






引言
在人工智能领域,大模型微调是一个热门话题,尤其是在自然语言处理(NLP)领域。本文将介绍大模型中的instruct、chat和base模型的不同点,探讨常见的微调框架,并分享我所使用的微调框架及其GitHub地址,最后详细介绍我的微调步骤。
1. 大模型类型介绍
1.1 Base模型
Base模型,也称为基座模型,是在大量无标注数据上进行预训练的模型,学习到广泛的语言特征。这些模型具有大规模预训练、泛化能力强和可微调性等特点。
1.2 Chat模型
Chat模型专为处理人机交互而设计,能够理解上下文,维持对话历史,生成连贯且情境相关的响应。这类模型的特点是上下文感知、互动性和创意生成。ChatGPT就是一个典型的chat模型。
1.3 Instruct模型
Instruct模型是为遵循指令或完成特定任务而设计和优化的模型。它们经过指令数据集微调,能够更好地理解和执行用户提供的指令。
2. 常见微调框架
在微调大模型时,有多种框架可供选择。以下是一些常见的微调框架:
- LoRA:一种基于低阶自适应的大语言模型微调方法,模拟全量微调的效果。
- PEFT:围绕部分参数进行微调的方法,目前比较常用。
- RLHF:基于强化学习的微调方法,由OpenAI团队提出。
3. 我所使用的微调框架
我选择使用的微调框架是LLaMA-Factory,这是一个国内北航开源的低代码大模型训练框架,专为大型语言模型(LLMs)的微调而设计。它具有高效且低成本、易于访问和使用、丰富的数据集选项、多样化的算法支持等特点。LLaMA-Factory的GitHub地址是:LLaMA-Factory
4. 微调
我是在百度飞桨上完成此次大模型微调工作的,所使用机器配置为:V100-32G,使用模型为:Meta-Llama-3-8B-Instruct。各位如果使用的GPU是V100-16G,可以选择使用更小一些的模型,比如Qwen2.5-3B-Instruct-GPTQ-Int8。本地部署的话可以根据自己的显卡性能来自我判断,在这里我贴一张图出来(来源于LLaMA-Factory),可以对比参考一下:
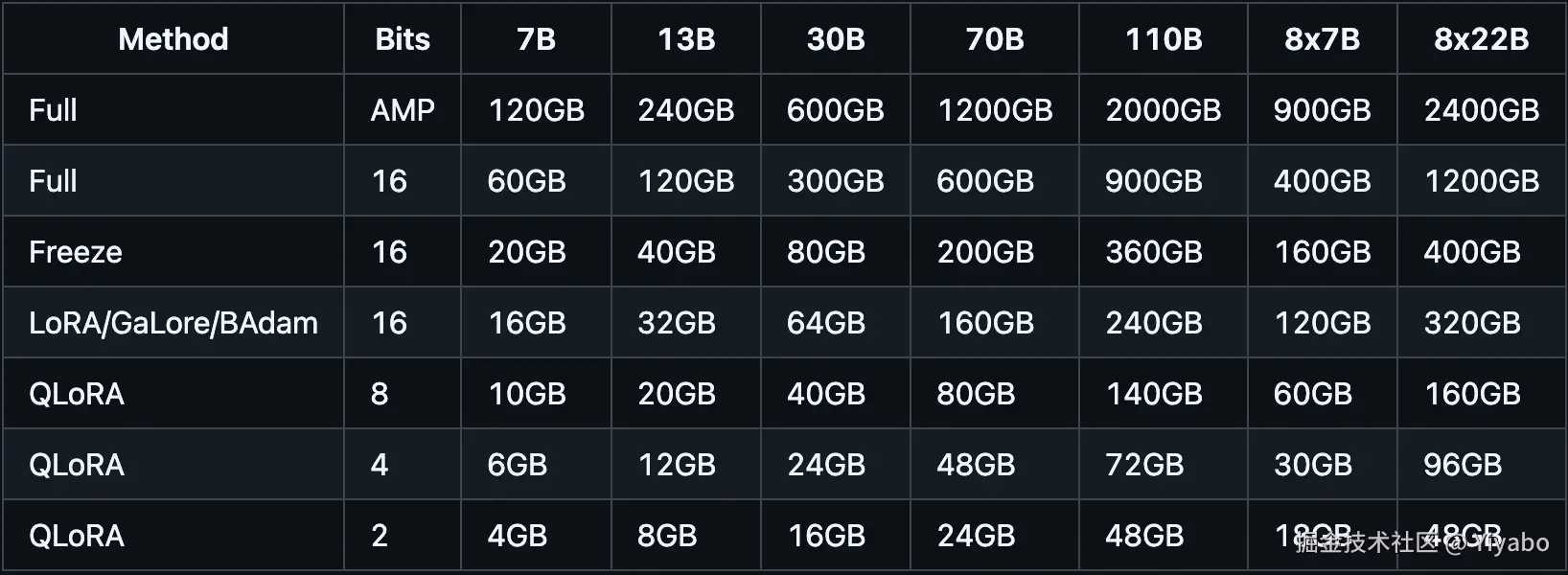
常见的模型获取网站:
一:环境配置
1. 硬件与驱动
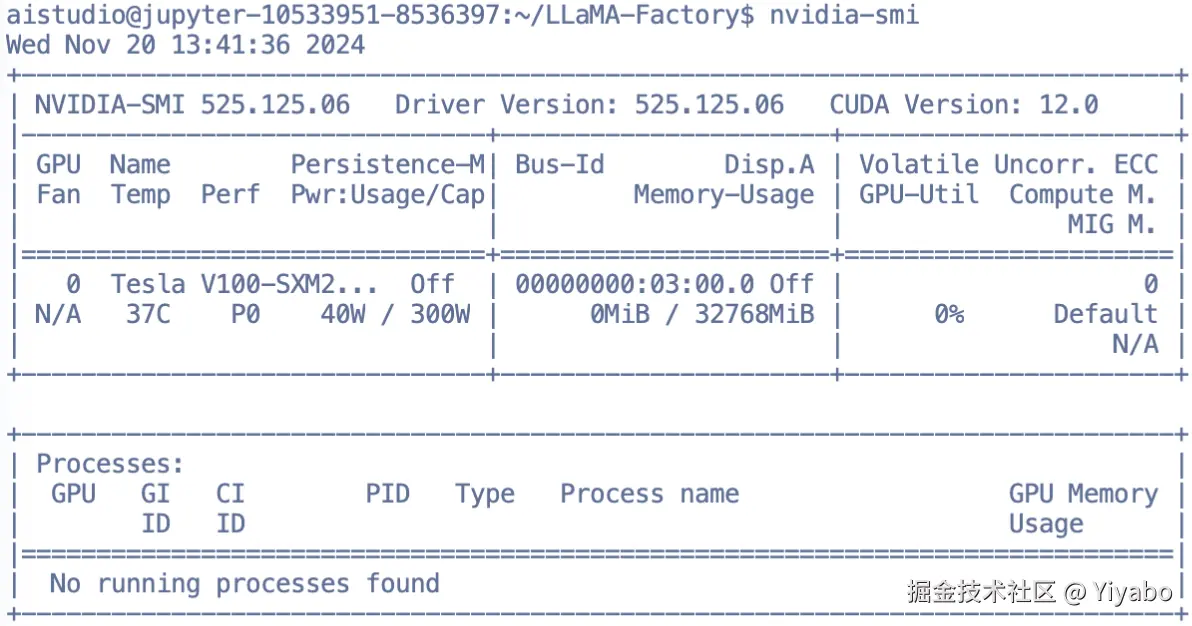
首先,需要确定一下显卡驱动和CUDA的是否有安装完成。这个教程网上有非常多,而且很详细,在此不多做深究。如果有同学确实是不会安装,我之后也可以再写一篇。我说使用的是百度飞桨提供的云环境,所以是已经安装好了的,各位同学可以使用这个命令进行一个简单的校验:
nvidia-smi
会出现如下输出,显示GPU的当前状况与一些配置信息:
2. 相关依赖
现在我们需要下载本次微调所使用到的开源项目LLaMA-Factory
- 使用git clone进行项目下载:
git clone https://github.com/hiyouga/LLaMA-Factory.git - 下载完成后,使用cd命令进入LLaMA-Factory目录下:
cd LLaMA-Factory - 安装相关依赖,这一步有两种选择
- 第一种:如果你使用的是自己的电脑,或者说是在本地环境下,我建议创建一个虚拟环境,避免破坏你原有的开发环境。我推荐使用conda,当然你也可以考虑使用其他的方式,在此不多做讨论。如果需要相关教程我也可以再出一个包括conda在内的各式各样创建虚拟环境的方法。
- 第二种:如果你是像我一样使用的云端开发环境,比如colab、kaggle、百度飞桨这些,那你可以不去创建虚拟环境。创建虚拟环境的目的在第一条已经说明了,各位同学可以根据自己的实际情况来判断是否需要进行创建。在这大模型中微调操作中我是没有创建虚拟环境的。
- 此时假设你已经完成了上述两种判断,并且根据自己的情况进行了相应的操作。那么接下来可以使用该命令进行相关环境依赖的安装:
pip install -e '.[torch,metrics]' --user。–user这个可加可不加,如果你拥有你开发环境的root权限,那就可以考虑不加。但是如果你是像我一样在百度飞桨这种开发平台进行操作的,那还是加上比较好。
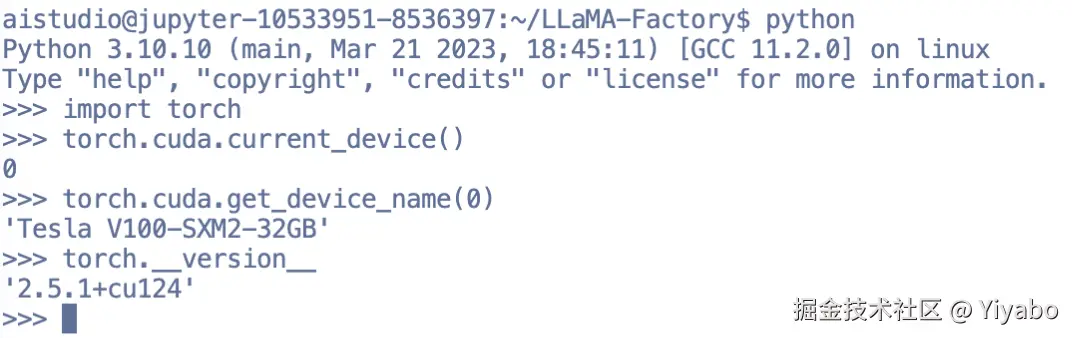
执行完上面三步后,再使用如下命令进行一个校验:
- 在终端输入 Python ,或直接使用某个代码编译器均可,执行如下命令:
import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__
若过程中未出现报错,并且输出结果与我的类似,那么便算通过:
- 在终端输入 llamafactory-cli train -h ,我随意截取了最后一段信息,此过程未报错便算通过:

至此,基本的开发环境已经搭建完成。
二:模型下载
下载模型方法有很多种,在上面的介绍中也有模型下载网站,各位可以去网站中自取。国内的小伙伴可以使用这个命令进行下载。不过在使用这个命令下载之前,各位还需要请确保 lfs 已经被正确安装:
git lfs install
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
这个命令会去 魔塔社区 下载 Meta-Llama-3-8B-Instruct 模型。在这里不给出 huggingface 相关下载方式了,相信你有能力访问它,就有能力去下载。如果你觉着自己的硬件不太行,那么咱可以用这个命令下载一个小一些的模型:
git clone https://www.modelscope.cn/Qwen/Qwen2.5-3B-Instruct-GPTQ-Int8.git
该命令会下载 Qwen2.5-3B-Instruct-GPTQ-Int8 模型,这个比上面那个8B的小多了。 如果用这俩命令无法下载模型,那你可能是因为 lfs 没有正确安装。此时比较好的方法是在网上搜寻相关教程进行安装,如果懒得装,也可以考虑使用下面这两种方法:
- 使用命令行下载
- 先安装ModelScope:在终端输入
pip install modelscope - 安装完毕后,再在终端输入
modelscope download --model Qwen/Qwen2.5-3B-Instruct-GPTQ-Int8安装 QWEN 模型,同理 Llama 模型也可以这么安装。
- 先安装ModelScope:在终端输入
- 使用SDK下载
- 在终端输入 python 或者打开一个代码编辑页面。运行下面代码
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-3B-Instruct-GPTQ-Int8')
- 直接打开对应网站,手动进行下载(新手记得要下载全)
下载完后记得检查一下模型下载是否完整,可以进入对应文件目录用du -sh *看看一看:

三:使用原始模型进行推理
我们先试一试不进行微调,直接用刚刚下载的模型进行推理会是什么结果,在终端输入如下命令。(这个命令比较有讲究,各位最好去LLaMA-Factory仔细读一读):
llamafactory-cli chat \
--model_name_or_path /home/aistudio/Meta-Llama-3-8B-Instruct \
--template llama3
所有功能的入口全都是 llamafactory-cli ,然后根据你的不同要求,增减不同的参数,下面是部分命令表格(详细参数和教程可以查阅官方文档):
| 参数名称 | 功能描述 |
|---|---|
| model_name_or_path | 指定使用的模型名称或模型文件的路径。 |
| chat | 启用命令行模式,允许用户通过命令行接口与模型交互。 |
| webui | 启用Web界面模式,提供图形用户界面以方便用户操作。 |
| finetuning_type | 选择微调方式,可选值为freeze(冻结参数)、lora(LoRA方法)和full(全参数微调)。 |
| lora_target | 设置采用LoRA方法的目标模块,如果未指定,则默认作用于所有模块(all)。 |
| dataset | 指定使用的数据集,多个数据集可以用逗号“,”分隔。 |
| template | 指定数据集模板,确保所选模板与模型兼容。 |
| output_dir | 指定输出目录,用于保存训练结果和其他输出文件。 |
执行上述命令后,经过一系列的模型加载,最终会在终端出现信息(这个是我提问之后的,刚刚启动时只有一个 User):

如果将命令中的 llamafactory-cli chat改成llamafactory-cli webchat,那么就会有一个基于gradio开发的ChatBot推理页面,也就是所谓的网页版本。不过我使用的是云端开发,所以配置会稍微麻烦一点,在这里用命令行版本进行一个演示。如果你是在本地进行部署,那么可以尝试使用 webchat ,运行完后在终端可以看见对应的链接,点击或者复制再粘贴到浏览器打开即可。一般而言,可以通过 http://localhost:7860/ 进行访问。
四:构建自定义数据集
目前 LLaMA-Factory 支持 Alpaca 格式和 ShareGPT 格式的数据集。 在这次微调训练中,我们使用指令监督微调。 这种json类型的训练数据格式如下:
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)"
}
- instruction:用户进行的一个要求,通常是对系统或模型的直接命令,指示它需要执行的具体任务或动作。
- input:系统接收到的数据或信息,这是执行指令所需的原材料。输入可以是文本、图像、音频或其他任何形式的数据,具体取决于指令的性质和系统的处理能力。
- output:系统处理输入后产生的结果。输出是指令执行的直接产物,可以是分析结果、生成的文本、修改后的图像或任何其他形式的响应。
本次教程我们简单对大模型的自我认知进行一个微调,我们可以在 LLaMA-Factory 文件目录下的 data 文件目录中找到 identity.json 文件,这个是系统自带的数据集(已经默认在 LLaMA-Factory/data/dataset_info.json 注册为identity)
接下来我们进行一个文本替换:
-
如果是windows用户,那么你需要手动使用编辑器打开 identity.json 文件,然后找到替换其中的NAME 和 AUTHOR 。
-
如果是 Linux 用户,那么可以使用 sed 完成快速替换
sed -i 's/{{name}}/刚刚微调出来的模型/g' data/identity.jsonsed -i 's/{{author}}/Yiyabo/g' data/identity.json替换前:
{ "instruction": "Who are you?", "input": "", "output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?" }替换后:```
{
“instruction”: “Who are you?”,
“input”: “”,
“output”: “Hello! I am 刚刚微调出来的模型, an AI assistant developed by Yiyabo. How can I assist you today?”
}
至此,微调之前的准备工作都已经做完了。
五:开始微调
在构建微调数据集的时候已经说明了,本次是使用指令监督微调,然后为了尽量减少对硬件的要求,咱们用的是Lora。 在终端输入:
llamafactory-cli train \
--stage sft \
--do_train \
--model_name_or_path /home/aistudio/Meta-Llama-3-8B-Instruct \
--dataset identity \
--dataset_dir ./data \
--template llama3 \
--finetuning_type lora \
--output_dir ./saves/LLaMA3-8B/lora/sft \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 1024 \
--preprocessing_num_workers 16 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 50 \
--warmup_steps 20 \
--save_steps 100 \
--eval_steps 50 \
--evaluation_strategy steps \
--load_best_model_at_end \
--learning_rate 5e-5 \
--num_train_epochs 5.0 \
--max_samples 1000 \
--val_size 0.1 \
--plot_loss \
--fp16
| 参数名称 | 功能描述 |
|---|---|
| stage | 表示当前训练阶段的枚举值,包括 sft(有监督指令微调)、pt、rm、ppo等。在我们的案例中,我们关注的是有监督指令微调阶段,即 sft。 |
| do_train | 指示是否处于训练模式。 |
| dataset | 指定使用的数据集列表,所有数据集必须在 data_info.json 中注册,多个数据集以逗号“,”分隔。本次微调仅使用了 identity.json 文件。 |
| dataset_dir | 指定数据集所在的目录路径,本例中为 data ,即项目内嵌的 data 目录。 |
| finetuning_type | 微调训练的类型,可选枚举值包括 lora(低秩适应)、full(全参数微调)和freeze(冻结参数)。本例中使用的是 lora。 |
| output_dir | 指定训练结果的保存路径。 |
| cutoff_len | 定义训练数据集的长度截断阈值。 |
| per_device_train_batch_size | 设置每个设备上的训练批次大小(batch size),最小值为1。如果GPU显存充足,可以适当增加以提高训练效率。 |
| fp16 | 启用半精度混合精度训练,以加速训练过程并减少显存占用。 |
| max_samples | 定义每个数据集中采样的数据量。 |
| val_size | 指定从数据集中随机抽取的比例,用作验证集。 |
特别注意V100无法支持bf16,望周知。
终端输出下面信息即代表微调结束:
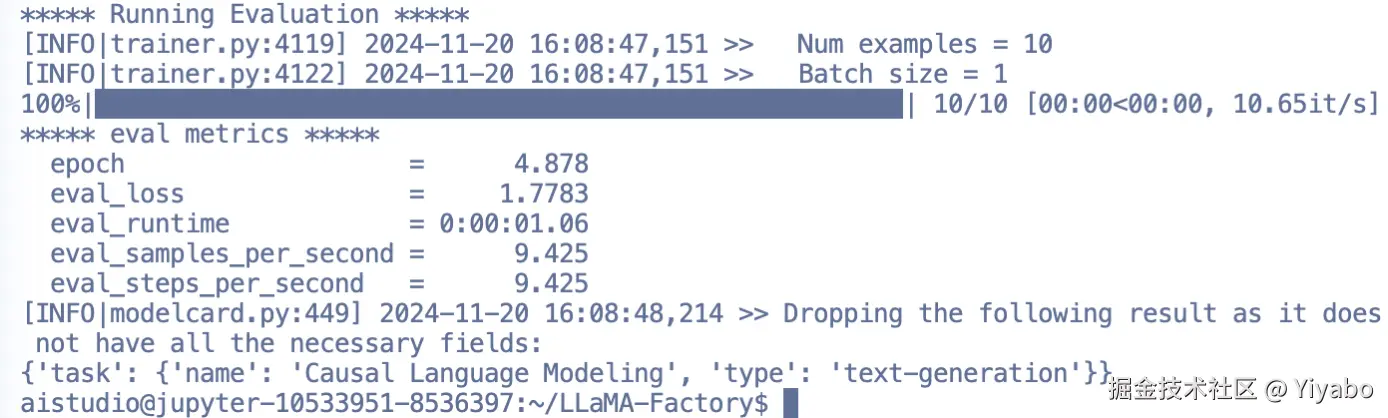
从结果来看,微调是成功的。关键指标如下:
-
eval_loss = 1.7783:这是评估集上的损失值,表明模型在评估数据上的性能,数值越低越好。
-
eval_samples_per_second 和 eval_steps_per_second:表明评估的效率。
-
日志中未丢失必要字段:task 信息明确,微调的任务类型为因果语言建模。
六:合并Lora进行模型推理
当训练结束后,咱可以进行一下验证,在终端输入:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat \
--model_name_or_path /home/aistudio/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type lora
接下来各位同学可以查看下微调后的效果:

我在这里整蛊了一下同学,为了避免隐私泄露所以给打了码😂
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









