







目录
0 环境准备
- ollama已部署推理模型qwen:7b
- ollama已部署嵌入模型bge-large-zh-v1.5
- 已安装miniconda环境
1 开发环境准备
1.1 创建项目python环境
通过conda命令创建项目的python开发环境
conda create -n mcp_demo python=3.101.2 在pycharm创建项目
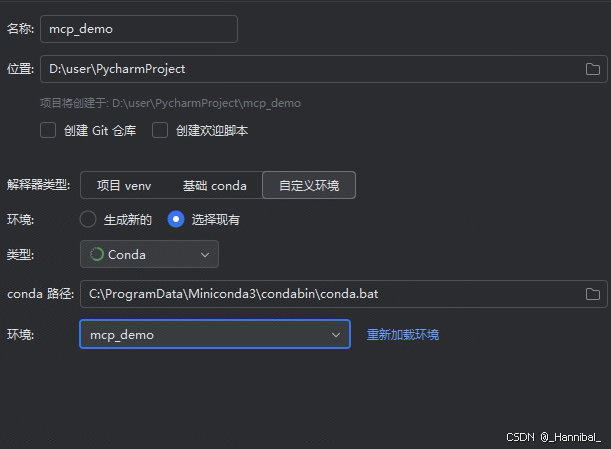
- 解释器类型:选择自定义环境
- 环境:选择现有
- 类型:选择conda
- 环境:选择上一步创建的环境
1.3 安装项目依赖
安装openai、openai-agents openai mivlus相关依赖
pip install openai python-dotenv openai-agents pymilvus2 资源准备
本项目中需要读取本地搭建的milvus向量数据库存储的内容,回答相关问题,因此需要先构建好本地milvus数据库服务。可参考以下内容搭建:
milvus实战-基于Ollama+bge-large-zh搭建嵌入模型,fastAPI提供http服务将PDF文件写入milvus向量库_bge milvus-CSDN博客
构建完成后请求上传pdf文件http接口,将pdf文件存储至milvus服务器后,此时milvus库中pdf-documents队列已存在数据,后续章节的查询基于以上博客的内容完成。
知识库和问答系统拆开构建是大规模部署的解决方案,也能节省问答过程中构建向量库的时间,提高问答系统效率,也避免了重复构建向量库。
3 程序逻辑实现
程序主要逻辑是先接收输入的问题,去milvus数据库中查询相关内容,定义agent只能根据定义的工具获取查询的结果,再调用大模型基于查询结果回答输入的问题。
3.1 导入相关依赖包
import logging
import os
from agents import set_default_openai_client, Runner, OpenAIChatCompletionsModel, Agent, function_tool, FileSearchTool
from dotenv import load_dotenv
from openai import AsyncOpenAI, OpenAI
from pymilvus import connections, Collection3.2 加载配置文件
load_dotenv()
api_key = os.getenv('OPENAI_API_KEY')
base_url = os.getenv('BASE_URL')
logging.getLogger("openai").setLevel(logging.CRITICAL) # 屏蔽INFO/WARNING级别日志3.3 获取milvus集合
def get_milvus_collection():
connections.connect(alias="default", host="localhost", port="19530")
collection = Collection("pdf_documents") # 加载已存在的Milvus集合
return collection3.4 定义查询工具
@function_tool
def milvus_retriever(query, top_k=3):
"""查询知识库,获取数据库选型技术指导
:param query: 必要参数,字符串类型,用于表示查询的具体内容。
:param top_k: 可选参数,整数类型,用于表示返回的结果数量,默认为3。
:return:返回一个包含查询结果的列表,每个结果是一个字典,包含文本和来源信息。
"""
client = OpenAI(base_url=base_url, api_key=api_key)
collection = get_milvus_collection()
embeddings_model = os.getenv('EMBEDDINGS_MODEL')
# 将查询文本向量化
response = client.embeddings.create(input=query, model=embeddings_model)
query_vector = response.data[0].embedding
search_params = {"search_type":"similarity"}
results = collection.search(data=[query_vector],
anns_field="vector",
param=search_params,
limit=top_k,
output_fields=["content", "source"])
return [{"text": hit.entity.get("content"), "source": hit.entity.get("source")} for hit in results[0]]3.5 定义获取openai client
def get_openai_client():
return AsyncOpenAI(
api_key=api_key,
base_url=base_url
)3.6 定义获取大模型
def get_chat_model(external_client):
model_name = os.getenv('MODEL')
return OpenAIChatCompletionsModel(
model=model_name,
openai_client=external_client
)3.7 定义agent
def get_agent(model):
return Agent(
name = "知识库",
instructions = "你是一名一个知识库助手,只能调用本地定义的工具,查询知识库的内容回答问题,如果没有相关内容,回答不知道。",
tools = [milvus_retriever],
model = model
)3.8 定义程序主流程
async def run_request():
external_client = get_openai_client()
set_default_openai_client(external_client)
agent = get_agent(get_chat_model(external_client))
result = await Runner.run(
agent,
"爱奇艺选用了哪些数据库?"
)
return result.final_output3.9 定义main方法
if __name__ == "__main__":
import asyncio
print(asyncio.run(run_request()))4 完整代码
import logging
import os
from agents import set_default_openai_client, Runner, OpenAIChatCompletionsModel, Agent, function_tool, FileSearchTool
from dotenv import load_dotenv
from openai import AsyncOpenAI, OpenAI
from pymilvus import connections, Collection
load_dotenv()
api_key = os.getenv('OPENAI_API_KEY')
base_url = os.getenv('BASE_URL')
logging.getLogger("openai").setLevel(logging.CRITICAL) # 屏蔽INFO/WARNING级别日志
def get_milvus_collection():
connections.connect(alias="default", host="localhost", port="19530")
collection = Collection("pdf_documents") # 加载已存在的Milvus集合
return collection
@function_tool
def milvus_retriever(query, top_k=3):
"""查询知识库,获取数据库选型技术指导
:param query: 必要参数,字符串类型,用于表示查询的具体内容。
:param top_k: 可选参数,整数类型,用于表示返回的结果数量,默认为3。
:return:返回一个包含查询结果的列表,每个结果是一个字典,包含文本和来源信息。
"""
client = OpenAI(base_url=base_url, api_key=api_key)
collection = get_milvus_collection()
embeddings_model = os.getenv('EMBEDDINGS_MODEL')
# 将查询文本向量化
response = client.embeddings.create(input=query, model=embeddings_model)
query_vector = response.data[0].embedding
search_params = {"search_type":"similarity"}
results = collection.search(data=[query_vector],
anns_field="vector",
param=search_params,
limit=top_k,
output_fields=["content", "source"])
return [{"text": hit.entity.get("content"), "source": hit.entity.get("source")} for hit in results[0]]
def get_openai_client():
return AsyncOpenAI(
api_key=api_key,
base_url=base_url
)
def get_chat_model(external_client):
model_name = os.getenv('MODEL')
return OpenAIChatCompletionsModel(
model=model_name,
openai_client=external_client
)
def get_agent(model):
return Agent(
name = "知识库",
instructions = "你是一名一个知识库助手,只能调用本地定义的工具,查询知识库的内容回答问题,如果没有相关内容,回答不知道。",
tools = [milvus_retriever],
model = model
)
async def run_request():
external_client = get_openai_client()
set_default_openai_client(external_client)
agent = get_agent(get_chat_model(external_client))
result = await Runner.run(
agent,
"爱奇艺选用了哪些数据库?"
)
return result.final_output
if __name__ == "__main__":
import asyncio
print(asyncio.run(run_request()))5 测试
5.1 调用流程

5.2 测试结果

附录
配置文件.env


















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









