







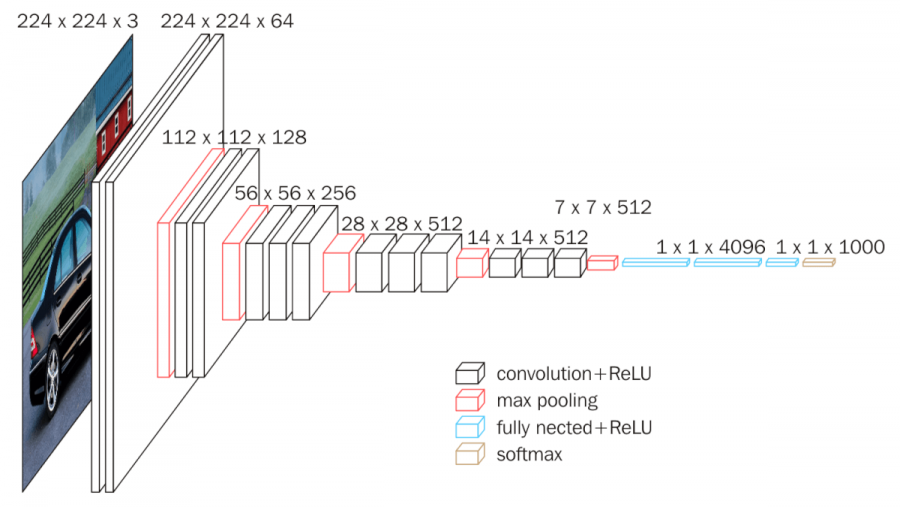
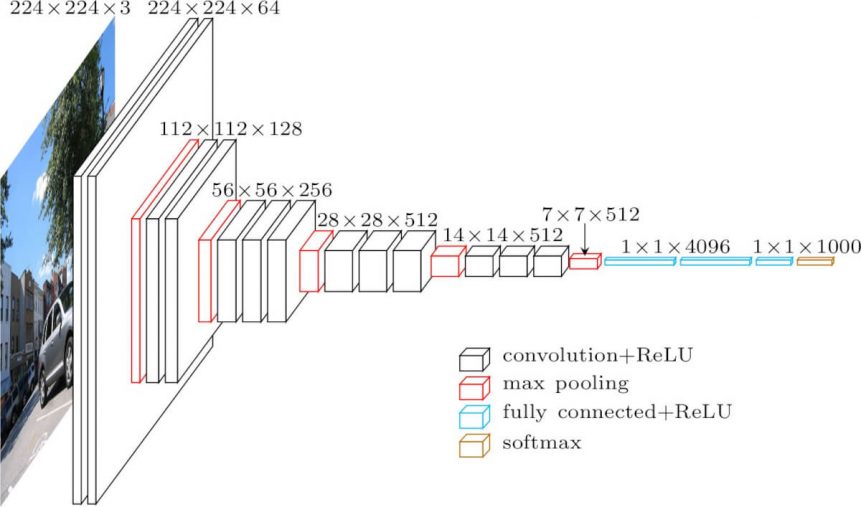
VGG16是由牛津大学的K. Simonyan和A. Zisserman在“用于大规模图像识别的非常深卷积网络”的论文中提出的卷积神经网络模型。 该模型在ImageNet中实现了92.7%的前5个测试精度,这是属于1000个类的超过1400万张图像的数据集。它是ILSVRC-2014提交的着名模型之一。它通过一个接一个地用多个3×3内核大小的过滤器替换大型内核大小的过滤器(分别在第一个和第二个卷积层中为11和5)来改进AlexNet。VGG16训练了几周,并使用NVIDIA Titan Black GPU。
数据集
ImageNet是一个超过1500万个标记的高分辨率图像的数据集,属于大约22,000个类别。这些图像是从网上收集的,并由人类贴标机使用亚马逊的Mechanical Turk众包工具进行标记。从2010年开始,作为Pascal视觉对象挑战赛的一部分,举办了名为ImageNet大规模视觉识别挑战赛(ILSVRC)的年度比赛。ILSVRC使用ImageNet的一个子集,在1000个类别中分别拥有大约1000个图像。总之,大约有120万个训练图像,50,000个验证图像和150,000个测试图像。ImageNet由可变分辨率图像组成。因此,图像已被下采样到256×256的固定分辨率。给定矩形图像,图像被重新缩放并从结果图像中裁剪出中心256×256色块。
架构
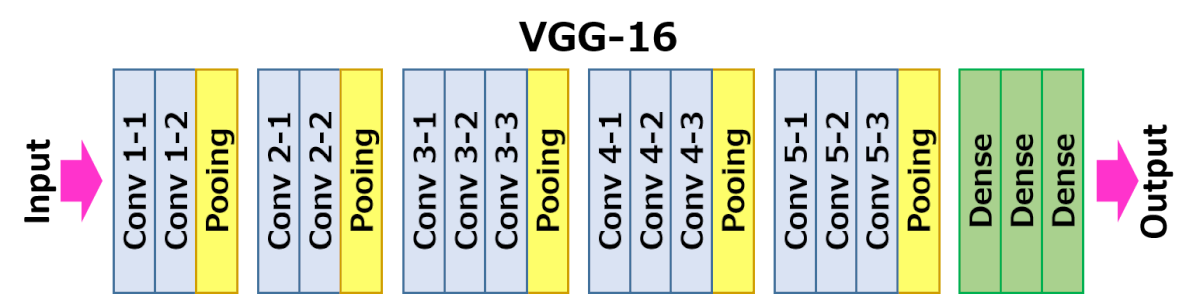
下面描述的架构是VGG16。
VGG16架构
cov1层的输入是固定大小的224 x 224 RGB图像。图像通过一堆卷积(转换)层,其中滤镜使用非常小的感受野:3×3(这是捕捉左/右,上/下,中心概念的最小尺寸)。在其中一种配置中,它还使用1×1卷积滤波器,可以看作是输入通道的线性变换(后面是非线性)。卷积步幅固定为1个像素; 转换的空间填充。层输入使得在卷积之后保留空间分辨率,即,对于3×3转换,填充是1像素。层。空间池由五个最大池组执行,这些层跟随一些转换。图层(并非所有转换图层都跟随最大池)。最大池化在2×2像素窗口上执行,
三个完全连接(FC)层跟随一堆卷积层(在不同架构中具有不同的深度):前两个每个具有4096个通道,第三个执行1000路ILSVRC分类,因此包含1000个通道(每个一个类)。最后一层是soft-max层。全连接层的配置在所有网络中都是相同的。
所有隐藏层都配备有整流(ReLU)非线性。还注意到,没有一个网络(除了一个)包含本地响应标准化(LRN),这种标准化不会改善ILSVRC数据集的性能,但会导致内存消耗和计算时间增加。
配置
ConvNet配置如图02所示。网络的名称(AE)。所有配置均遵循架构中存在的通用设计,仅在深度上有所不同:从网络A中的11个权重层(8个转换层和3个FC层)到网络E中的19个权重层(16个转换层和3个FC层) 。转的宽度。层(通道数)相当小,从第一层中的64开始,然后在每个最大池层之后增加2倍,直到达到512。
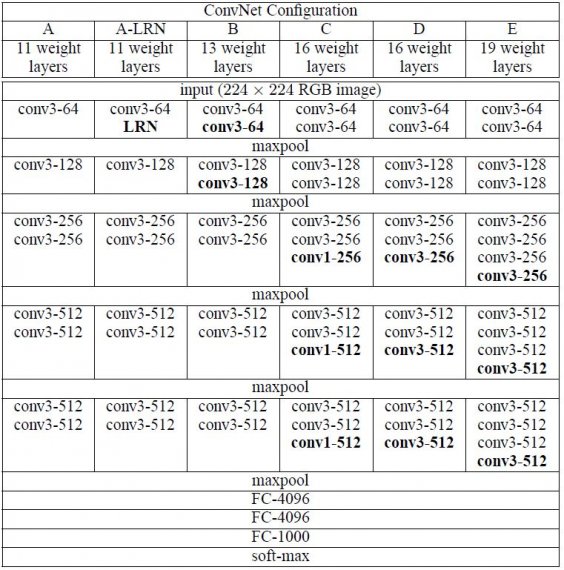
图:2
用例和实施
不幸的是,VGGNet有两个主要缺点:
- 这是 痛苦的缓慢 训练。
- 网络体系结构权重本身非常大(涉及磁盘/带宽)。
由于其全部连接节点的深度和数量,VGG16超过533MB。这使得部署VGG成为一项令人厌烦的任务.VGG16用于许多深度学习图像分类问题; 但是,较小的网络架构通常更为理想(例如SqueezeNet,GoogLeNet等)。但它是一个很好的学习目标,因为它很容易实现。
[ Pytorch ]
[ Tensorflow ]
[ Keras ]
结果
VGG16在ILSVRC-2012和ILSVRC-2013竞赛中明显优于上一代机型。VGG16的结果也在争夺分类任务获胜者(GoogLeNet的误差为6.7%),并且大大优于ILSVRC-2013获胜提交的Clarifai,其中外部培训数据达到11.2%,没有它的11.7%。关于单网性能,VGG16架构实现了最佳结果(7.0%测试错误),优于单个GoogLeNet 0.9%。
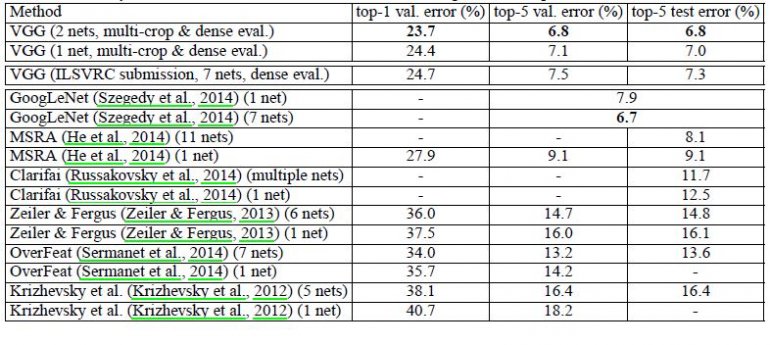
已经证明,表示深度有利于分类准确性,并且可以使用具有显着增加的深度的传统ConvNet架构来实现ImageNet挑战数据集上的最新性能。

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









