







Transformer模型是一种强大的深度学习架构,在自然语言处理和其他序列建模任务中取得了显著的成果。为了正确使用Transformer模型,需要对输入数据进行适当的处理,并了解如何处理特殊标记。本文将介绍一些常用的数据处理策略和特殊标记处理方法,帮助您更好地使用Transformer模型。
如何处理Transformer模型中的输入数据和特殊标记?

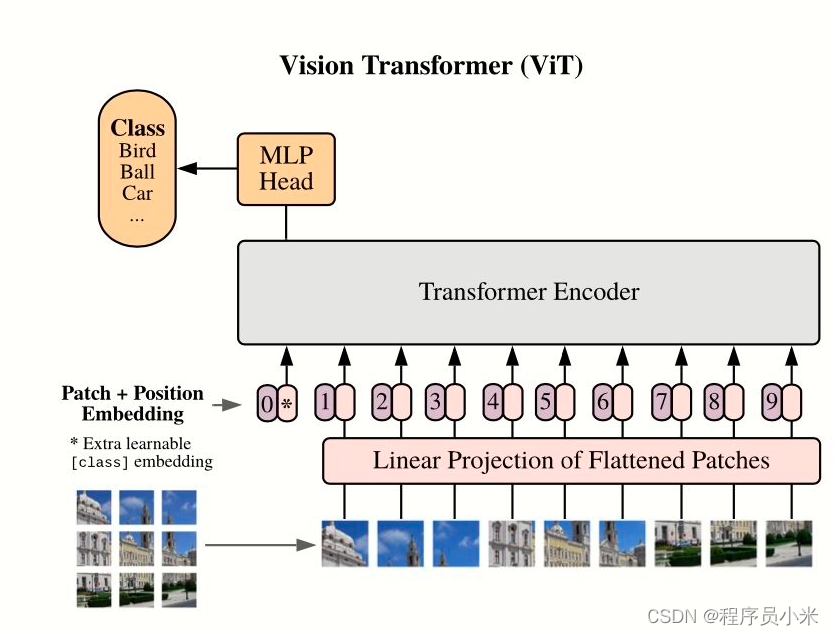
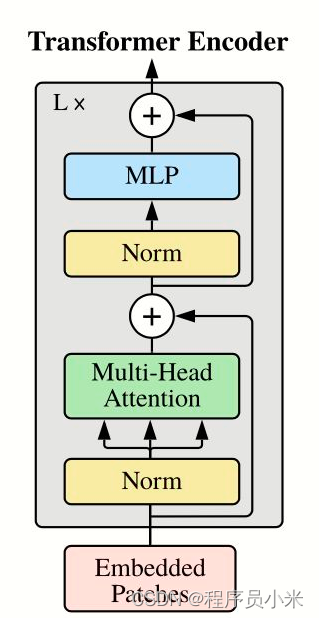
第一部分:输入数据处理策略
- 分词和编码:介绍如何将原始文本数据分词并进行编码,如使用词级别或字符级别的分词方法,以及将词或字符映射为向量表示。
- 位置编码:讨论如何为输入序列添加位置编码,以提供序列中单词或字符的位置信息。
- 数据归一化和标准化:解释数据归一化和标准化的目的和方法,以确保输入数据具有统一的尺度和分布。
- 填充和截断:探讨如何对输入序列进行填充和截断,以使其具有相同的长度。
第二部分:特殊标记处理方法
- 起始和结束标记:说明如何使用特殊的起始和结束标记来表示序列的开始和结束。 <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









