







Keras训练模型有多种保存方法,可以保存为hdf5文件,也可以保存为json格式文件,可以同时保存模型图和权重,也可以单独保存模型图和权重,还可以保存为tensorflow-serving支持的pb格式。下面以一个简单的模型分别来介绍不同的保存方法。
模型图构建
下面用keras中函数式API构建一个简单的LSTM多分类模型,模型具体结构如下:
import keras
from keras.models import Sequential
from keras.layers import Input, Dense, Dropout, Embedding, LSTM
from keras.models import Model
from keras import backend as K
K.clear_session()
maxlen = 50
vocab_size = 1024
embedding_size = 128
hidden_size = 128
num_classes = 10
inputs = Input(shape=(maxlen,), name="inputs")
x = Embedding(input_dim=vocab_size, output_dim=embedding_size)(inputs)
x = LSTM(units=hidden_size)(x)
x = Dropout(rate=0.5)(x)
outputs = Dense(num_classes, activation='softmax', name="outputs")(x)
model = Model(inputs=inputs, outputs=outputs)
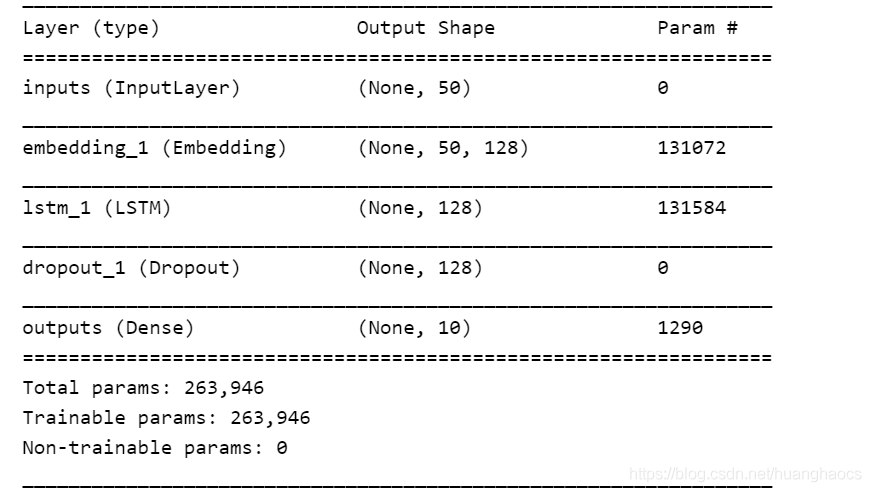
print(model.summary())
模型结构图如下:
训练模型
这里只是一个训练示例,为了减小数据预处理的过程,我们直接用随机产生的虚拟数据。
# 生成虚拟数据
import numpy as np
data = np.random.randint(vocab_size 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4279
4279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









