









下载
GitHub - pgvector/pgvector: Open-source vector similarity search for Postgres
源码编译
##文件解压缩
unzip pgvector-0.6.2.zip
##编译
make && make install

功能验证
#安装扩展
CREATE EXTENSION vector;
#创建测试表
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));
#创建分布式表
SELECT create_distributed_table('items', 'id');
#插入测试数据
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'), ('[2,2,4]'), ('[3,1,4]'), ('[4,2,5]');
#按与给定向量相似度(L2 distance)排序,显示前5条
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
SELECT embedding <-> '[1,2,3]' AS distance FROM items;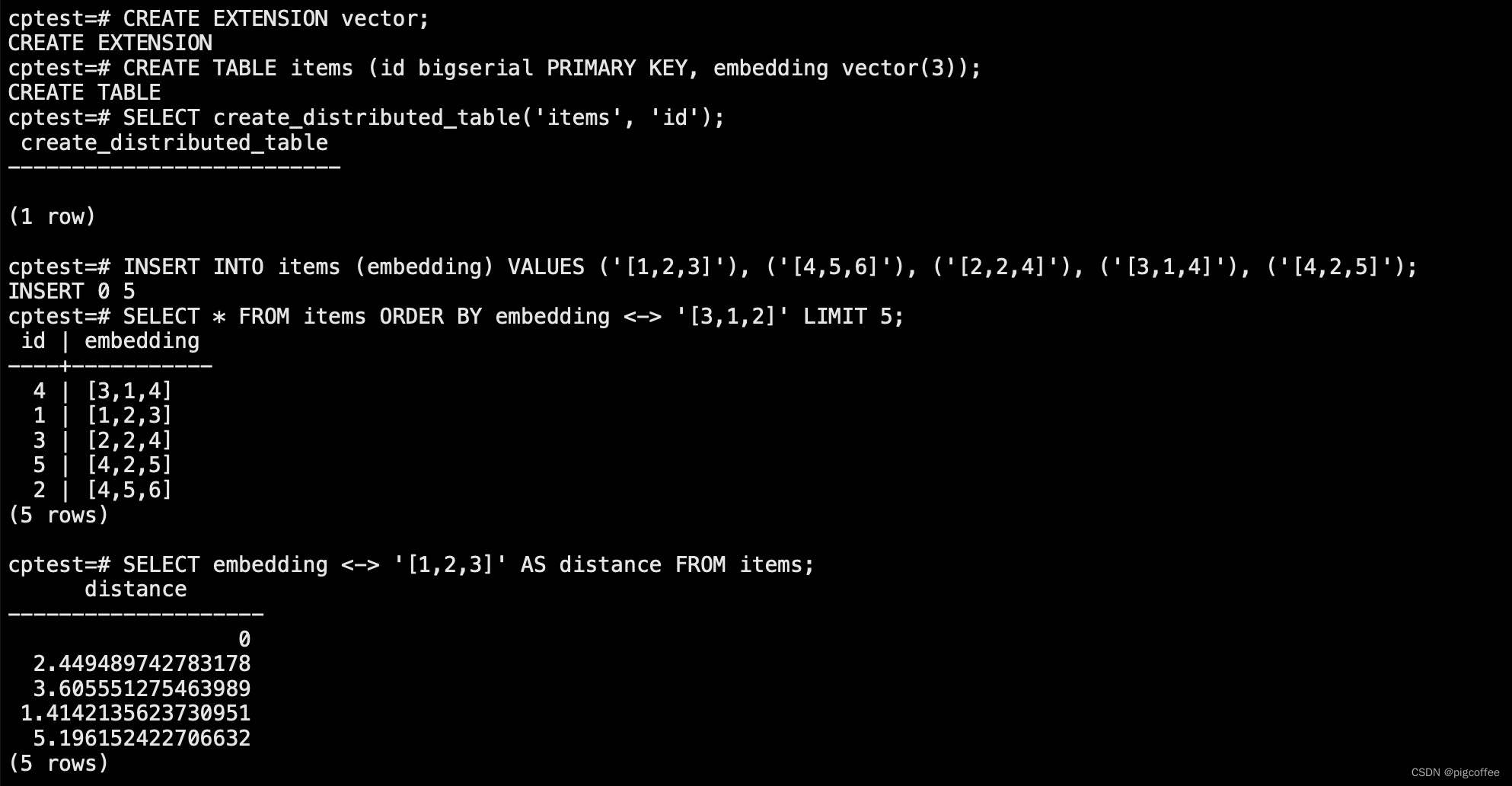

















 2557
2557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









