







本文重点
任何机器学习算法都是通过最小化损失函数来达到求解最优解的目的,那么本节课程我们将学习聚类算法K-Means的优化目标
k-means的代价函数
k-均值中用大写K表示簇的总数,用小写k表示聚类中心的序号,所以小写k的范围是1~K。
随机初始化k个聚类中心,记作μ1,μ2…μk∈Rn, 用 c(1) , c(2) ,..., c(m)来存储与第 i 个实例数据最近的聚类中心的索引,μc(i)表示第i个实例所属的聚类中心,假如说实例x(i)被划为第7个簇,那么c(i)=7,因此μc(i)=μ7
K-均值最小化问题:最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此 K-均值的代价函数(失真代价函数)为:
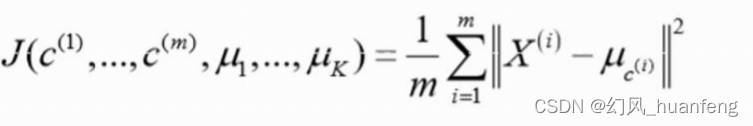
我们回忆一下K-均值迭代算法,它有两个循环构成,其中第一个循环是用于减小c(i)引起的代价,而第二个循环则是用于减小 μ(i)引起的代价。
实际上是将这两组变量分割开来考虑的,分别最小化J,首先C作为变量,然后μ作为变量,那么k均值算法的作用就是首先关于c求J的最小值,然后关于μ求J的最小值,然后反复循环,每一次迭代都在减小代价函数。
















 1279
1279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











