






LlamaIndex 是一个用于构建上下文增强型 LLM应用的强大框架,能够帮助开发者高效创建能够与私有数据交互的 LLM 应用。本文介绍了 LlamaIndex 的核心功能及其应用示例(以文档检索智能问答应用为例),具体内容如下:
- 基础概念:上下文增强、智能体、工作流。
- LlamaIndex 的核心功能、工具、适用人群。
- LlamaIndex 的安装步骤:LlamaIndex 包安装,轻量级的嵌入模型下载(附下载链接)。
- LlamaIndex 的应用示例:以文档检索智能问答应用为例,包括应用实现的流程步骤、python 代码实现。
LlamaIndex 在 github 项目已有 39.6K stars:https://github.com/run-llama/llama_index,官网文档为:https://docs.llamaindex.ai/en/stable/
基础概念
在当今的技术浪潮中,大型语言模型(LLMs)正以前所未有的速度改变着我们与数据交互的方式。通过大模型与我们的数据交互,涉及三个核心概念:上下文增强、智能体与工作流。
上下文增强:让数据真正为LLMs所用
上下文增强(context augmentation),这一技术的核心在于为 LLMs 提供额外的数据,使其能够更精准地解决问题。LLMs 本身已在海量公开数据上预训练,但它们并未直接使用我们的私有数据进行训练。我们的私有数据可能隐藏在 API 背后、SQL数据库中,或是在PDF、PPT 等文件中。 上下文增强技术应运而生,它使私有数据能够被 LLMs 利用,从而解决特定问题。检索增强生成(RAG)是上下文增强的典型示例,它在推理时将上下文与 LLMs 结合使用,极大地提升了模型的准确性和相关性。
智能体:LLMs驱动的智能助手
智能体(agents),即由 LLMs 驱动的知识助手,能够利用各种工具执行诸如搜索、数据提取等任务。智能体(agents)的应用范围从简单的问答系统到复杂的任务执行(感知、决策并采取行动以完成任务)。
工作流:多步骤任务的协同执行
工作流(workflows)是更为复杂的过程,它结合了一个或多个智能体(agent)、数据连接器和其他工具,以完成多步骤的任务。工作流是事件驱动的软件,可以整合 RAG 数据源和多个智能体,创建复杂应用程序,以执行各种复杂任务。 基于工作流创建的应用程序具备反思、错误纠正等高级特性,是先进 LLM 应用的标志。我们可以将工作流部署为生产微服务,从而在实际业务场景中发挥其强大的功能。
LlamaIndex:上下文增强型LLM应用的框架
LamaIndex 是一个用于构建上下文增强型 LLM应用 的强大框架,能够帮助开发者创建能够与私有数据交互的 LLM 应用。
核心作用
LlamaIndex 的核心作用如下
- 解决 LLM 的局限性:直接使用 LLM 处理私有或动态数据时存在局限性(如知识截断、无法访问最新数据等),LlamaIndex 充当“中间层”,将外部数据与 LLM 无缝衔接。
- 检索增强生成(RAG):通过检索外部数据中的相关信息,辅助 LLM 生成更准确、可靠的回答,减少“幻觉”现象。
️核心工具
LlamaIndex 提供了以下核心工具:
- 数据连接器(Data Connectors):LlamaIndex 支持导入多种数据源,包括 PDF 文档、Word 文档、Markdown 文件、网页内容、API数据、数据库等
- 数据索引(Data Indexes):将数据转换为易于 LLM 高效处理的中间表示形式(如向量、树状结构等)。
- 引擎(Engines):为数据提供自然语言交互接口,例如:
- 查询引擎:面向问答场景的强大接口(例如检索增强生成(RAG)管道)。
- 聊天引擎:支持多轮对话的交互式接口,实现与数据的"一问一答"式交流。
- 智能体(Agents):通过工具增强的 LLM 知识助手,支持从简单的功能辅助到 API 集成等多种能力。
- 可观察性/评估集成(Observability/Evaluation Integrations):提供性能评估和成本分析工具,帮助你优化应用性能和控制成本
- 工作流(Workflows):将上述所有组件组合成事件驱动系统,其灵活性远超传统的基于图(graph-based)的架构方案。
适用人群
LlamaIndex 的适用人群包括以下几类:
- 初学者:可以使用高级API,仅需 5 行代码即可实现基本功能。
- 进阶用户:可以自定义和扩展任何模块,包括数据连接器、索引、检索器、查询引擎和重新排序模块。
- 企业用户:提供完整的生产级解决方案,适用于需要构建企业级LLM应用的场景。
安装步骤
使用 LlamaIndex 时,通常需要与 LlamaIndex 核心和选定的集成集(或插件)配合使用。在 Python 中使用 LlamaIndex时,有以下两种开始构建的方式:
- 入门包:llama-index。包含 LlamaIndex 核心功能和一些功能的集成包。
- 定制化包:llama-index-core。安装 LlamaIndex 核心,并在LlamaHub上添加你的应用程序所需的 LlamaIndex集成包。有超过 300 个 LlamaIndex 集成包可与核心无缝协作,可以使用自己偏好的 LLM、嵌入模型和向量存储。
lamaIndex Python 库是命名空间化的,这意味着导入语句中包含core的部分表示正在使用核心包,而不包含core的部分表示正在使用集成包。如:
- from http://llama_index.core.xxx import ClassABC:从核心子模块xxx中导入类ClassABC。
- from llama_index.xxx.yyy import SubclassABC:从子模块xxx的集成部分yyy中导入类SubclassABC
# typical pattern
from llama_index.core.xxx import ClassABC
from llama_index.xxx.yyy import (
SubclassABC,
)
# 具体示例
from llama_index.core.llms import LLM
from llama_index.llms.openai import OpenAI
LlamaIndex 的 python 包安装
在终端运行 pip install llama-index 安装 LlamaIndex。
pip install llama-index
llama-index 是一个入门集成包,包含了以下 packages:
- llama-index-core
- llama-index-llms-openai
- llama-index-embeddings-openai
- llama-index-program-openai
- llama-index-question-gen-openai
- llama-index-agent-openai
- llama-index-readers-file
- llama-index-multi-modal-llms-openai
若要调用 DeepSeek 模型服务,我们还需要安装 llama-index-llms-deepseek:
pip install llama-index-llms-deepseek
安装 llama_index.embeddings.huggingface,用于调用 huggingface 的嵌入模型。
pip install llama_index.embeddings.huggingface
嵌入模型下载
本文的应用示例,使用 huggingface 上的 BAAI 的嵌入模型。以下两个是轻量级的嵌入模型:
- BAAI/bge-small-en-v1.5 : https://huggingface.co/BAAI/bge-small-en-v1.5
- BAAI/bge-small-zh-v1.5 : https://huggingface.co/BAAI/bge-small-zh-v1.5
使用 huggingface-cli 命令,将嵌入模型下载到本地:
huggingface-cli download --resume-download BAAI/bge-small-en-v1.5 --local-dir bge-small-en-v1.5
huggingface-cli download --resume-download BAAI/bge-small-zh-v1.5 --local-dir bge-small-zh-v1.5
由于科学上网的原因,上面的两个嵌入模型可能不好下载。海哥已经从 huggingface 下载好了。关注我,发送消息:“嵌入模型”,获取下载链接。
以文档检索智能问答应用
应用场景:针对用户提出的问题,检索一篇论文,大模型根据检索到的内容,回答用户的问题。 要通过 LlamaIndex 实现上面的场景,首先我们要理解以下两类模型:
- 语言模型(LLM):用于生成文本(如 DeepSeek、Qwen)。
- 嵌入模型(Embedding Model):用于将文本转换为向量(如 text-embedding-3-small、bge-large)。
应用的流程步骤如下:
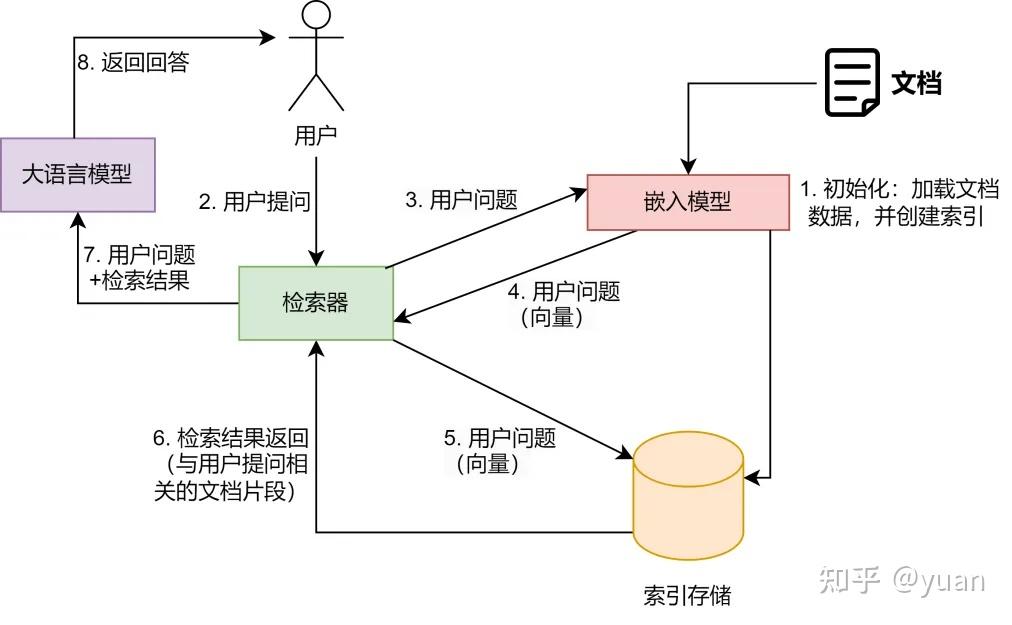
- 初始化:文档数据被加载;嵌入模型将文档内容转换为向量表示;向量存储在索引存储中。
- 用户提问:用户提出问题。
- 用户问题向量化:检索器使用嵌入模型将用户问题转换为向量表示。
- 检索结果:检索器在索引存储中找到与用户问题最相关的文档片段。
- 将用户问题 + 检索结果输入到语言模型:大语言模型接收用户问题和检索到的文档片段。
- 返回针对用户问题的回答:大语言模型根据用户问题和检索到的文档片段生成最终的回答;用户接收大语言模型生成的回答。
以检索一篇 RAG 论文为例:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(https://arxiv.org/pdf/2005.11401),该论文在 RAG 领域具有重要的地位,系统性地总结了 RAG 技术的关键组件和应用。感兴趣的读者可以阅读一下。 python 代码如下:
、# 导入所需库
from llama_index.llms.deepseek import DeepSeek
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
import os
# 从环境变量获取 DeepSeek API Key
api_key = os.environ["DS_API_KEY"]
# 配置本地嵌入模型路径(已下载的 BGE 英文小模型)
embed_model_path = 'D:\\DevelopTools\\huggingface_model\\baai\\bge-small-en-v1.5'
# 初始化 DeepSeek 语言模型
llm = DeepSeek(model="deepseek-chat", api_key=api_key)
# 全局配置设置
Settings.llm = llm # 绑定语言模型(用于生成回答)
# 绑定嵌入模型(用于生成向量)
Settings.embed_model = HuggingFaceEmbedding(
model_name=embed_model_path,
cache_folder=embed_model_path
)
# 加载本地文档数据("data" 目录下的 paper)
documents ="data").load_data()
# 创建向量索引(自动使用配置的嵌入模型生成向量)
index = VectorStoreIndex.from_documents(documents)
# 创建查询引擎(单次问答模式)
query_engine = index.as_query_engine()
# 执行查询并打印结果
response = query_engine.query("介绍一下 RAG-Sequence Model")
print(response)
若要将上面的代码,改造成用户与大模型的多轮对话交互,代码如下:
from llama_index.llms.deepseek import DeepSeek
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader, StorageContext
from llama_index.core.chat_engine import ContextChatEngine # 支持上下文的聊天引擎
import os
def main():
# 环境配置
api_key = os.environ.get("DS_API_KEY")
if not api_key:
raise ValueError("未找到环境变量 DS_API_KEY")
# 模型路径配置
embed_model_path = 'D:\\DevelopTools\\huggingface_model\\baai\\bge-small-en-v1.5'
data_dir = "data" # 文档数据目录
# 初始化模型
try:
# 语言模型(DeepSeek)
llm = DeepSeek(model="deepseek-chat", api_key=api_key)
# 嵌入模型(本地加载)
embed_model = HuggingFaceEmbedding(
model_name=embed_model_path,
cache_folder=embed_model_path,
device="cpu" # 可选:指定使用 CPU/GPU
)
# 全局设置
Settings.llm = llm
Settings.embed_model = embed_model
except Exception as e:
print(f"模型初始化失败: {str(e)}")
return
# 加载文档并创建索引
try:
documents = SimpleDirectoryReader(data_dir).load_data()
index = VectorStoreIndex.from_documents(documents)
except FileNotFoundError:
print(f"文档目录 {data_dir} 不存在")
return
except Exception as e:
print(f"索引创建失败: {str(e)}")
return
# 创建支持上下文的聊天引擎
chat_engine = index.as_chat_engine(
chat_mode="context", # 启用上下文模式
system_prompt="你是一个专业的技术助手,请基于提供的文档回答问题。", # 系统提示
verbose=True # 显示详细过程
)
# 多轮对话循环
print("欢迎使用文档问答助手!输入 'exit' 退出对话。")
while True:
try:
user_input = input("\n用户: ")
if user_input.lower() == "exit":
print("对话结束。")
break
# 生成响应(自动携带历史上下文)
response = chat_engine.chat(user_input)
print(f"\n助手: {response}")
except KeyboardInterrupt:
print("\n对话被中断。")
break
except Exception as e:
print(f"请求出错: {str(e)}")
if __name__ == "__main__":
main()
运行效果(准确地介绍了关于论文里的 RAG-Sequence Model、RAG-Token Model 两个概念):
D:\DevelopTools\pythonenv\llamaindex\Scripts\python.exe D:\python_project\llm_learning\llamaindex\query_about_paper.py
欢迎使用文档问答助手!输入 'exit' 退出对话。
用户: 介绍一下 RAG-Sequence Model
助手: RAG-Sequence Model 是一种用于生成文本的模型,它使用相同的检索文档来生成完整的序列。具体来说,RAG-Sequence Model 将检索到的文档视为一个单一的潜在变量,并通过 top-K 近似来边缘化这个变量,从而得到序列到序列的概率 \( p(y|x) \)。
具体步骤如下:
1. **检索文档**:使用检索器(retriever)检索出 top-K 个文档。
2. **生成序列概率**:对于每个检索到的文档,生成器(generator)生成输出序列的概率。
3. **边缘化**:将这些概率进行边缘化处理,得到最终的序列概率。
公式表示为:
\[
p_{\text{RAG-Sequence}}(y|x) \approx \sum_{z \in \text{top-k}(p(\cdot|x))} p_{\eta}(z|x) p_{\theta}(y|x,z) = \sum_{z \in \text{top-k}(p(\cdot|x))} p_{\eta}(z|x) \prod_{i} p_{\theta}(y_i|x,z,y_{1:i-1})
\]
其中,\( p_{\eta}(z|x) \) 是检索器给出的文档概率,\( p_{\theta}(y|x,z) \) 是生成器给出的序列概率。
RAG-Sequence Model 适用于需要从单一文档中生成完整序列的任务,例如问答系统或文本生成任务。
用户: 介绍一下 RAG-Token Model
助手: RAG-Token Model 是一种用于生成文本的模型,它允许为每个目标标记(token)选择不同的检索文档,并在生成过程中对这些文档进行边缘化处理。与 RAG-Sequence Model 不同,RAG-Token Model 在生成每个目标标记时可以选择不同的文档,从而在生成答案时能够从多个文档中提取内容。
具体步骤如下:
1. **检索文档**:使用检索器(retriever)检索出 top-K 个文档。
2. **生成标记概率**:对于每个检索到的文档,生成器(generator)生成下一个输出标记的概率。
3. **边缘化**:将这些概率进行边缘化处理,得到下一个标记的概率分布。
4. **重复过程**:重复上述过程,生成后续的输出标记。
公式表示为:
\[
p_{\text{RAG-Token}}(y|x) \approx \prod_{i} \sum_{z \in \text{top-k}(p(\cdot|x))} p_{\eta}(z|x) p_{\theta}(y_i|x,z,y_{1:i-1})
\]
其中,\( p_{\eta}(z|x) \) 是检索器给出的文档概率,\( p_{\theta}(y_i|x,z,y_{1:i-1}) \) 是生成器给出的下一个标记的概率。
RAG-Token Model 适用于需要从多个文档中提取信息来生成答案的任务,例如开放域问答系统或复杂的文本生成任务。通过为每个标记选择不同的文档,RAG-Token Model 能够更灵活地利用多个文档中的信息。
用户: exit
对话结束。如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









