把原始 image缩放到最小边S>224;然后在full image上提取224*224片段,进行训练。
方法1:在S=256,和S=384上训练两个模型,然后求平均
方法2:类似OverFeat测试时使用的方法,在[Smin,Smax]scale上,随机选取一个scale,然后提取224*224的图片,训练一个网络。这种方法类似图片尺寸上的数据增益。















 2629
2629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









