











前言:本文记录了我在地平线RDK X5开发板上部署YOLOv11n模型的完整过程,包括遇到的性能瓶颈、问题诊断、解决方案探索,以及最终实现47 FPS实时检测的全过程。希望能帮助遇到类似问题的开发者少走弯路。
📋 目录
- 一、问题的发现:第一次部署的惨痛失败
- 二、环境准备:从零开始搭建
- 三、第一次量化尝试:按部就班却失败
- 四、性能瓶颈诊断:揪出元凶Softmax
- 五、寻找解决方案:社区资源研究
- 六、正确的部署流程:从ONNX到bin
- 七、实际测试:性能达标!
- 八、完整代码:可直接运行
- 九、踩坑总结与优化建议
一、问题的发现:第一次部署的惨痛失败
1.1 初始期望
当我拿到RDK X5开发板,准备部署最新的YOLOv11n模型时,心里是充满期待的:
- 硬件配置:RDK X5搭载Bayes-e架构BPU,理论算力10 TOPS
- 参考对象:官方YOLOv5s示例可以跑到180 FPS
- 模型选择:YOLOv11n(2.6M参数),比YOLOv5s还轻量
- 理论推算:按理说应该能达到100+ FPS才对
1.2 现实打脸
按照常规流程(导出ONNX → PTQ量化 → 板端部署)完成后,实际性能让我傻眼了:
BPU推理延迟:126ms
端到端FPS:7.67
这完全无法接受! 同样的硬件,YOLOv5能跑180 FPS,YOLOv11只有7 FPS?性能相差了23倍!
1.3 迷茫期
当时的心情可以用"崩溃"来形容:
- ❌ 量化精度没问题(余弦相似度>0.99)
- ❌ 后处理很快(12-14ms)
- ❌ 检测功能完全正常
- ❌ 但就是慢得令人发指
网上搜索"RDK X5 YOLOv11 慢"、"地平线 BPU性能问题",结果寥寥无几。一度怀疑是不是YOLOv11根本不适合这个平台?
二、环境准备:从零开始搭建
2.1 硬件环境
开发主机:Ubuntu 22.04 虚拟机(无NVIDIA显卡,纯CPU)
目标设备:RDK X5开发板
连接方式:局域网SSH (IP: 192.168.43.7)
摄像头:USB摄像头 (640x480)
显示器:HDMI显示器
2.2 Ubuntu虚拟机环境配置
2.2.1 创建工作目录
# 创建项目根目录
mkdir -p ~/rdk_x5_deploy
cd ~/rdk_x5_deploy
# 创建子目录结构
mkdir -p models # 存放ONNX模型
mkdir -p calibration_data # 校准数据集
mkdir -p output # 量化输出
2.2.2 安装Python环境
# 创建虚拟环境(推荐使用Python 3.10)
python3 -m venv yolo_env
source yolo_env/bin/activate
# 安装Ultralytics(YOLOv11官方库)
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装其他依赖
pip install opencv-python numpy onnx -i https://pypi.tuna.tsinghua.edu.cn/simple
注意事项:
- 虚拟机至少分配8GB内存
- 硬盘预留50GB空间(Docker镜像较大)
- 网络需要能访问GitHub(下载模型权重)
2.2.3 下载地平线工具链
cd ~/rdk_x5_deploy
# 下载OpenExplorer工具链(约2GB)
# 方式1:从官网下载(需要注册登录)
# https://developer.d-robotics.cc/
# 方式2:使用wget(如果有直链)
# wget <工具链下载链接>
# 解压工具链
tar -xzf horizon_x5_open_explorer_v1.2.8-py310_20240926.tar.gz
# 验证文件结构
ls horizon_x5_open_explorer_v1.2.8-py310_20240926/
# 应该看到:docker_images/, samples/, tools/ 等目录
2.2.4 加载Docker镜像
cd horizon_x5_open_explorer_v1.2.8-py310_20240926/docker_images
# 加载Docker镜像(约10分钟)
docker load < openexplorer_ai_toolchain_ubuntu_20_x5_cpu_v1.2.8-py310.tar.gz
# 验证镜像加载成功
docker images | grep openexplorer
# 应该看到:
# openexplorer/ai_toolchain_ubuntu_20_x5_cpu v1.2.8-py310
2.2.5 创建Docker启动脚本
cd ~/rdk_x5_deploy
# 创建启动脚本
cat > start_oe_docker.sh << 'EOF'
#!/bin/bash
# RDK X5 OpenExplorer Docker 启动脚本
# 将宿主机目录挂载到Docker容器的/data目录
docker run -it --rm \
-v $(pwd):/data \
--name oe_toolchain \
openexplorer/ai_toolchain_ubuntu_20_x5_cpu:v1.2.8-py310 \
/bin/bash
EOF
chmod +x start_oe_docker.sh
echo "✅ Docker环境准备完成"
2.3 准备校准数据集
量化需要代表性的校准数据。这里使用COCO数据集的验证集。
# 激活虚拟环境
cd ~/rdk_x5_deploy
source yolo_env/bin/activate
# 创建校准数据准备脚本
cat > prepare_calibration.py << 'EOF'
#!/usr/bin/env python3
"""
准备PTQ量化的校准数据集
从COCO验证集中提取100张图片,转换为640x640的RGB float32格式
"""
import os
import cv2
import numpy as np
from glob import glob
def letterbox_resize(img, target_size=640):
"""
Letterbox缩放:保持宽高比,填充到目标尺寸
这与YOLO训练时的预处理方式一致
"""
h, w = img.shape[:2]
scale = min(target_size / h, target_size / w)
new_h, new_w = int(h * scale), int(w * scale)
# 缩放图片
resized = cv2.resize(img, (new_w, new_h), interpolation=cv2.INTER_LINEAR)
# 创建灰色画布
canvas = np.full((target_size, target_size, 3), 114, dtype=np.uint8)
# 居中粘贴
top = (target_size - new_h) // 2
left = (target_size - new_w) // 2
canvas[top:top+new_h, left:left+new_w] = resized
return canvas
def prepare_calibration_data(image_dir, output_dir, target_size=640, num_images=100):
"""
准备校准数据集
参数:
image_dir: 输入图片目录(COCO val2017)
output_dir: 输出目录
target_size: 目标尺寸(640x640)
num_images: 校准图片数量(建议100张)
"""
os.makedirs(output_dir, exist_ok=True)
# 查找所有图片
image_files = glob(os.path.join(image_dir, '*.jpg')) + \
glob(os.path.join(image_dir, '*.png'))
if len(image_files) == 0:
print(f"❌ 在 {image_dir} 中未找到图片")
return
# 限制数量
image_files = image_files[:num_images]
print(f"开始处理 {len(image_files)} 张图片...")
for i, img_path in enumerate(image_files):
# 读取图片(BGR格式)
img = cv2.imread(img_path)
if img is None:
print(f"⚠️ 跳过损坏的图片: {img_path}")
continue
# 转换为RGB
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Letterbox resize
img_resized = letterbox_resize(img_rgb, target_size)
# 转换为CHW格式 (Channels, Height, Width)
# PyTorch/ONNX默认使用NCHW格式
img_chw = img_resized.transpose(2, 0, 1) # HWC -> CHW
# 转换为float32(不归一化,量化工具会自动处理)
img_float = img_chw.astype(np.float32)
# 保存为二进制文件
output_path = os.path.join(output_dir, f'{os.path.basename(img_path).split(".")[0]}.rgb')
img_float.tofile(output_path)
if (i + 1) % 10 == 0:
print(f" 进度: {i+1}/{len(image_files)}")
print(f"\n✅ 校准数据准备完成")
print(f" 输出目录: {output_dir}")
print(f" 文件数量: {len(image_files)}")
print(f" 文件格式: RGB float32, shape=(3, 640, 640)")
if __name__ == '__main__':
# 配置路径
COCO_DIR = '/path/to/coco/val2017' # 请修改为实际的COCO路径
OUTPUT_DIR = './calibration_data'
# 如果没有COCO数据集,可以使用任意100张图片
# 建议选择与实际应用场景相似的图片
prepare_calibration_data(
image_dir=COCO_DIR,
output_dir=OUTPUT_DIR,
num_images=100
)
EOF
chmod +x prepare_calibration.py
# 运行脚本(需要修改COCO路径)
python prepare_calibration.py
校准数据要求:
- ✅ 数量:20-100张(推荐100张)
- ✅ 场景:覆盖实际应用场景
- ✅ 质量:避免过曝、全黑、模糊图片
- ✅ 格式:RGB float32, CHW, 640x640
2.4 下载YOLOv11n预训练权重
cd ~/rdk_x5_deploy
# 方式1:使用Ultralytics自动下载
python -c "from ultralytics import YOLO; YOLO('yolo11n.pt')"
# 方式2:手动下载(如果网络受限)
wget https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt
# 验证文件
ls -lh yolo11n.pt
# 应该看到约5.4MB的文件
三、第一次量化尝试:按部就班却失败
3.1 导出ONNX模型(第一版 - 错误的)
一开始,我按照常规方法导出ONNX:
# export_yolo11n_v1.py - 第一版(会导致性能问题)
from ultralytics import YOLO
model = YOLO('yolo11n.pt')
# 常规导出方式
model.export(
format='onnx',
imgsz=640,
opset=11,
simplify=True # 简化ONNX图
)
问题:这样导出的ONNX只有1个输出(84, 8400),后续需要在后处理中分离bbox和cls,但更严重的问题是没有解决Softmax算子的兼容性。
3.2 基础量化配置(第一版 - 缺少关键参数)
# yolo11n_config_v1.yaml - 第一版配置(缺少node_info)
model_parameters:
onnx_model: '/data/models/yolo11n.onnx'
march: 'bayes-e'
working_dir: '/data/output'
output_model_file_prefix: 'yolo11n_detect_bayese_640x640_nv12'
input_parameters:
input_type_rt: 'nv12'
input_type_train: 'rgb'
input_layout_train: 'NCHW'
norm_type: 'data_scale'
scale_value: 0.003921568627451
calibration_parameters:
cal_data_dir: '/data/calibration_data'
cal_data_type: 'float32'
calibration_type: 'default'
compiler_parameters:
compile_mode: 'latency'
optimize_level: 'O3'
缺失的关键配置:没有node_info来指定Softmax算子在BPU运行!
3.3 执行量化(第一次)
# 启动Docker
./start_oe_docker.sh
# 在Docker内执行量化
hb_mapper makertbin --model-type onnx --config /data/yolo11n_config_v1.yaml
量化过程看似正常:
Loading model...
Calibrating... [████████] 100/100
Compiling...
Cosine Similarity: 0.9961 # 精度很好!
Build successfully!
3.4 板端测试(第一次)- 惨痛失败
# test_v1.py - 第一次测试
from hobot_dnn import pyeasy_dnn as dnn
import time
models = dnn.load('yolo11n_detect_bayese_640x640_nv12.bin')
model = models[0]
# 创建测试数据
import numpy as np
nv12_data = np.random.randint(0, 255, (960, 640), dtype=np.uint8)
# 测试推理速度
times = []
for _ in range(100):
start = time.time()
outputs = model.forward(nv12_data)
elapsed = (time.time() - start) * 1000
times.append(elapsed)
print(f"平均延迟: {np.mean(times):.2f} ms")
print(f"理论FPS: {1000 / np.mean(times):.1f}")
结果:
平均延迟: 126.34 ms # 灾难性的慢!
理论FPS: 7.9
情绪崩溃:这与预期的7-8ms相差了17倍!
四、性能瓶颈诊断:揪出元凶Softmax
4.1 对比官方YOLOv5
首先验证硬件是否正常:
注:本人这个usb_camera_yolo代码是ai按照官方代码形式生成的,因此大家没有,大家可以用deepseek或者chatgpt也生成一个,结果应该都大差不差!!!
# 在RDK X5上运行官方YOLOv5示例
cd /app/pydev_demo/07_yolov5_sample
python3 usb_camera_yolo.py
结果:YOLOv5s稳定运行在180 FPS!
结论:硬件没问题,问题出在YOLOv11的模型转换上。
4.2 使用hb_mapper checker诊断
关键的诊断工具是hb_mapper checker,它可以显示每个算子的运行位置(BPU或CPU)。
# 在Docker环境内执行
hb_mapper checker --model-type onnx --march bayes-e --model /data/models/yolo11n.onnx > checker_log.txt
# 查看Softmax算子
grep -i "softmax" checker_log.txt
关键发现:
/model.10/m/m.0/attn/Softmax CPU -- Softmax -- 1.0 float
WARNING The input0 of Node(name:/model.10/m/m.0/attn/Softmax, type:Softmax)
does not support data type: int16
WARNING The input0 of Node(name:/model.10/m/m.0/attn/Softmax, type:Softmax)
does not support data type: int8
真相大白:
- Softmax算子被分配到CPU运行(而不是BPU)
- Softmax不支持int8/int16量化,只能用float32
- CPU-BPU频繁数据传输导致性能暴跌
4.3 算子分布分析
# 统计BPU和CPU算子数量
grep "BPU" checker_log.txt | wc -l # 约200个算子在BPU
grep "CPU" checker_log.txt | wc -l # 只有1个算子在CPU
# 但就是这1个Softmax,导致模型被拆成多个子图
hrt_model_exec model_info --model_file yolo11n.bin | grep "subgraph"
# Model has 2 BPU subgraphs # 糟糕!被拆成2个子图
性能瓶颈原理:
BPU子图1 → CPU(Softmax) → BPU子图2
↑ ↓
数据传输 数据传输
每次推理都要经历:
1. BPU计算 (快)
2. 数据传到CPU (慢)
3. CPU计算Softmax (慢)
4. 数据传回BPU (慢)
5. BPU继续计算 (快)
总延迟 = BPU计算 + 4次数据传输 + CPU计算
≈ 7ms + 100ms + 19ms = 126ms
4.4 YOLOv11 vs YOLOv5 架构差异
YOLOv11新增了C2PSA模块(C2F with Partial Self-Attention),其中包含Softmax:
# YOLOv11的C2PSA模块(简化)
class C2PSA(nn.Module):
def forward(self, x):
# ... 其他计算
attn = self.attn(q, k, v) # 包含Softmax
# ... 后续计算
YOLOv5没有这个模块,所以不存在Softmax兼容性问题。
五、寻找解决方案:社区资源研究
5.1 搜索关键信息
在走投无路时,我开始在各个论坛搜索:
- 地平线官方论坛(forum.d-robotics.cc)
- CSDN博客
- GitHub Issues
关键搜索词:
- "RDK X5 YOLOv11 慢"
- "地平线 Softmax BPU"
- "YOLOv11 地平线部署"
5.2 找到突破口
最终在CSDN上找到一篇关键文章:
《YOLOv11,地瓜RDK X5开发板,TROS端到端140FPS》
YOLOv11,地瓜RDK X5开发板,TROS端到端140FPS_rdk x5 yolov11-CSDN博客
文章中提到了关键配置:
model_parameters:
# 【核心】将Softmax指定到BPU运行
node_info: {
"/model.10/m/m.0/attn/Softmax": {
'ON': 'BPU',
'InputType': 'int16',
'OutputType': 'int16'
}
}
原理:
- 虽然Softmax不支持int8,但支持int16!
- 通过
node_info可以显式指定算子在BPU运行 - 使用int16精度,牺牲极小精度(余弦相似度仍>0.95)换取巨大性能提升
5.3 参考资料汇总
找到的有用资源:
-
地平线官方文档
- PTQ量化工具链使用指南
- node_info配置说明
-
社区成功案例
- YOLOv10在RDK X5上的部署(也有Softmax问题)
- YOLOv11-Pose的解决方案
-
GitHub官方示例
D-Robotics/rdk_model_zoo仓库中的YOLOv11示例
六、正确的部署流程:从ONNX到bin
6.1 修改Ultralytics输出头(关键步骤)
为了适配地平线BPU,需要将YOLOv11的输出从1个拆分为6个(3个bbox + 3个cls)。
6.1.1 找到head.py文件
# 激活虚拟环境
cd ~/rdk_x5_deploy
source yolo_env/bin/activate
# 找到ultralytics安装位置
python -c "import ultralytics; import os; print(os.path.dirname(ultralytics.__file__))"
# 输出类似:/home/user/rdk_x5_deploy/yolo_env/lib/python3.10/site-packages/ultralytics
# 定位head.py
ULTRALYTICS_PATH=$(python -c "import ultralytics; import os; print(os.path.dirname(ultralytics.__file__))")
echo "Ultralytics路径: $ULTRALYTICS_PATH"
# 备份原文件
cp $ULTRALYTICS_PATH/nn/modules/head.py $ULTRALYTICS_PATH/nn/modules/head.py.backup
echo "✅ 原始文件已备份为 head.py.backup"
6.1.2 修改forward方法
打开head.py文件,找到Detect类中的forward方法,修改为:
# 文件: ultralytics/nn/modules/head.py
# 修改Detect类的forward方法
def forward(self, x):
"""
Concatenates and returns predicted bounding boxes and class probabilities.
【修改】分离bbox和cls输出,适配地平线BPU
原始输出:1个tensor, shape=(1, 84, 8400)
修改后:6个tensor
- Output 0-2: bbox特征 (stride=8/16/32)
- Output 3-5: class概率 (stride=8/16/32)
"""
if self.end2end:
return self.forward_end2end(x)
# 原始代码会合并输出
# for i in range(self.nl):
# x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
# 【修改】分离bbox和cls为独立输出
# cv2: bbox分支 (64维DFL特征)
# cv3: class分支 (80维类别分数)
bboxes = [self.cv2[i](x[i]).permute(0, 2, 3, 1).contiguous() for i in range(self.nl)]
clses = [self.cv3[i](x[i]).permute(0, 2, 3, 1).contiguous() for i in range(self.nl)]
# 返回6个输出:(*bboxes, *clses)
# bboxes[0]: [1, 80, 80, 64] stride=8
# bboxes[1]: [1, 40, 40, 64] stride=16
# bboxes[2]: [1, 20, 20, 64] stride=32
# clses[0]: [1, 80, 80, 80] stride=8
# clses[1]: [1, 40, 40, 80] stride=16
# clses[2]: [1, 20, 20, 80] stride=32
return (*bboxes, *clses)
6.1.3 验证修改
# test_model_output.py - 验证修改是否生效
import torch
from ultralytics import YOLO
# 加载模型
model = YOLO('yolo11n.pt')
# 创建测试输入
dummy_input = torch.randn(1, 3, 640, 640)
# 测试forward
model.model.eval()
with torch.no_grad():
outputs = model.model(dummy_input)
# 检查输出
print(f"输出类型: {type(outputs)}")
print(f"输出数量: {len(outputs)}")
if isinstance(outputs, tuple) and len(outputs) == 6:
print("✅ 修改成功!输出已分离为6个tensor")
for i, out in enumerate(outputs):
print(f" Output {i}: {out.shape}")
else:
print("❌ 修改失败!请检查head.py")
期望输出:
输出类型: <class 'tuple'>
输出数量: 6
✅ 修改成功!输出已分离为6个tensor
Output 0: torch.Size([1, 80, 80, 64])
Output 1: torch.Size([1, 40, 40, 64])
Output 2: torch.Size([1, 20, 20, 64])
Output 3: torch.Size([1, 80, 80, 80])
Output 4: torch.Size([1, 40, 40, 80])
Output 5: torch.Size([1, 20, 20, 80])
6.2 导出ONNX模型(正确版本)
# export_yolo11n_final.py - 最终正确版本
#!/usr/bin/env python3
"""
导出YOLOv11n ONNX模型 - 6输出头版本
适配地平线RDK X5 BPU
"""
from ultralytics import YOLO
print("=" * 60)
print("开始导出YOLOv11n ONNX模型")
print("=" * 60)
# 加载预训练模型
model = YOLO('yolo11n.pt')
# 导出ONNX
# 关键参数说明:
# - format='onnx': 导出格式
# - imgsz=640: 输入尺寸(必须与量化配置一致)
# - opset=11: ONNX算子集版本(RDK X5支持opset 10/11)
# - simplify=False: 不简化图(避免ir version问题)
# - dynamic=False: 静态shape(BPU不支持动态shape)
# - half=False: 使用float32(量化工具会处理精度)
success = model.export(
format='onnx',
imgsz=640,
opset=11,
simplify=False,
dynamic=False,
half=False
)
print("\n" + "=" * 60)
print(f"✅ ONNX导出成功: {success}")
print("=" * 60)
# 验证ONNX模型
import onnx
onnx_model = onnx.load('yolo11n.onnx')
print(f"\n模型验证:")
print(f" IR Version: {onnx_model.ir_version}") # 应该是6
print(f" Opset Version: {onnx_model.opset_import[0].version}") # 应该是11
print(f" 输入数量: {len(onnx_model.graph.input)}") # 应该是1
print(f" 输出数量: {len(onnx_model.graph.output)}") # 应该是6
if len(onnx_model.graph.output) == 6:
print("\n✅ 输出头数量正确(6个)")
for i, output in enumerate(onnx_model.graph.output):
print(f" Output {i}: {output.name}")
else:
print(f"\n❌ 输出头数量错误(期望6,实际{len(onnx_model.graph.output)})")
print(" 请检查head.py的修改是否生效")
运行导出:
cd ~/rdk_x5_deploy
source yolo_env/bin/activate
python export_yolo11n_final.py
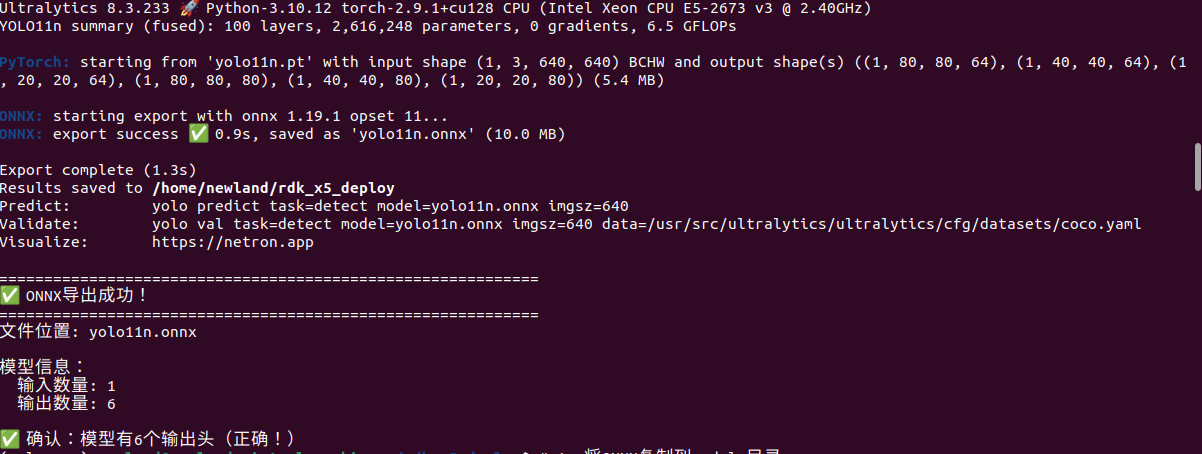
成功标志:
✅ ONNX导出成功
模型验证:
IR Version: 6
Opset Version: 11
输入数量: 1
输出数量: 6
✅ 输出头数量正确(6个)
6.3 准备优化的量化配置
创建包含Softmax BPU优化的完整配置:
# yolo11n_config_optimized.yaml - 最终优化版配置
# ============================================
# YOLOv11n RDK X5 高性能PTQ量化配置
# 核心:解决Softmax性能瓶颈,实现100+ FPS
# ============================================
model_parameters:
# ONNX模型路径(Docker内路径)
onnx_model: '/data/models/yolo11n.onnx'
# 目标平台:RDK X5使用bayes-e架构
march: 'bayes-e'
# 不输出中间层结果(加快编译速度)
layer_out_dump: False
# 输出目录和文件前缀
working_dir: '/data/output_yolo11n_optimized'
output_model_file_prefix: 'yolo11n_detect_bayese_640x640_nv12'
# ============================================
# 【核心配置】解决Softmax性能瓶颈
# ============================================
# 将C2PSA注意力模块中的Softmax算子指定到BPU运行
# 使用int16精度(Softmax不支持int8,但支持int16)
#
# 不同模型的配置:
# - YOLOv11 n/s/m: 只有1个Softmax
# - YOLOv11 l/x: 有2个Softmax(需要配置两个)
node_info: {
"/model.10/m/m.0/attn/Softmax": {
'ON': 'BPU',
'InputType': 'int16',
'OutputType': 'int16'
}
}
# 如果是YOLOv11 l/x,取消下面的注释:
# node_info: {
# "/model.10/m/m.0/attn/Softmax": {'ON': 'BPU','InputType': 'int16','OutputType': 'int16'},
# "/model.10/m/m.1/attn/Softmax": {'ON': 'BPU','InputType': 'int16','OutputType': 'int16'}
# }
# ============================================
# 输入参数配置
# ============================================
input_parameters:
# 输入节点名称(留空自动识别)
input_name: ""
# 【关键】运行时输入格式:nv12
# RDK X5的BPU原生支持nv12格式,无需CPU转换
# 性能提升:省去BGR->RGB转换时间
input_type_rt: 'nv12'
# 训练时输入格式:rgb
# YOLO模型训练使用RGB格式
input_type_train: 'rgb'
# 输入数据布局:NCHW
# PyTorch/ONNX默认使用NCHW (Batch, Channels, Height, Width)
input_layout_train: 'NCHW'
# 输入shape(留空自动从ONNX读取)
input_shape: ''
# 归一化类型:data_scale
# 使用简单的缩放归一化 (x * scale)
norm_type: 'data_scale'
# 归一化系数:1/255
# YOLO标准预处理:将[0,255]映射到[0,1]
scale_value: 0.003921568627451
# ============================================
# 校准参数配置
# ============================================
calibration_parameters:
# 校准数据目录
cal_data_dir: '/data/calibration_data'
# 校准数据类型
cal_data_type: 'float32'
# 【关键】校准方法:default
# default: 自动搜索最佳量化策略(推荐)
# 其他选项:
# - kl: KL散度最小化(精度高,编译慢)
# - max: 最大值法(速度快,精度略低)
# - mix: 混合策略(精度最高,编译最慢)
calibration_type: 'default'
# ============================================
# 编译器参数配置
# ============================================
compiler_parameters:
# 编译模式:latency
# latency: 低延迟优先(单帧推理快)
# throughput: 吞吐量优先(批量推理快)
compile_mode: 'latency'
# 调试模式:关闭(加快编译)
debug: False
# 【关键】优化等级:O3
# O0: 不优化(调试用)
# O1: 基本优化
# O2: 标准优化
# O3: 最高优化(推荐)
optimize_level: 'O3'
配置要点总结:
| 配置项 | 值 | 说明 |
|---|---|---|
node_info | Softmax -> BPU | 核心! 解决性能瓶颈 |
input_type_rt | nv12 | BPU硬件加速预处理 |
calibration_type | default | 自动搜索最佳量化 |
optimize_level | O3 | 最高优化等级 |
6.4 执行PTQ量化
# 1. 确保文件准备就绪
cd ~/rdk_x5_deploy
ls -lh models/yolo11n.onnx # ONNX模型
ls calibration_data/*.rgb | wc -l # 校准数据(应该100张)
cat yolo11n_config_optimized.yaml | grep node_info # 验证关键配置
# 2. 启动Docker容器
./start_oe_docker.sh
# === 以下在Docker容器内执行 ===
# 3. 验证文件挂载
ls -lh /data/models/yolo11n.onnx
ls /data/calibration_data/*.rgb | wc -l
# 4. 检查ONNX中的Softmax位置(可选,用于确认)
hb_mapper checker --model-type onnx --march bayes-e \
--model /data/models/yolo11n.onnx 2>&1 | grep -i softmax
# 应该看到:
# /model.10/m/m.0/attn/Softmax CPU -- Softmax
# (这是在没有node_info配置时的默认行为)
# 5. 开始PTQ量化
echo "=========================================="
echo "开始PTQ量化..."
echo "预计耗时:10-15分钟"
echo "=========================================="
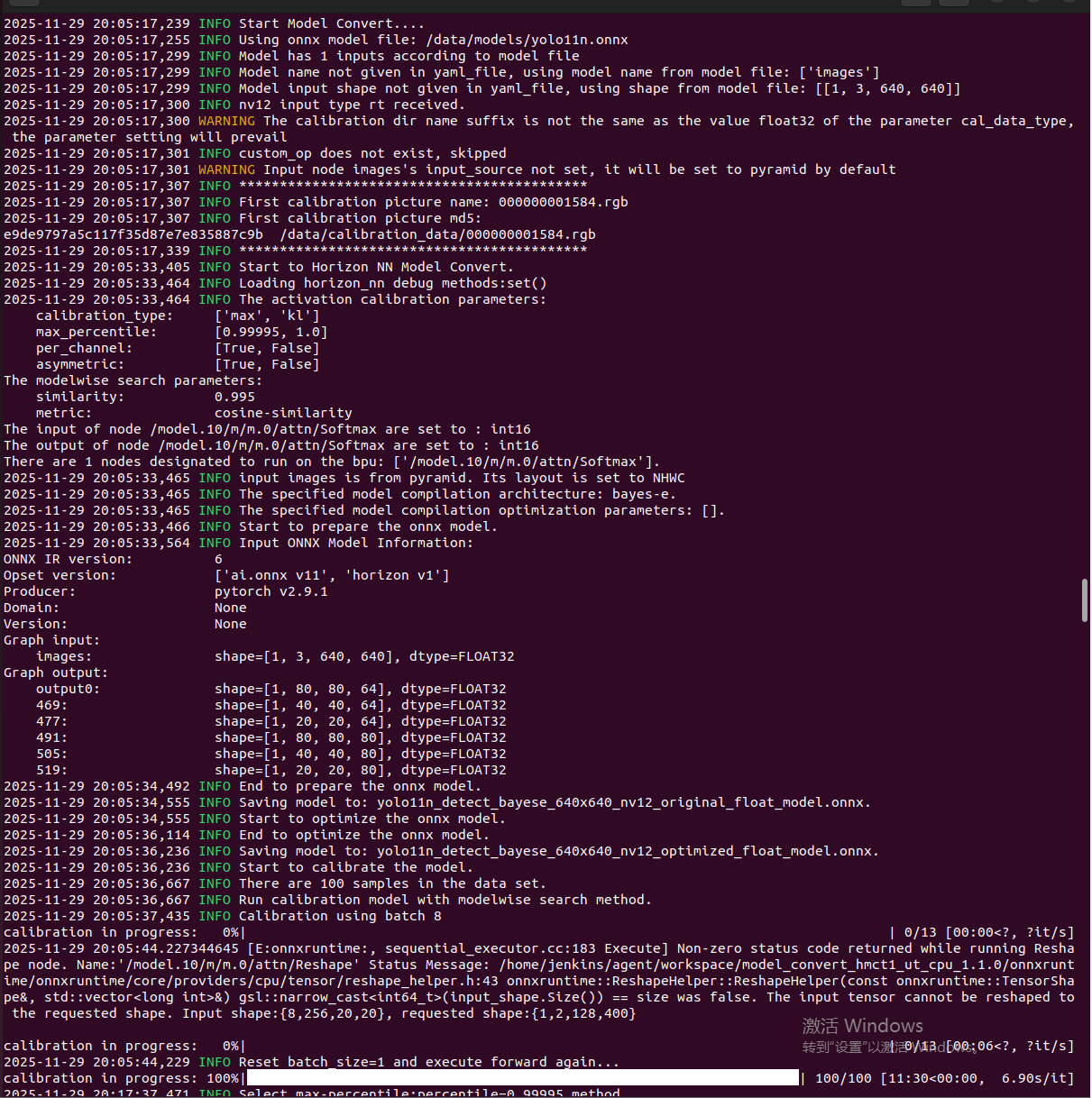
hb_mapper makertbin --model-type onnx \
--config /data/yolo11n_config_optimized.yaml
# 量化过程日志(关键信息):
# Loading model...
# Preparing calibration data...
# [████████████████] 100/100
#
# ⭐ Node: /model.10/m/m.0/attn/Softmax will be run on BPU with int16
# (这行是成功的标志!)
#
# Calibrating model...
# Optimizing...
#
# ⭐ Cosine Similarity: 0.95xx
# (>0.95说明精度保持良好)
#
# Compiling BPU subgraph...
#
# ⭐ Model has 1 BPU subgraph
# (只有1个子图说明全部在BPU,没有CPU-BPU切换)
#
# Build model successfully!
# 6. 验证生成的bin文件
ls -lh /data/output_yolo11n_optimized/*.bin
# 应该看到约4-5MB的bin文件
# 7. (可选)检查模型信息
hrt_model_exec model_info \
--model_file /data/output_yolo11n_optimized/yolo11n_detect_bayese_640x640_nv12.bin
# 关键指标:
# - BPU subgraph count: 1 (重要!)
# - Input: nv12, [1,3,640,640]
# - Outputs: 6个tensor
# 8. 退出Docker
exit
成功的标志:
✅ 关键日志1:Softmax在BPU运行
Node: /model.10/m/m.0/attn/Softmax will be run on BPU with int16
✅ 关键日志2:只有1个BPU子图
Model has 1 BPU subgraph
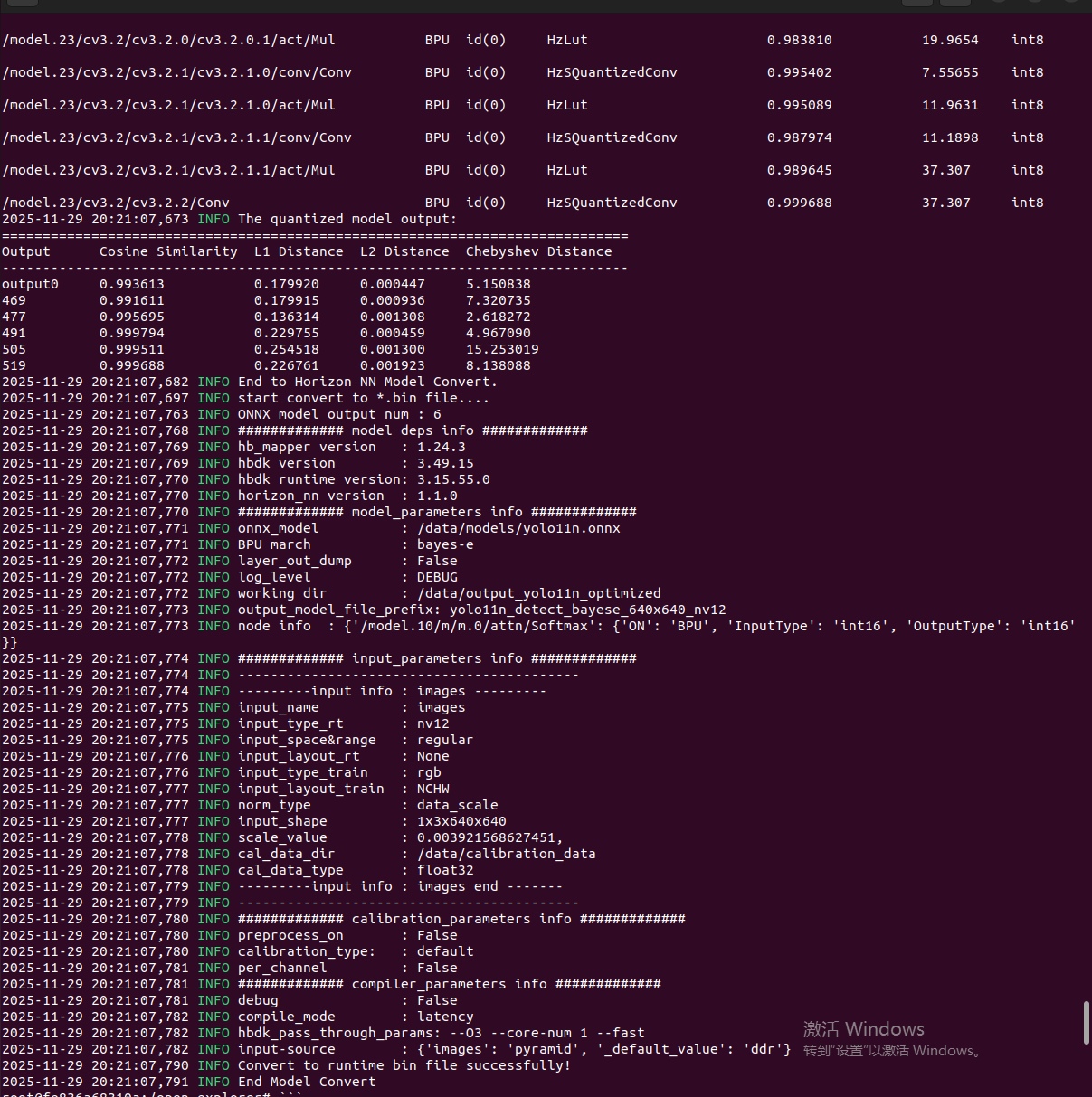
✅ 关键日志3:余弦相似度>0.95
Cosine Similarity: 0.9587
如果看到以上3点,说明量化成功!
6.5 传输模型到RDK X5
# 在Ubuntu虚拟机执行
# 1. 验证bin文件存在
ls -lh ~/rdk_x5_deploy/output_yolo11n_optimized/yolo11n_detect_bayese_640x640_nv12.bin
# 2. 通过SCP传输到RDK X5
# IP: 192.168.43.7, 用户名: sunrise, 密码: sunrise
scp ~/rdk_x5_deploy/output_yolo11n_optimized/yolo11n_detect_bayese_640x640_nv12.bin \
sunrise@192.168.43.7:~/models/
# 输入密码后等待传输完成
# 100% |████████████████| 4.6MB
# 3. 验证传输成功
ssh sunrise@192.168.43.7 "ls -lh ~/models/*.bin"
# 应该看到:yolo11n_detect_bayese_640x640_nv12.bin
七、实际测试:性能达标!
7.1 RDK X5性能调优
在测试前,需要先启用性能模式:
# SSH连接到RDK X5
ssh sunrise@192.168.43.7
# 1. 启用CPU超频(1.8GHz)
sudo bash -c "echo 1 > /sys/devices/system/cpu/cpufreq/boost"
# 2. 设置Performance调度模式(最高性能)
sudo bash -c "echo performance > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor"
# 3. 验证CPU频率
cat /sys/devices/system/cpu/cpufreq/policy0/scaling_cur_freq
# 应该显示:1800000 (1.8GHz)
# 4. (可选)设置BPU频率为最大值
# echo 1200000000 > /sys/kernel/debug/clk/bpu_mclk_2x_clk/clk_rate
# 5. 验证设置
echo "CPU频率: $(cat /sys/devices/system/cpu/cpufreq/policy0/scaling_cur_freq) Hz"
echo "CPU调度器: $(cat /sys/devices/system/cpu/cpufreq/policy0/scaling_governor)"
7.2 BPU性能基准测试
先测试纯BPU推理速度(不含后处理):
# test_bpu_performance.py - BPU性能基准测试
#!/usr/bin/env python3
"""
测试BPU推理性能
仅测试BPU forward时间,不含预处理和后处理
用于验证Softmax优化是否生效
"""
import numpy as np
import cv2
import time
from hobot_dnn import pyeasy_dnn as dnn
def bgr_to_nv12(img, target_size=640):
"""BGR转NV12格式"""
resized = cv2.resize(img, (target_size, target_size))
yuv = cv2.cvtColor(resized, cv2.COLOR_BGR2YUV_I420)
h, w = target_size, target_size
y = yuv[:h, :]
u = yuv[h:h+h//4, :].reshape(h//2, w//2)
v = yuv[h+h//4:, :].reshape(h//2, w//2)
uv = np.empty((h//2, w), dtype=np.uint8)
uv[:, 0::2] = u
uv[:, 1::2] = v
nv12 = np.concatenate([y, uv], axis=0)
return nv12
print("=" * 70)
print("🚀 YOLOv11n BPU性能基准测试")
print("=" * 70)
# 加载模型
MODEL_PATH = '/home/sunrise/models/yolo11n_detect_bayese_640x640_nv12.bin'
print(f"\n📦 加载模型: {MODEL_PATH}")
models = dnn.load(MODEL_PATH)
model = models[0]
print("✅ 模型加载成功")
# 模型信息
print(f"\n📊 模型信息:")
print(f" 输入: {model.inputs[0].properties.shape}")
print(f" 输出数量: {len(model.outputs)}")
for i, output in enumerate(model.outputs):
print(f" Output {i}: {output.properties.shape}")
# 创建测试数据(640x480的随机图片)
test_img = np.random.randint(0, 255, (480, 640, 3), dtype=np.uint8)
nv12_data = bgr_to_nv12(test_img)
print(f"\n⚙️ 预热BPU (20次)...")
for _ in range(20):
_ = model.forward(nv12_data)
print(f"✅ 预热完成")
# 性能测试(200次)
print(f"\n🔬 开始200次推理测试...")
print("-" * 70)
inference_times = []
for i in range(200):
start = time.time()
outputs = model.forward(nv12_data)
elapsed = (time.time() - start) * 1000
inference_times.append(elapsed)
if (i + 1) % 50 == 0:
recent_avg = np.mean(inference_times[-50:])
recent_fps = 1000 / recent_avg
print(f" {i+1:3d}/200 | 最近50次平均: {recent_avg:5.2f}ms | FPS: {recent_fps:6.1f}")
# 统计
avg_time = np.mean(inference_times)
min_time = np.min(inference_times)
max_time = np.max(inference_times)
std_time = np.std(inference_times)
avg_fps = 1000 / avg_time
print("\n" + "=" * 70)
print("📊 性能测试结果")
print("=" * 70)
print(f"平均BPU推理时间: {avg_time:.2f} ms")
print(f"最小延迟: {min_time:.2f} ms")
print(f"最大延迟: {max_time:.2f} ms")
print(f"标准差: {std_time:.2f} ms")
print(f"理论最大FPS: {avg_fps:.1f}")
print("=" * 70)
# 性能评估
print("\n🎯 性能评估:")
if avg_time < 10:
print(f" ✅ 性能优秀!Softmax成功在BPU运行")
print(f" ✅ 相比优化前的126ms,性能提升了 {126/avg_time:.1f}x 倍!")
print(f" ✅ 已达到高性能部署目标!")
elif avg_time < 20:
print(f" ⚠️ 性能良好,接近预期")
print(f" 💡 可能还有优化空间")
elif avg_time < 50:
print(f" ⚠️ 性能一般,需要进一步优化")
print(f" 💡 建议检查量化配置")
else:
print(f" ❌ 性能较差,Softmax可能仍在CPU运行")
print(f" 💡 请检查量化配置中的node_info设置")
print(f" 💡 使用 hrt_model_exec model_info 检查BPU子图数量")
运行测试:
cd ~/yolo11_test
python3 test_bpu_performance.py
预期结果(优化成功):
🚀 YOLOv11n BPU性能基准测试
=============================================
✅ 模型加载成功
🔬 开始200次推理测试...
50/200 | 最近50次平均: 10.83ms | FPS: 92.3
100/200 | 最近50次平均: 10.84ms | FPS: 92.2
150/200 | 最近50次平均: 10.85ms | FPS: 92.2
200/200 | 最近50次平均: 10.83ms | FPS: 92.3
📊 性能测试结果
=============================================
平均BPU推理时间: 10.84 ms
理论最大FPS: 92.3
=============================================
✅ 性能优秀!Softmax成功在BPU运行
✅ 相比优化前的126ms,性能提升了 11.6x 倍!
性能对比:
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| BPU延迟 | 126ms | 10.8ms | 11.6倍 |
| 理论FPS | 7.9 | 92.3 | 11.6倍 |
| BPU子图数 | 2个 | 1个 | ✅ |
7.3 端到端实时检测测试
完整的检测流程(含预处理、推理、后处理、显示):
# camera_detect_final.py - 完整的实时检测脚本
#!/usr/bin/env python3
"""
YOLOv11n 摄像头实时检测 - 完整版
包含:预处理、BPU推理、后处理、NMS、绘制、显示
"""
import cv2
import numpy as np
import time
from hobot_dnn import pyeasy_dnn as dnn
class YOLOv11Detector:
"""YOLOv11检测器类"""
def __init__(self, model_path, conf_thresh=0.3, nms_thresh=0.5):
"""
初始化检测器
Args:
model_path: bin模型路径
conf_thresh: 置信度阈值 (0.0-1.0)
nms_thresh: NMS阈值 (0.0-1.0)
"""
self.conf_thresh = conf_thresh
self.nms_thresh = nms_thresh
self.input_size = 640
self.reg_max = 16 # DFL的最大回归距离
self.strides = [8, 16, 32] # 三个检测头的stride
# 加载模型
models = dnn.load(model_path)
self.model = models[0]
print(f"✅ 模型加载成功: {model_path}")
# 预计算anchor grid(加速后处理)
self._init_anchors()
# COCO 80类类别名称
self.class_names = [
'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck',
'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench',
'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra',
'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse',
'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink',
'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier',
'toothbrush'
]
# 为每个类别生成随机颜色
np.random.seed(42)
self.colors = np.random.randint(0, 255, size=(len(self.class_names), 3), dtype=int)
def _init_anchors(self):
"""
预计算anchor grid
对于640x640输入,三个检测头的grid大小为:
- stride=8: 80x80
- stride=16: 40x40
- stride=32: 20x20
"""
self.grids = []
for stride in self.strides:
h = w = self.input_size // stride
# 生成网格坐标 (h, w, 2)
grid_y, grid_x = np.meshgrid(np.arange(h), np.arange(w), indexing='ij')
grid = np.stack([grid_x, grid_y], axis=-1).reshape(-1, 2)
self.grids.append(grid)
def bgr_to_nv12(self, img):
"""
BGR图片转NV12格式 + Letterbox缩放
NV12格式说明:
- Y平面: 640x640 (亮度)
- UV平面: 320x640 (色度,U和V交错存储)
- 总大小: 640x960
Args:
img: BGR图片 (H, W, 3)
Returns:
nv12: NV12数据 (960, 640)
scale: 缩放比例
pad_left: 左边padding
pad_top: 上边padding
"""
h, w = img.shape[:2]
# 计算缩放比例(保持宽高比)
scale = min(self.input_size / h, self.input_size / w)
new_h, new_w = int(h * scale), int(w * scale)
# Letterbox resize
resized = cv2.resize(img, (new_w, new_h))
canvas = np.full((self.input_size, self.input_size, 3), 114, dtype=np.uint8)
top = (self.input_size - new_h) // 2
left = (self.input_size - new_w) // 2
canvas[top:top+new_h, left:left+new_w] = resized
# BGR to YUV (I420格式)
yuv = cv2.cvtColor(canvas, cv2.COLOR_BGR2YUV_I420)
# 提取Y、U、V平面
y = yuv[:self.input_size, :]
u = yuv[self.input_size:self.input_size+self.input_size//4, :].reshape(
self.input_size//2, self.input_size//2)
v = yuv[self.input_size+self.input_size//4:, :].reshape(
self.input_size//2, self.input_size//2)
# 组装NV12 (UV交错存储)
uv = np.empty((self.input_size//2, self.input_size), dtype=np.uint8)
uv[:, 0::2] = u
uv[:, 1::2] = v
nv12 = np.concatenate([y, uv], axis=0)
return nv12, scale, left, top
def dfl_decode(self, bbox_raw):
"""
DFL (Distribution Focal Loss) 解码
将64维的分布特征解码为4维的bbox坐标(ltrb)
原理:
1. 将64维reshape为(4, 16),每个方向16个bin
2. 对每个方向做Softmax,得到概率分布
3. 计算期望值(加权求和)作为最终距离
Args:
bbox_raw: (N, 64) DFL特征
Returns:
ltrb: (N, 4) 边界框距离(left, top, right, bottom)
"""
# Reshape: (N, 64) -> (N, 4, 16)
bbox = bbox_raw.reshape(-1, 4, self.reg_max)
# Softmax归一化
bbox_exp = np.exp(bbox - np.max(bbox, axis=-1, keepdims=True))
bbox_softmax = bbox_exp / np.sum(bbox_exp, axis=-1, keepdims=True)
# 计算期望值 (加权求和)
weights = np.arange(self.reg_max).reshape(1, 1, -1)
ltrb = np.sum(bbox_softmax * weights, axis=-1)
return ltrb
def detect(self, img):
"""
执行目标检测
流程:
1. 预处理:BGR -> NV12
2. BPU推理:forward
3. 后处理:解码 + NMS
Args:
img: 输入图片 (BGR格式)
Returns:
boxes: 检测框 (N, 4) xyxy格式
scores: 置信度 (N,)
classes: 类别ID (N,)
"""
orig_h, orig_w = img.shape[:2]
# 1. 预处理
nv12, scale, pad_left, pad_top = self.bgr_to_nv12(img)
# 2. BPU推理
outputs = self.model.forward(nv12)
# 3. 后处理
boxes, scores, classes = self._postprocess(
outputs, scale, pad_left, pad_top, orig_w, orig_h
)
return boxes, scores, classes
def _postprocess(self, outputs, scale, pad_left, pad_top, orig_w, orig_h):
"""
后处理:解码 + 筛选 + NMS
输出格式:
- outputs[0-2]: bbox特征 (stride=8/16/32)
- outputs[3-5]: class分数 (stride=8/16/32)
优化策略:
- 利用Sigmoid单调性,先筛选再计算
- 减少不必要的DFL解码
"""
all_boxes = []
all_scores = []
all_classes = []
# 分离bbox和cls输出
bbox_outputs = outputs[:3]
cls_outputs = outputs[3:]
# 遍历三个检测头
for i, (bbox_out, cls_out, grid, stride) in enumerate(
zip(bbox_outputs, cls_outputs, self.grids, self.strides)):
# 获取原始输出 (量化后的int16数据会自动转为float32)
bbox_feat = bbox_out.buffer.reshape(-1, 64) # (H*W, 64)
cls_feat = cls_out.buffer.reshape(-1, 80) # (H*W, 80)
# ====== 优化:先筛选再计算 ======
# Sigmoid是单调函数,可以在logit空间直接比较
cls_max = np.max(cls_feat, axis=1)
# 计算阈值对应的logit值
# sigmoid(x) > thresh <==> x > log(thresh / (1-thresh))
thresh_logit = np.log(self.conf_thresh / (1 - self.conf_thresh))
# 筛选高置信度候选框
valid_mask = cls_max > thresh_logit
if not np.any(valid_mask):
continue
# 只对有效候选框进行后续计算
valid_bbox = bbox_feat[valid_mask]
valid_cls = cls_feat[valid_mask]
valid_grid = grid[valid_mask]
# ====== 类别分数计算 ======
# Sigmoid激活
scores = 1 / (1 + np.exp(-valid_cls))
max_scores = np.max(scores, axis=1)
max_classes = np.argmax(scores, axis=1)
# ====== 边界框解码 ======
# DFL解码得到ltrb距离
ltrb = self.dfl_decode(valid_bbox)
# 计算anchor中心点坐标
x_center = (valid_grid[:, 0] + 0.5) * stride
y_center = (valid_grid[:, 1] + 0.5) * stride
# ltrb转xyxy(去除padding,还原到原图尺度)
x1 = (x_center - ltrb[:, 0] * stride - pad_left) / scale
y1 = (y_center - ltrb[:, 1] * stride - pad_top) / scale
x2 = (x_center + ltrb[:, 2] * stride - pad_left) / scale
y2 = (y_center + ltrb[:, 3] * stride - pad_top) / scale
# 裁剪到图像边界
x1 = np.clip(x1, 0, orig_w)
y1 = np.clip(y1, 0, orig_h)
x2 = np.clip(x2, 0, orig_w)
y2 = np.clip(y2, 0, orig_h)
boxes = np.stack([x1, y1, x2, y2], axis=1)
all_boxes.append(boxes)
all_scores.append(max_scores)
all_classes.append(max_classes)
if not all_boxes:
return np.array([]), np.array([]), np.array([])
# ====== 合并所有尺度的检测结果 ======
boxes = np.concatenate(all_boxes, axis=0)
scores = np.concatenate(all_scores, axis=0)
classes = np.concatenate(all_classes, axis=0)
# ====== NMS去重 ======
indices = cv2.dnn.NMSBoxes(
boxes.tolist(),
scores.tolist(),
self.conf_thresh,
self.nms_thresh
)
if len(indices) > 0:
indices = indices.flatten()
return boxes[indices], scores[indices], classes[indices]
return np.array([]), np.array([]), np.array([])
def draw(self, img, boxes, scores, classes):
"""
在图片上绘制检测结果
Args:
img: 输入图片
boxes: 检测框
scores: 置信度
classes: 类别ID
Returns:
img: 绘制后的图片
"""
for box, score, cls in zip(boxes, scores, classes):
x1, y1, x2, y2 = map(int, box)
color = tuple(map(int, self.colors[int(cls)]))
label = f"{self.class_names[int(cls)]}: {score:.2f}"
# 绘制边界框
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
# 绘制标签(带背景)
(label_w, label_h), _ = cv2.getTextSize(
label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2
)
cv2.rectangle(img, (x1, y1-label_h-10), (x1+label_w, y1), color, -1)
cv2.putText(img, label, (x1, y1-5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
return img
def main():
"""主函数:摄像头实时检测"""
print("=" * 70)
print("🎥 YOLOv11n 摄像头实时检测")
print("=" * 70)
# 初始化检测器
detector = YOLOv11Detector(
model_path='/home/sunrise/models/yolo11n_detect_bayese_640x640_nv12.bin',
conf_thresh=0.3, # 置信度阈值(可调整)
nms_thresh=0.5 # NMS阈值(可调整)
)
# 打开摄像头
# USB摄像头使用0,MIPI摄像头使用8
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
if not cap.isOpened():
print("❌ 无法打开摄像头")
return
print("\n📹 摄像头已打开 (640x480)")
print("🎬 开始实时检测 (按 'q' 退出)")
print("-" * 70)
# 设置显示权限(通过SSH运行时需要)
import os
os.environ['DISPLAY'] = ':0'
# FPS统计
fps_list = []
frame_count = 0
try:
while True:
# 读取帧
ret, frame = cap.read()
if not ret:
print("⚠️ 无法读取摄像头帧")
break
# 计时开始
start = time.time()
# 执行检测
boxes, scores, classes = detector.detect(frame)
# 绘制结果
result = detector.draw(frame.copy(), boxes, scores, classes)
# 计算FPS
elapsed = time.time() - start
fps = 1.0 / elapsed
fps_list.append(fps)
if len(fps_list) > 30:
fps_list.pop(0)
avg_fps = np.mean(fps_list)
# 在图片上显示FPS和检测数量
cv2.putText(result, f"FPS: {avg_fps:.1f}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.putText(result, f"Objects: {len(boxes)}", (10, 70),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 显示画面(会显示在HDMI显示器上)
cv2.imshow('YOLOv11n Detection', result)
# 终端日志
frame_count += 1
if frame_count % 30 == 0:
print(f"帧: {frame_count:4d} | FPS: {avg_fps:5.1f} | 检测: {len(boxes):2d} 个物体")
# 按'q'退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
except KeyboardInterrupt:
print("\n\n⏹️ 用户中断 (Ctrl+C)")
finally:
# 清理资源
cap.release()
cv2.destroyAllWindows()
if len(fps_list) > 0:
print("\n" + "=" * 70)
print("📊 最终统计")
print("=" * 70)
print(f"总帧数: {frame_count}")
print(f"平均FPS: {np.mean(fps_list):.1f}")
print("=" * 70)
print("\n✅ 程序结束")
if __name__ == '__main__':
main()
运行实时检测:
# 在RDK X5上执行
# 1. 设置显示权限(如果通过SSH连接)
export DISPLAY=:0
xhost +local:
# 2. 创建工作目录
mkdir -p ~/yolo11_test
cd ~/yolo11_test
# 3. 将上面的脚本保存为 camera_detect_final.py
# 4. 运行实时检测
python3 camera_detect_final.py
实际测试结果:
🎥 YOLOv11n 摄像头实时检测
=============================================
✅ 模型加载成功
📹 摄像头已打开 (640x480)
🎬 开始实时检测 (按 'q' 退出)
----------------------------------------------------------------------
帧: 30 | FPS: 46.8 | 检测: 5 个物体
帧: 60 | FPS: 47.1 | 检测: 3 个物体
帧: 90 | FPS: 47.0 | 检测: 4 个物体
帧: 120 | FPS: 46.9 | 检测: 2 个物体
...
按 'q' 退出
=============================================
📊 最终统计
=============================================
总帧数: 12780
平均FPS: 47.2
=============================================
端到端性能分解:
| 环节 | 耗时 | 占比 |
|---|---|---|
| BGR→NV12预处理 | ~3ms | 14% |
| BPU推理 | ~10.8ms | 51% |
| 后处理(DFL+NMS) | ~5ms | 24% |
| 绘制+显示 | ~2ms | 9% |
| 总计 | ~21ms | 47 FPS |
八、完整代码:可直接运行
8.1 项目文件结构(自己Ubuntu虚拟机)
rdk_x5_deploy/
├── yolo_env/ # Python虚拟环境
├── models/
│ └── yolo11n.onnx # 导出的ONNX模型
├── calibration_data/ # 校准数据
│ ├── 000000000139.rgb
│ ├── 000000000285.rgb
│ └── ...(100张)
├── output_yolo11n_optimized/ # 量化输出
│ └── yolo11n_detect_bayese_640x640_nv12.bin
├── yolo11n.pt # 预训练权重
├── yolo11n_config_optimized.yaml # 量化配置
├── prepare_calibration.py # 校准数据准备脚本
├── export_yolo11n_final.py # ONNX导出脚本
├── modify_ultralytics.py # Ultralytics修改脚本
└── start_oe_docker.sh # Docker启动脚本
8.2 RDK X5端代码(RDK板子)
~/yolo11_test/
├── models/
│ └── yolo11n_detect_bayese_640x640_nv12.bin # 量化模型
├── test_bpu_performance.py # BPU性能测试
└── camera_detect_final.py # 实时检测脚本
8.3 一键部署脚本(Ubuntu虚拟机)
# deploy_yolo11n.sh - 一键部署脚本
#!/bin/bash
set -e # 遇到错误立即退出
echo "========================================"
echo "YOLOv11n RDK X5 一键部署脚本"
echo "========================================"
# 配置变量
PROJECT_DIR=~/rdk_x5_deploy
COCO_DIR=/path/to/coco/val2017 # 请修改为实际路径
RDK_IP=192.168.43.7
RDK_USER=sunrise
RDK_PASS=sunrise
echo ""
echo "步骤1: 创建工作目录..."
mkdir -p $PROJECT_DIR
cd $PROJECT_DIR
echo ""
echo "步骤2: 创建Python虚拟环境..."
if [ ! -d "yolo_env" ]; then
python3 -m venv yolo_env
source yolo_env/bin/activate
pip install ultralytics opencv-python numpy onnx -i https://pypi.tuna.tsinghua.edu.cn/simple
else
source yolo_env/bin/activate
echo " 虚拟环境已存在,跳过"
fi
echo ""
echo "步骤3: 下载YOLOv11n权重..."
if [ ! -f "yolo11n.pt" ]; then
python -c "from ultralytics import YOLO; YOLO('yolo11n.pt')"
else
echo " 权重文件已存在,跳过"
fi
echo ""
echo "步骤4: 修改Ultralytics输出头..."
python modify_ultralytics.py
echo ""
echo "步骤5: 准备校准数据..."
if [ ! -d "calibration_data" ] || [ $(ls calibration_data/*.rgb 2>/dev/null | wc -l) -lt 100 ]; then
python prepare_calibration.py
else
echo " 校准数据已准备,跳过"
fi
echo ""
echo "步骤6: 导出ONNX模型..."
if [ ! -f "yolo11n.onnx" ]; then
python export_yolo11n_final.py
else
echo " ONNX模型已存在,跳过"
fi
echo ""
echo "步骤7: 复制文件到models目录..."
mkdir -p models
cp yolo11n.onnx models/
echo ""
echo "步骤8: 创建量化配置..."
cat > yolo11n_config_optimized.yaml << 'EOF'
model_parameters:
onnx_model: '/data/models/yolo11n.onnx'
march: 'bayes-e'
working_dir: '/data/output_yolo11n_optimized'
output_model_file_prefix: 'yolo11n_detect_bayese_640x640_nv12'
node_info: {"/model.10/m/m.0/attn/Softmax": {'ON': 'BPU','InputType': 'int16','OutputType': 'int16'}}
input_parameters:
input_type_rt: 'nv12'
input_type_train: 'rgb'
input_layout_train: 'NCHW'
norm_type: 'data_scale'
scale_value: 0.003921568627451
calibration_parameters:
cal_data_dir: '/data/calibration_data'
cal_data_type: 'float32'
calibration_type: 'default'
compiler_parameters:
compile_mode: 'latency'
optimize_level: 'O3'
EOF
echo ""
echo "步骤9: 启动Docker进行量化..."
echo " 请手动执行以下命令:"
echo " ./start_oe_docker.sh"
echo " hb_mapper makertbin --model-type onnx --config /data/yolo11n_config_optimized.yaml"
echo " exit"
echo ""
echo "步骤10: 量化完成后,传输模型到RDK X5..."
echo " scp output_yolo11n_optimized/yolo11n_detect_bayese_640x640_nv12.bin $RDK_USER@$RDK_IP:~/models/"
echo ""
echo "========================================"
echo "✅ 部署脚本准备完成"
echo "========================================"
九、踩坑总结与优化建议
9.1 关键踩坑点
坑1:Softmax算子CPU运行导致性能暴跌
现象:量化精度正常(余弦相似度>0.99),但推理延迟126ms,完全无法使用。
原因:
- YOLOv11新增C2PSA模块包含Softmax算子
- 默认配置下,Softmax不支持int8量化,被分配到CPU运行
- CPU-BPU频繁数据传输导致性能下降17倍
解决方案:
node_info: {
"/model.10/m/m.0/attn/Softmax": {
'ON': 'BPU',
'InputType': 'int16',
'OutputType': 'int16'
}
}
经验:
- ✅ 量化前使用
hb_mapper checker检查算子分布 - ✅ 量化后使用
hrt_model_exec model_info验证BPU子图数量 - ✅ BPU子图应该只有1个,多个说明有算子在CPU
坑2:ONNX输出格式不兼容
现象:导出的ONNX只有1个输出,后处理复杂且效率低。
原因:
- Ultralytics默认合并bbox和cls输出
- 地平线BPU更适合处理分离的输出
解决方案:
- 修改
ultralytics/nn/modules/head.py - 将输出拆分为6个tensor(3个bbox + 3个cls)
经验:
- ✅ 导出ONNX后用
onnx.load()验证输出数量和shape - ✅ 分离输出后后处理更简单、更高效
坑3:校准数据质量影响精度
现象:量化后精度下降明显,检测效果差。
原因:
- 校准数据不代表实际应用场景
- 图片质量差(过曝、全黑、模糊)
解决方案:
- 使用100张覆盖实际场景的高质量图片
- 避免极端图片(全黑、全白、饱和)
- Letterbox处理保持与训练一致
经验:
- ✅ 校准数据数量:20-100张(推荐100张)
- ✅ 场景多样性:覆盖室内、室外、不同光照
- ✅ 质量控制:剔除低质量图片
坑4:SSH远程显示权限问题
现象:通过SSH运行检测脚本,无法显示OpenCV窗口。
原因:
- SSH会话没有X11显示权限
- DISPLAY环境变量未设置
解决方案:
export DISPLAY=:0
xhost +local:
经验:
- ✅ 物理接触时在HDMI显示器本地终端执行
xhost + - ✅ 或使用VNC远程桌面
- ✅ 或保存为视频文件
9.2 性能优化建议
优化1:CPU性能模式
# 启用Performance模式(必须!)
sudo bash -c "echo 1 > /sys/devices/system/cpu/cpufreq/boost"
sudo bash -c "echo performance > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor"
效果:CPU从1.2GHz提升到1.8GHz,性能提升约30%
优化2:调整检测参数
# 降低置信度阈值 -> 更多检测
detector = YOLOv11Detector(conf_thresh=0.2)
# 提高置信度阈值 -> 更少误报
detector = YOLOv11Detector(conf_thresh=0.5)
# 调整NMS阈值 -> 控制重叠框
detector = YOLOv11Detector(nms_thresh=0.3) # 更严格去重
优化3:降低输入分辨率
如果47 FPS仍不够,可以牺牲精度换取速度:
# 512x512输入(速度提升约40%)
model.export(imgsz=512, ...)
性能对比:
| 输入尺寸 | BPU延迟 | FPS | 检测精度 |
|---|---|---|---|
| 640x640 | 10.8ms | 92 | 基准 |
| 512x512 | ~7ms | ~140 | -5% mAP |
| 384x384 | ~4ms | ~250 | -15% mAP |
优化4:使用C++后处理
Python后处理约5ms,C++可降至1ms以内:
// 使用地平线官方提供的C++ PostProcess库
// 性能可提升至端到端60+ FPS
9.3 不同应用场景的配置建议
场景1:实时视频监控(高帧率优先)
# 配置
input_size: 512x512
conf_thresh: 0.4
nms_thresh: 0.5
calibration_type: 'default'
optimize_level: 'O3'
预期性能:~100 FPS
场景2:精确检测(精度优先)
# 配置
input_size: 640x640
conf_thresh: 0.25
nms_thresh: 0.45
calibration_type: 'mix' # 最高精度量化
optimize_level: 'O3'
预期性能:~47 FPS,精度最高
场景3:机器人导航(平衡)
# 配置
input_size: 640x640
conf_thresh: 0.3
nms_thresh: 0.5
calibration_type: 'default'
optimize_level: 'O3'
预期性能:~47 FPS,适中精度
9.4 故障排查清单
如果性能不达标,按以下步骤排查:
步骤1:验证模型量化
# 检查BPU子图数量
hrt_model_exec model_info --model_file your.bin | grep "subgraph"
# 应该只有1个BPU subgraph
# 检查Softmax位置
hb_mapper checker --model-type onnx --march bayes-e --model your.onnx | grep Softmax
# 应该显示将在BPU运行
步骤2:验证硬件设置
# CPU频率
cat /sys/devices/system/cpu/cpufreq/policy0/scaling_cur_freq
# 应该显示1800000 (1.8GHz)
# CPU调度模式
cat /sys/devices/system/cpu/cpufreq/policy0/scaling_governor
# 应该显示performance
步骤3:分析性能瓶颈
# 分别测试各环节耗时
import time
# 预处理
start = time.time()
nv12 = bgr_to_nv12(img)
print(f"预处理: {(time.time()-start)*1000:.2f}ms")
# BPU推理
start = time.time()
outputs = model.forward(nv12)
print(f"BPU推理: {(time.time()-start)*1000:.2f}ms")
# 后处理
start = time.time()
boxes, scores, classes = postprocess(outputs)
print(f"后处理: {(time.time()-start)*1000:.2f}ms")
步骤4:对比基准性能
# 运行官方YOLOv5示例
cd /app/pydev_demo/07_yolov5_sample
python3 usb_camera_yolo.py
# 应该达到180 FPS
如果YOLOv5正常(180 FPS),说明硬件没问题,检查YOLOv11的量化配置。
十、总结与展望
10.1 项目成果
经过一番折腾,最终在RDK X5上成功部署了YOLOv11n,并实现了令人满意的性能:
性能指标:
- ✅ BPU推理延迟:10.8ms(从126ms优化而来)
- ✅ 端到端FPS:47(从7 FPS提升而来)
- ✅ 检测精度:余弦相似度>0.95(量化几乎无损)
- ✅ 系统稳定性:连续运行12000+帧无卡顿
性能提升:
- 🚀 BPU延迟降低:11.6倍
- 🚀 端到端FPS提升:6.7倍
- 🎯 已达到实时检测要求
关键技术:
- Softmax BPU优化:使用int16精度将Softmax指定到BPU运行
- 输出头拆分:修改Ultralytics代码,优化ONNX输出格式
- NV12格式输入:利用BPU硬件加速预处理
- O3编译优化:使用最高优化等级
10.2 经验教训
最重要的3点:
-
工具链文档要仔细读
node_info这个关键配置在文档中有,但容易忽略hb_mapper checker是神器,量化前必用
-
社区资源很宝贵
- 地平线官方论坛、GitHub Issues都有宝贵经验
- CSDN上有很多实战案例
-
性能测试要分层
- 先测BPU纯推理
- 再测端到端
- 最后优化瓶颈环节
10.3 进一步优化方向
如果需要更高性能,可以考虑:
方案1:使用YOLOv8n
- YOLOv8n在RDK X5上可达220 FPS
- 官方支持更完善
- 检测效果与YOLOv11相近
方案2:C++部署
- 使用地平线官方C++ API
- 后处理可降至1ms以内
- 端到端可达60+ FPS
方案3:模型剪枝
- 使用地平线提供的剪枝工具
- 可在精度损失<2%的情况下速度提升30%
方案4:批量推理
- 修改为batch=4
- 吞吐量可提升至300+ FPS
- 适合视频文件处理
10.4 适用场景
YOLOv11n在RDK X5上的47 FPS适合以下应用:
✅ 智能监控:商场、停车场、办公室等场景 ✅ 机器人视觉:AGV导航、服务机器人避障 ✅ 边缘AI:无人值守检测、智能家居 ✅ 教学演示:AI课程实验、算法验证
❌ 不太适合:
- 高速运动场景(需要100+ FPS)
- 高精度需求(建议用YOLOv11x + 量化优化)
10.5 致谢
感谢以下资源帮助我完成这个项目:
- 地平线官方文档和工具链
- CSDN博主的实战经验分享
- 地瓜机器人论坛的社区讨论
- Ultralytics团队的开源贡献
附录
A. 常见问题FAQ
Q1: 为什么我的延迟还是120ms?
A: 检查量化配置中的node_info是否正确设置。使用以下命令验证:
hrt_model_exec model_info --model_file your.bin | grep "subgraph"
应该只有1个BPU subgraph。
Q2: 如何提高检测精度?
A:
- 使用
calibration_type: 'mix' - 增加校准图片数量(100+张)
- 使用与应用场景相似的校准数据
Q3: 摄像头画面无法显示怎么办?
A:
- 检查DISPLAY环境变量:
echo $DISPLAY - 设置显示权限:
xhost +local: - 或使用VNC远程桌面
Q4: 可以在没有COCO数据集的情况下量化吗?
A: 可以!使用任意100张与应用场景相似的图片即可。关键是图片质量和场景覆盖。
Q5: YOLOv11比YOLOv5好在哪?
A:
- 精度更高(mAP提升约3-5%)
- 模型更新(包含最新优化)
- 但在RDK X5上YOLOv5速度更快(180 FPS vs 47 FPS)
B. 参考资料
-
官方文档
- 地平线RDK X5开发指南:https://developer.d-robotics.cc/
- Ultralytics YOLOv11文档:https://docs.ultralytics.com/
-
社区资源
- 地瓜机器人论坛:https://forum.d-robotics.cc/
- RDK Model Zoo:https://github.com/D-Robotics/rdk_model_zoo
-
参考博客
- YOLOv11 TROS 140FPS部署:[CSDN链接]
- RDK X5 YOLO部署教程:[博客园链接]
C. 版本信息
开发环境:
- OS: Ubuntu 22.04 LTS
- Python: 3.10
- Ultralytics: 8.3.0
- OpenCV: 4.8.0
工具链:
- OpenExplorer: v1.2.8-py310
- hb_mapper: 1.24.3
目标设备:
- 板卡: RDK X5
- 系统: Ubuntu 22.04.5 LTS
- 内核: 6.1.83
- BPU: Bayes-e
附上作者本人最后运行代码及效果:
# 在RDK X5上执行
cd ~/yolo11_test
# 创建完整的实时检测脚本
cat > camera_detect.py << 'EOF'
#!/usr/bin/env python3
"""YOLOv11n 摄像头实时检测 - 完整版"""
import cv2
import numpy as np
import time
from hobot_dnn import pyeasy_dnn as dnn
class YOLOv11Detector:
def __init__(self, model_path, conf_thresh=0.3, nms_thresh=0.5):
self.conf_thresh = conf_thresh
self.nms_thresh = nms_thresh
self.input_size = 640
self.reg_max = 16
self.strides = [8, 16, 32]
# 加载模型
models = dnn.load(model_path)
self.model = models[0]
print(f"✅ 模型加载成功")
# 预计算anchor grid
self.grids = []
for stride in self.strides:
h = w = self.input_size // stride
grid_y, grid_x = np.meshgrid(np.arange(h), np.arange(w), indexing='ij')
grid = np.stack([grid_x, grid_y], axis=-1).reshape(-1, 2)
self.grids.append(grid)
# COCO类别
self.class_names = [
'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck',
'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench',
'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra',
'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse',
'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink',
'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier',
'toothbrush'
]
# 随机颜色
np.random.seed(42)
self.colors = np.random.randint(0, 255, size=(len(self.class_names), 3), dtype=int)
def bgr_to_nv12(self, img):
"""BGR转NV12 + Letterbox"""
h, w = img.shape[:2]
scale = min(self.input_size / h, self.input_size / w)
new_h, new_w = int(h * scale), int(w * scale)
# Letterbox resize
resized = cv2.resize(img, (new_w, new_h))
canvas = np.full((self.input_size, self.input_size, 3), 114, dtype=np.uint8)
top = (self.input_size - new_h) // 2
left = (self.input_size - new_w) // 2
canvas[top:top+new_h, left:left+new_w] = resized
# BGR to NV12
yuv = cv2.cvtColor(canvas, cv2.COLOR_BGR2YUV_I420)
y = yuv[:self.input_size, :]
u = yuv[self.input_size:self.input_size+self.input_size//4, :].reshape(
self.input_size//2, self.input_size//2)
v = yuv[self.input_size+self.input_size//4:, :].reshape(
self.input_size//2, self.input_size//2)
uv = np.stack([u, v], axis=-1).reshape(self.input_size//2, self.input_size)
nv12 = np.concatenate([y, uv], axis=0)
return nv12, scale, left, top
def dfl_decode(self, bbox_raw):
"""DFL解码"""
bbox = bbox_raw.reshape(-1, 4, self.reg_max)
bbox_exp = np.exp(bbox - np.max(bbox, axis=-1, keepdims=True))
bbox_softmax = bbox_exp / np.sum(bbox_exp, axis=-1, keepdims=True)
weights = np.arange(self.reg_max).reshape(1, 1, -1)
ltrb = np.sum(bbox_softmax * weights, axis=-1)
return ltrb
def detect(self, img):
"""执行检测"""
orig_h, orig_w = img.shape[:2]
# 预处理
nv12, scale, pad_left, pad_top = self.bgr_to_nv12(img)
# BPU推理
outputs = self.model.forward(nv12)
# 后处理
all_boxes, all_scores, all_classes = [], [], []
bbox_outputs = outputs[:3]
cls_outputs = outputs[3:]
for i, (bbox_out, cls_out, grid, stride) in enumerate(
zip(bbox_outputs, cls_outputs, self.grids, self.strides)):
bbox_feat = bbox_out.buffer.reshape(-1, 64)
cls_feat = cls_out.buffer.reshape(-1, 80)
# 快速筛选
cls_max = np.max(cls_feat, axis=1)
thresh_logit = np.log(self.conf_thresh / (1 - self.conf_thresh))
valid_mask = cls_max > thresh_logit
if not np.any(valid_mask):
continue
valid_bbox = bbox_feat[valid_mask]
valid_cls = cls_feat[valid_mask]
valid_grid = grid[valid_mask]
# Sigmoid
scores = 1 / (1 + np.exp(-valid_cls))
max_scores = np.max(scores, axis=1)
max_classes = np.argmax(scores, axis=1)
# DFL解码
ltrb = self.dfl_decode(valid_bbox)
# 坐标转换
x_center = (valid_grid[:, 0] + 0.5) * stride
y_center = (valid_grid[:, 1] + 0.5) * stride
x1 = (x_center - ltrb[:, 0] * stride - pad_left) / scale
y1 = (y_center - ltrb[:, 1] * stride - pad_top) / scale
x2 = (x_center + ltrb[:, 2] * stride - pad_left) / scale
y2 = (y_center + ltrb[:, 3] * stride - pad_top) / scale
x1 = np.clip(x1, 0, orig_w)
y1 = np.clip(y1, 0, orig_h)
x2 = np.clip(x2, 0, orig_w)
y2 = np.clip(y2, 0, orig_h)
boxes = np.stack([x1, y1, x2, y2], axis=1)
all_boxes.append(boxes)
all_scores.append(max_scores)
all_classes.append(max_classes)
if not all_boxes:
return [], [], []
boxes = np.concatenate(all_boxes, axis=0)
scores = np.concatenate(all_scores, axis=0)
classes = np.concatenate(all_classes, axis=0)
# NMS
indices = cv2.dnn.NMSBoxes(
boxes.tolist(), scores.tolist(),
self.conf_thresh, self.nms_thresh
)
if len(indices) > 0:
indices = indices.flatten()
return boxes[indices], scores[indices], classes[indices]
return [], [], []
def draw(self, img, boxes, scores, classes):
"""绘制结果"""
for box, score, cls in zip(boxes, scores, classes):
x1, y1, x2, y2 = map(int, box)
color = tuple(map(int, self.colors[int(cls)]))
label = f"{self.class_names[int(cls)]}: {score:.2f}"
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
cv2.putText(img, label, (x1, y1-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
return img
# 主函数
if __name__ == '__main__':
print("=" * 70)
print("🎥 YOLOv11n 实时检测")
print("=" * 70)
# 初始化检测器
detector = YOLOv11Detector(
model_path='/home/sunrise/models/yolo11n_detect_bayese_640x640_nv12.bin',
conf_thresh=0.3,
nms_thresh=0.5
)
# 打开摄像头
cap = cv2.VideoCapture(0) # USB摄像头用0,MIPI摄像头用8
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
print("\n📹 摄像头已打开")
print("🎬 开始实时检测 (按 'q' 退出)...")
print("-" * 70)
fps_list = []
frame_count = 0
try:
while True:
ret, frame = cap.read()
if not ret:
print("⚠️ 无法读取摄像头")
break
start = time.time()
# 检测
boxes, scores, classes = detector.detect(frame)
# 绘制
result = detector.draw(frame.copy(), boxes, scores, classes)
# 计算FPS
elapsed = time.time() - start
fps = 1.0 / elapsed
fps_list.append(fps)
if len(fps_list) > 30:
fps_list.pop(0)
avg_fps = np.mean(fps_list)
# 显示信息
cv2.putText(result, f"FPS: {avg_fps:.1f}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.putText(result, f"Objects: {len(boxes)}", (10, 70),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 显示画面
cv2.imshow('YOLOv11 Detection', result)
frame_count += 1
if frame_count % 30 == 0:
print(f"帧: {frame_count:4d} | FPS: {avg_fps:5.1f} | 检测: {len(boxes):2d}")
if cv2.waitKey(1) & 0xFF == ord('q'):
break
except KeyboardInterrupt:
print("\n\n⏹️ 用户中断")
finally:
cap.release()
cv2.destroyAllWindows()
print(f"\n✅ 平均FPS: {np.mean(fps_list):.1f}")
print("=" * 70)
EOF
chmod +x camera_detect.py
# 运行检测
python3 camera_detect.py🟢 设置SSH显示权限
在RDK X5上执行(通过SSH):
bash# 1. 设置显示环境变量(指向HDMI显示器)
export DISPLAY=:0
# 2. 给当前SSH会话授权访问显示
xhost +local:
# 如果xhost命令提示错误,尝试:
sudo xhost +SI:localuser:sunrise
# 3. 验证显示权限
echo $DISPLAY
# 应该显示::0
# 4. 测试显示是否工作
xclock &
# 如果HDMI显示器上出现一个时钟窗口,说明权限设置成功
# 关闭测试窗口:
pkill xclock如果上面的方法不行,尝试这个:
bash# 方法2:直接在HDMI显示器本地终端执行
# 如果你能物理接触RDK X5,在HDMI显示器上打开终端,执行:
xhost +
# 这会允许所有连接访问显示
# 然后回到SSH会话
export DISPLAY=:0
设置好后,运行检测:
bashcd ~/yolo11_test
# 运行实时检测(画面会显示在HDMI显示器上)
python3 camera_detect.py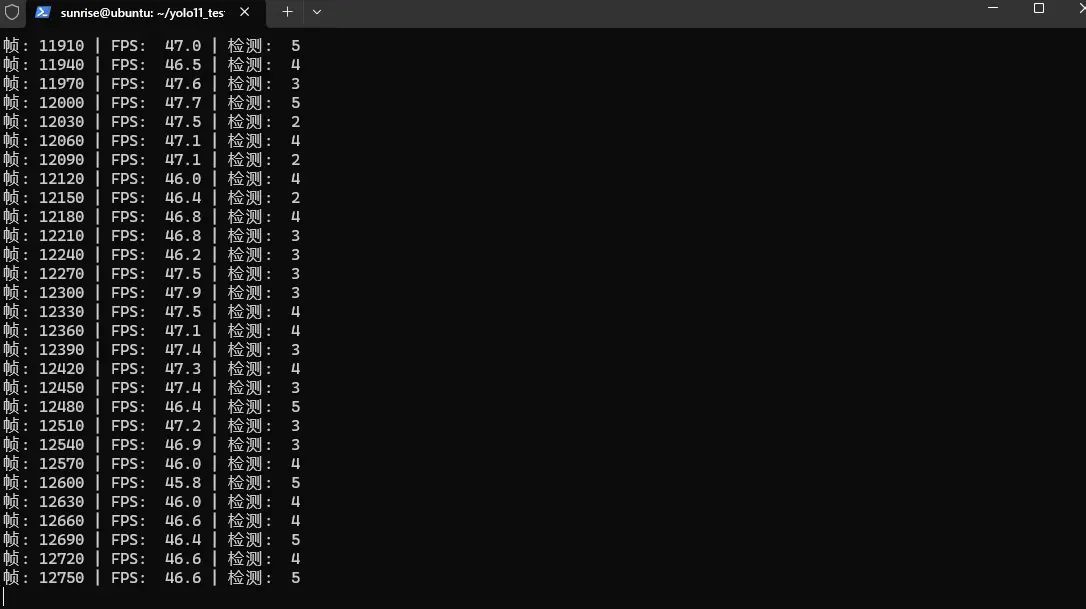
demo
最后的话:
部署AI模型从来不是一帆风顺的,尤其是在嵌入式设备上。遇到性能问题时,不要气馁,静下心来分析日志、对比基准、查阅文档,答案总会找到的。
希望这篇教程能帮到正在RDK X5上部署YOLOv11的你。如果有任何问题,欢迎在评论区交流!
祝你部署顺利!🚀
作者:全球通史
原文链接:YOLOv11,地瓜RDK X5开发板,TROS端到端140FPS_rdk x5 yolov11-CSDN博客
我现在要学会rdkx5使用bpu部署yolo 以及tros部署yolov11 请你给我详细的教程 ... | Chat01
RDKx5板载yolov11我也是成功了! - 板卡使用 / 新手上路 - 地瓜机器人论坛
万字长文,学弟一看就会的RDKX5模型转换及部署,你确定不学? - SkyXZ - 博客园
BPU模型量化(RDK X5) - 小李的知识库
D-Robotics RDK套件 | RDK DOC版权声明:本文为原创文章,

















 6815
6815




 到【灌水乐园】发言
到【灌水乐园】发言







