







- 命令行手册: README_CLI.md
- HTTP接口手册: README_HTTP.md
HTTP接口手册
(本文档仅适用于 Umi-OCR 最新版本。旧版本请查看 Github备份分支 中对应版本的文档。)
基础说明

如上图,必须允许HTTP服务才能使用HTTP接口(默认开启)。如果需要允许被局域网访问,请将主机切换到任何可用地址。
在全局设置页中勾选高级才会显示。
注意事项:
- 关闭 Umi-OCR 软件时,如果仍有用户未断开HTTP接口连接,可能导致Umi-OCR关闭不完全(UI线程结束了,但负责网络的子线程未被关闭)。这时只能等待所有用户关闭连接,或者进任务管理器强制结束进程。
- 由于后端组件的性能限制,对并发支持较差,尽量不要并发调用。
- 由于后端组件的性能限制,在长时间、大批量、连续调用时,有小几率出现
Error: connect ECONNREFUSED之类的HTTP报错。此时重新发起请求即可。只要后台工作线程没有崩,这些小问题不会持续影响调用。
目录
1. 图片OCR:Base64 识别接口
传入一个base64编码的图片,返回OCR识别结果。
URL:/api/ocr
例:http://127.0.0.1:1224/api/ocr(实际端口请在全局设置中查看)
1.1. 请求格式
方法:POST
参数:json
| 参数名 | 类型 | 描述 |
|---|---|---|
| base64 | string | 待识别图像的 Base64 编码字符串,无需前缀 |
| options | object | 【可选】配置选项字典 |
base64无需data:image/png;base64,等前缀,直接放正文。options是可选的,可以不传这个参数。如果传了,则内部的所有子参数也均为可选。
参数示例:
{
"base64": "iVBORw0KGgoAAAAN……",
"options": {
# 通用参数
"tbpu.parser": "multi_para",
"data.format": "json",
# 引擎参数
"ocr.angle": false,
"ocr.language": "简体中文",
"ocr.maxSideLen": 1024
}
}
options 中有两部分参数:通用参数 和 引擎参数 。
通用参数 是在任何情况下都适用的,选项:
data.format:数据返回格式。返回值字典中,["data"]按什么格式表示OCR结果数据。可选值(字符串):dict:含有位置等信息的原始字典(默认)text:纯文本
tbpu.parser:排版解析方案。可选值(字符串):multi_para:多栏-按自然段换行(默认)multi_line:多栏-总是换行multi_none:多栏-无换行single_para:单栏-按自然段换行single_line:单栏-总是换行single_none:单栏-无换行single_code:单栏-保留缩进,适用于解析代码截图none:不做处理
tbpu.ignoreArea:忽略区域功能。传入一些矩形框,位于这些矩形框内部的文字块将会被忽略。- 外层格式:列表
[],每项表示一个矩形框。 - 内层格式:列表
[[x1,y1],[x2,y2]],其中x1,y1是矩形框左上角坐标,x2,y2是右下角坐标。 - 示例:假设忽略区域包含3个矩形框,那么
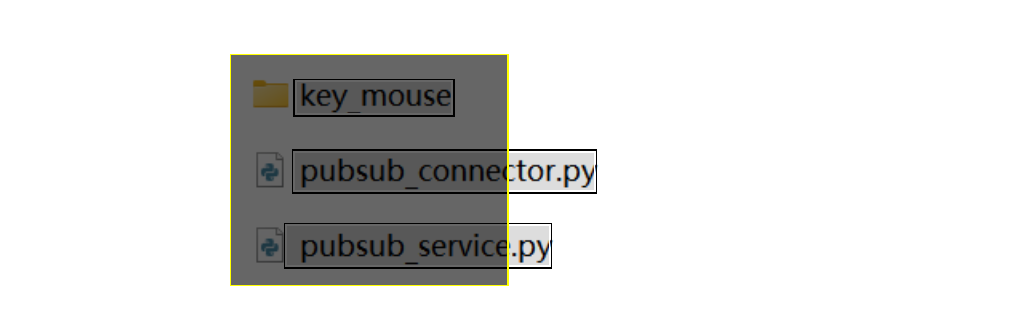
tbpu.ignoreArea的格式类似:[ [[0,0],[100,50]], // 第1个框,左上角(0,0),右下角(100,50) [[0,60],[200,120]], // 第2个 [[400,0],[500,30]] // 第3个 ] - 注意,只有处于忽略区域框内部的整个文本块(而不是单个字符)会被忽略。如下图所示,黄色边框的深色矩形是一个忽略区域。那么只有
key_mouse才会被忽略。pubsub_connector.py、pubsub_service.py这两个文本块得以保留。
- 外层格式:列表
引擎参数 对于加载不同引擎插件时,可能有所不同。完整参数说明请通过 get_options 接口查询。以下是一些示例:
| PaddleOCR 引擎参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
ocr.language |
string | models/config_chinese.txt |
识别语言。可选值请通过 get_options 接口查询 |
ocr.cls |
boolean | false |
是否进行图像旋转校正。true/false |
ocr.limit_side_len |
int | 960 |
图像压缩边长。允许 960/2880/4320/999999 |
| RapidOCR 引擎参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
ocr.language |
string | 简体中文 |
识别语言。可选值请通过 get_options 接口查询 |
ocr.angle |
boolean | false |
是否进行图像旋转校正。true/false |
ocr.maxSideLen |
int | 1024 |
图像压缩边长。允许 1024/2048/4096/999999 |
1.2. 响应格式
json
| 字段名 | 类型 | 描述 |
|---|---|---|
| code | int | 任务状态。100为成功,101为无文本,其余为失败 |
| data | list/string | 识别结果,格式见下 |
| time | double | 识别耗时(秒) |
| timestamp | double | 任务开始时间戳(秒) |
data 格式
图片中无文本(code==101),或识别失败(code!=100 and code!=101)时:
["data"]为string,内容为错误原因。例:{"code": 902, "data": "向识别器进程传入指令失败,疑似子进程已崩溃"}
识别成功(code==100)时,如果options中data.format为dict(默认值):
["data"]为list,每一项元素为dict,包含以下子元素:
| 参数名 | 类型 | 描述 |
|---|---|---|
| text | string | 文本 |
| score | double | 置信度 (0~1) |
| box | list | 文本框顺时针四个角的xy坐标:[左上,右上,右下,左下] |
| end | string | 表示本行文字结尾的结束符,根据排版解析得出。可能为空、空格、换行。 |
结果示例:
{
"code": 100,
"data": [
{
"text": "第一行的文本,",
"score": 0.99800001,
"box": [[x1,y1], [x2,y2], [x3,y3], [x4,y4]],
"end": "",
},
{
"text": "第二行的文本",
"score": 0.97513333,
"box": [[x1,y1], [x2,y2], [x3,y3], [x4,y4]],
"end": "\n",
},
]
}
识别成功(code==100)时,如果options中data.format为text:
["data"]为string,即所有OCR结果的拼接。例:
"data": "第一行的文本,第二行的文本\n"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









