







Abstract :
backgroud:
the development of transformer
-based Vision-Language models.
purpose:
better understand the representations produced by
those models
details:
compare pre-trained and finetuned representations at a vision, language and multimodal
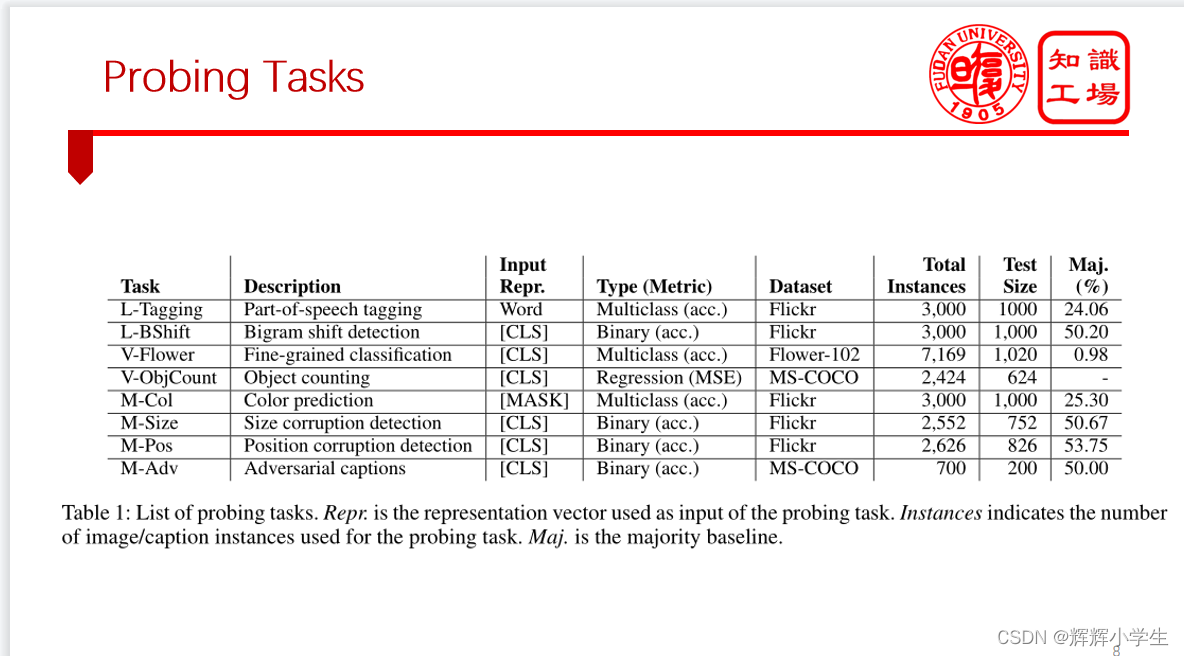
level:
use a set of probing tasks to evaluate
the performance of state-of-the-art Vision-Language models
and introduce new datasets specifically for multimodal probing.
These datasets are carefully designed to address a range
of multimodal capabilities while minimizing the potential for
models to rely on bias.
results:
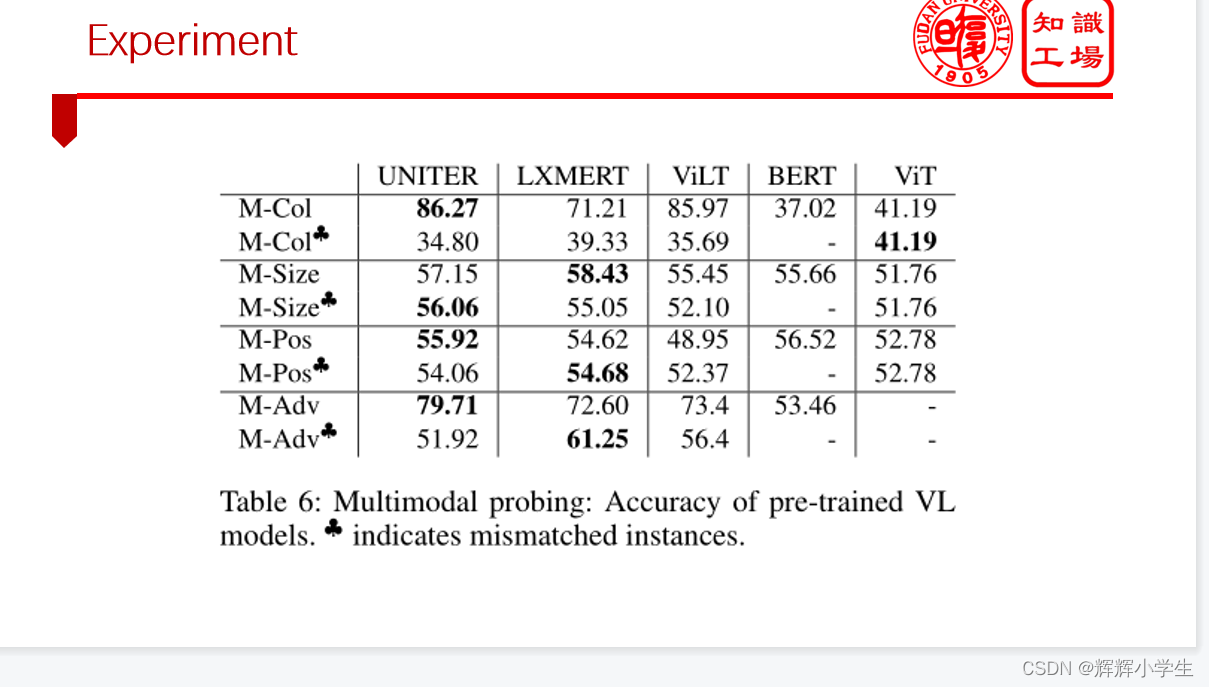
Although the results confirm the ability of Vision-Language models to
understand color at a multimodal level, the models seem to prefer
relying on bias in text data for
object position and size.
On semantically adversarial examples, we find that those models are able to
pinpoint finegrained multimodal differences.
we also notice that fine-tuning a Vision-Language model on multimodal tasks
does not necessarily improve its multimodal ability.
does not necessarily improve its multimodal ability.
Introduction:
VL tasks, such as visual question answering, cross modal retrieval or gener
ation, are notoriously difficult because of the necessity for
models to build sensible multimodal representations that can
relate fine-grained elements of the text and the picture.
how multimodal information is encoded in the representations learned by those models?
how affected they
are by various bias and properties of their training data?
previous
studies have shed light on some particular as
pects of transformer-based VL models, they lack a more sys
tematic analysis of monomodal biases that impede the nature
of the learned representations
.
work:
studying the multimodal capacity of VL representations
exploring what information is learned and forgotten between pre-training and
fine-tuning(this could show the current limits of the pre-training process)
fine-tuning(this could show the current limits of the pre-training process)
we probe three VL models: UNITER, LXMERT and ViLT(both pre-trained and fine-tuned
models)
models)
findings:
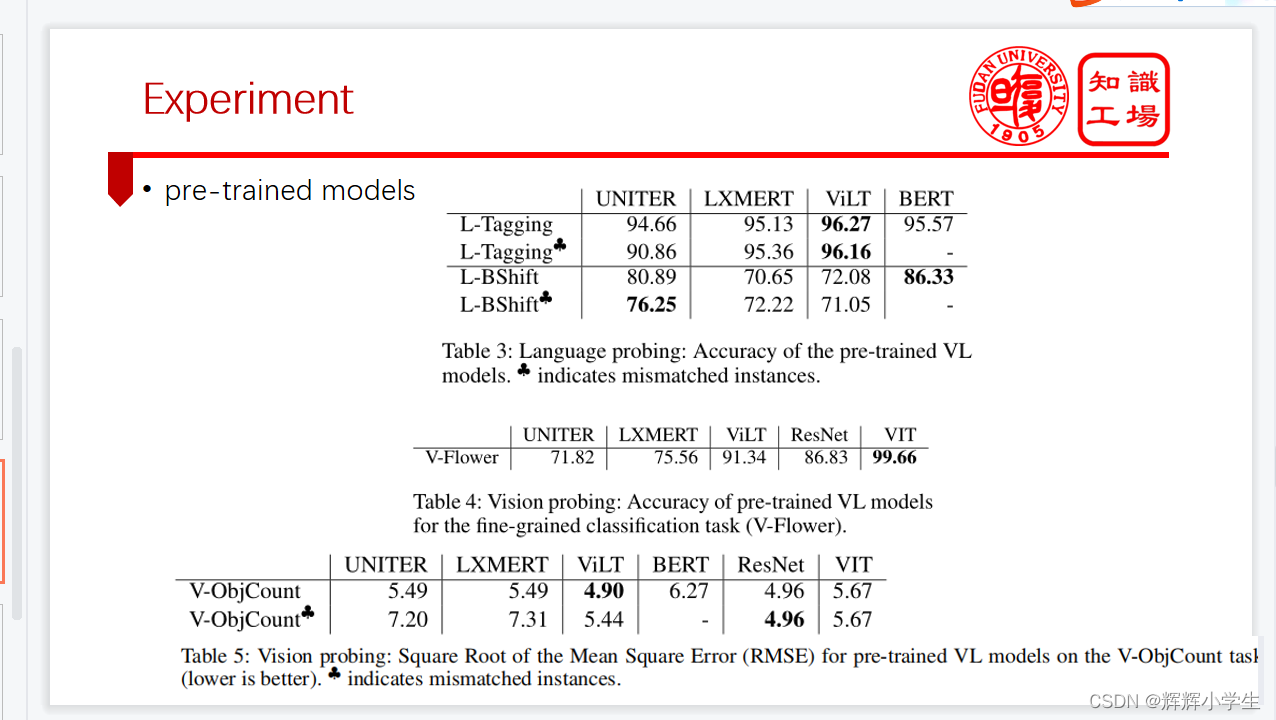
UNITER reaches better overall results on the language modality.
ViLT reaches better results on the vision modality.
while the models show their ability to identify colors, they do not yet have multimodal capacity to distinguish object size and position.
Related Work 略
Methodology
VLMpre -> pres1
fine-tune-T -> pres2
pres1(or pres2) -> probing-task-P -> related information

















 1564
1564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









