







一、问题描述
利用机器学习算法实现乳腺癌数据集的二分类问题,良恶性乳腺癌肿瘤预测。
二、数据集分析
- 乳腺癌数据集下载地址为:https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
- 乳腺癌数据集中一共有699个样本,共11列数据,每个样本有10个特征和1个对应的标签
- 包含16个缺失值,用”?“标出
| Sample code number | 索引ID |
| Clump Thickness | 肿瘤厚度 |
| Uniformity of Cell Size | 细胞大小均匀性 |
| Uniformity of Cell Shape | 细胞形状均匀性 |
| Marginal Adhesion | 边缘粘附力 |
| Single Epithelial Cell Size | 单上皮细胞大小 |
| Bare Nuclei | 裸核 |
| Bland Chromatin | 染色质的颜色 |
| Normal Nucleoli | 核仁正常情况 |
| Mitoses | 有丝分裂情况 |
| Class | 分类情况,2为良性,4为恶性 |
- 当我们利用padas直接在线下载数据,进行查看后,发现数据集第一行标题意义不明显,在代码中将其修改为具有含义的列名

三、代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn.metrics import classification_report,accuracy_score,confusion_matrix
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
warnings.filterwarnings('ignore')
pd.options.display.max_rows = None
pd.options.display.max_columns = None
# 设置字段名,原始数据重没有每一维数据代表的含义
column_names = ['Sample code number','clump thickness','uniformity of cell size',\
'uniformity of cell shape','marginal adhesion',\
'single epithelial cell size','bare nuclei','bland chromatin',\
'normal nucleoli','mitnoses','class']
data = pd.read_csv("breast-cancer-wisconsin.data",header=None,names=column_names)
# 显示前四条记录
print(data.head(4))
# 显示数据维度
print(data.shape)
# 查看数据信息
print(data.info())
# 显示数据统计描述
print(data.describe())
# 显示数据分布情况
print(data.groupby('class').size())
# 缺失值处理,在bare nuclei列中有缺失值,以?表示的
'''
mean_value = data[data["bare nuclei"]!="?"]["bare nuclei"].astype(np.int).mean()# 计算异常值列的平均值
data = data.replace('?',mean_value)
data["bare nuclei"] = data["bare nuclei"].astype(np.int64)
'''
data = data.replace(to_replace='?',value=np.nan) #非法字符的替代
data = data.dropna(how='any')
# print(data.head(25))
# 拆分数据集
#将样本按照3:1划分训练集和测试集,参数解释:
# train_data:所要划分的样本特征集 1~9为特征值
# train_target:所要划分的样本结果 10表示label
# test_size:样本占比,如果是整数的话就是样本的数量
# random_state:是随机数的种子。
X_train,X_test,y_train,y_test = train_test_split(data[column_names[1:10]],\
data[column_names[10]],\
test_size=0.25,\
random_state=5)
# 查看训练样本的数量和类别分布
print(y_train.value_counts())
print(y_test.value_counts())
#标准化数据,保证每一个维度的特征数据方差为1,均值为0.使得预测结果不会被某些维度过大的特征值所主导
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
# 模型一:线性分类模型逻辑回归
# LR = LogisticRegression()
LR = LogisticRegression(C=1.0,penalty='l1',tol=0.1)
LR.fit(X_train,y_train)
LR_y_predict = LR.predict(X_test)
#使用线性分类模型中的classification_report模块对肿瘤预测模型的性能进行分析
print('预测结果为:{}'.format(LR.score(X_test,y_test)))
print('预测结果为:{}'.format(accuracy_score(y_test,LR_y_predict)))
#利用classification_report模块获得LR的其他三个指标(pression,recall,f1 score)
print(classification_report(y_test,LR_y_predict,target_names=['Bebign','Malignat']))
# 模型二:线性分类模型SGD
SGDC = SGDClassifier()
SGDC.fit(X_train,y_train)
SGDC_y_predict = SGDC.predict(X_test)
print('Accuracy Of SGD:',SGDC.score(X_test,y_test))
print(classification_report(y_test,SGDC_y_predict,target_names=['Bebign','Malignat']))
# 多种模型比较
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds, random_state=seed)
# 评估算法
results = []
for name in models:
result = cross_val_score(models[name], X_train, y_train, cv=kfold, scoring='accuracy')
results.append(result)
msg = '%s: %.3f (%.3f)' % (name, result.mean(), result.std())
print(msg)
# 图表显示
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(models.keys())
plt.show()
- 整个算法的过程符合机器学习的一般流程,包括:
- 定义分析目标:机器学习解决实际问题,首先要明确目标任务,这是机器学习算法选择的关键。本任务为监督学习中的定性问题,可用分类算法,如有定量分析可用回归方法。
- 收集数据:本任务中的数据集来自于威斯康辛乳腺科数据集,网络下载,上有链接。
- 整理预处理:获得数据后,不必急于建模,可先对数据进行一些探索,了解数据的大致结构、数据统计信息、数据噪声以及数据分布等。进行探索后,对数据进行预处理。本任务中有对缺失值的处理,特征值(前10项,可以去除编号项)和目标值(第11项)的确定,数据集的分割处理,还有数据标准化的特征工程
- 数据建模:模型本身没有优劣,在选择模型时,一般不存在对任何情况都表现很好的算法,这叫做“没有免费的午餐”原则。在实际选择时,一般会用几种不同方法进行模型训练,然后比较它们的性能,从中选择最优的一个。不同的模型使用不同的性能衡量标准。
- 模型训练:模型训练过程中,需要对模型超参进行调优,如果对算法原理理解不够透彻,往往无法快速定位能决定模型优劣的模型参数。
- 模型评估:使用训练数据构建模型后,需使用测试数据对模型进行测试和评估,测试模型对新数据的泛化能力。过拟合、欠拟合判断是模型诊断中重要的一步,常见的方法有交叉验证、绘制学习曲线等。过拟合的基本调优思路是增加数据量,降低模型复杂度。欠拟合的基本调优思路是提高特征数量和质量,增加模型复杂度。
- 模型应用:模型应用主要与工程实现的相关性比较大。工程上是结果导向,模型在线上运行的效果直接决定模型的好坏,不单纯包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性是否可接受等方面。
- KFold()函数:在sklearn中属于model_slection模块,格式KFold(n_splits=’warn’, shuffle=False, random_state=None),其中n_splits 表示划分为几块(至少是2);shuffle 表示是否打乱划分,默认False,即不打乱;random_state 表示是否固定随机起点,Used when shuffle == True.
- cross_val_score()函数:交叉验证,用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合,还可以有哦那个有限的数据中获取尽可能多的有效信息。其格式cross_val_score(estimator, X, y=None, scoring=None,cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’),其中estimator表示估计方法对象(分类器) ,X表示数据特征(Features), y表示数据标签(Labels), soring是调用方法(包括accuracy和mean_squared_error等等) ,cv表示几折交叉验证 ,n_jobs是同时工作的cpu个数(-1代表全部)。
四、算法分析
- 逻辑回归(Logistic Regression)是一种预测分析,解释因变量与一个或多个自变量之间的关系,与线性回归不同之处在于它的目标变量有几种类别,所以逻辑回归主要用于解决分类问题。虽然名称上有回归二字,但是它却是分类算法,主要是因为它的本质是在一个线性模型上加上一个映射函数Sigmod,将线性模型得到的连续结果映射到离散型上,常用于二分类问题,在多分类问题的推广叫softmax。
- 逻辑回归的优缺点:
- 优点:计算代码不多,可解释性强,可控性高,且训练速度快,计算代价不高,存储资源低
- 缺点:容易欠拟合,分类精度可能不高
- 适用数据类型:数值型和标称型数据
- 二分类问题中一般使用Sigmod函数作为预测分类函数,其函数公示为:
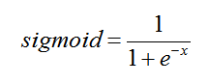
- 自变量取值为任意实数,值域[0,1],如图所示

- Sigmod函数是一个S形状的曲线,取值在[0,1]之间,在远离0的地方函数的值会很快接近0或者1,这个特征对二分类非常重要。
- 逻辑回归的假设函数形式:
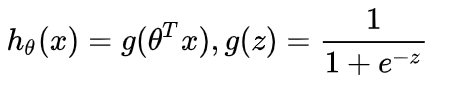 ,则得到
,则得到 ,其中
,其中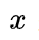 是输入,
是输入,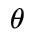 是要求的参数。
是要求的参数。 - 假设
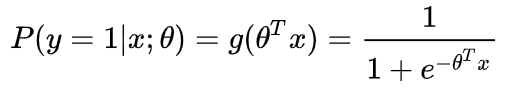 ,这个函数的意思就是在给定
,这个函数的意思就是在给定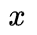 和
和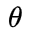 的条件下
的条件下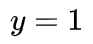 的概率。
的概率。 - 逻辑回归的代价函数形式为:
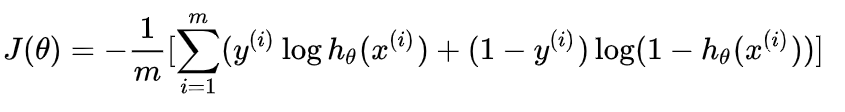
- 用经典的梯度下降法不断迭代求偏导,逐渐逼近的最佳值,使损失函数取得极小值。
- 对于逻辑回归算法的效果评估,一般采用曲线下面积(Area Under the Curve,AUC)指标来评价。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









