







基于storm的在线视频推荐算法,算法依据youtube的推荐算法 算法相对简单,可以认为是关联规则只挖掘频繁二项集。下面给出与storm的结合实现在线实时算法 , 关于storm见这里。首先给出数据流图(不同颜色的线条代表不同的数据流。在storm里面bolt也是可以声明数据流的。)
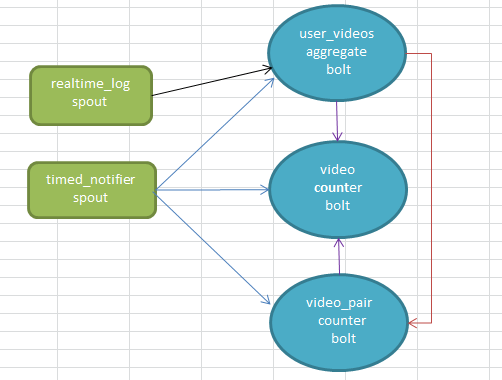
关联规则挖掘数据项的时候,有事务的概念,这里的事务的定义为:给定时间窗口内用户看过的视频集。所以,我们需要这样一个bolt,根据实时日志收集每个用户看过的视频集----user_videos aggregate bolt。 我们怎样挖掘频繁二项集呢?其实就是视频对共同出现的次数,当视频a和b被共同观看的次数(用户看了视频a又看了视频b)大于某个阈值的时候,{a , b}就是一个频繁二项集。
所以我们定时的输出a:b这样的视频对,然后对其计数即可。这个任务是由video_pair counter bolt完成的。这样频繁项挖掘基本完了,如果对于推荐可能需要再走一步:对于看了a的人推荐b 的可信度有多高?如果为a推荐了b,那么对于b的曝光来说提升度是多少呢(可以这样理解,b本身很热门,你再把b推荐出来对于b本身曝光量没有多大作用,这也叫打压热门)? 所以我们需要一个计数器,里面有每个视频被观看的次数---video_counter_bolt。这样,我们就有了youtube算法公式所需要的所有值。
storm本身是流式的,我们这里需要用到统计用户看过的视频集,所以得有一个池子,不停的收集用户看过的视频,定时的放水(定时放水的任务就有timed_notifier_spout完成)。所以整体的流程如下描述:
1、rt-log spout按user分组,将数据流推给uva-bolt.
2、tn-spout 会定期向下游推送时间窗口关闭的通知
3、uva-bolt里面维护一个map , 里面是用户到其观看过的视频集的映射。它第接收到一条日志就会更新这个map , 同时向计数器vc-bolt发送一条播放数据.当收到tn-spout的通知时,便会将map里面的数据构建成视频对,分组后推送给相关的vp-bolt.
4、vp-bolt 也会维护一个map , 用以视频对的计数。 当收到tn-spout的通知时向vc-bolt发送这些统计信息,并清空这个map.
3、vc-bolt内容也维护一个map , 里面是视频到其它被观看次数的映射 。它每接收到一条日志都会分析日志的类型, 如果是计数类型的就会更新这个map .如果收到vp-bolt的数据,便会计算两两视频的相似度(youtube的公式)。
整个topology结构代码:
<span style="white-space:pre"> </span>TopologyBuilder builder = new TopologyBuilder();
SpoutConfig spoutConfig = new SpoutConfig(new ZkHosts(conf.getString("zk.server")), conf.getString("topic"),conf.getString("zk.path"),conf.getString("myid"));
spoutConfig.scheme = new NginxLogScheme();
builder.setSpout("nt-spout" , new NotifierSpout(900) , 1);
builder.setSpout("log-spout", new KafkaSpout(spoutConfig), 3);
builder.setBolt("uv-bolt", new UserVideoAggregationBolt(), conf.getInt("blot.threads"))
.fieldsGrouping("log-spout" , new Fields("cookie")).allGrouping("nt-spout" , "nt");
builder.setBolt("vp-bolt", new VideoPairBolt(), 3).fieldsGrouping("uv-bolt" , "vp" , new Fields("vidPair"))
.allGrouping("nt-spout" , "nt");
builder.setBolt("vc-bolt", new VideoCountBolt(), 3).allGrouping("uv-bolt" , "vc")
.fieldsGrouping("vp-bolt" , "vc" , new Fields("vidPair"))
.allGrouping("nt-spout" , "nt").addConfiguration("mysql.host", conf.getString("mysql.host"))
.addConfiguration("mysql.usr",conf.getString("mysql.usr"))
.addConfiguration("mysql.pass",conf.getString("mysql.pass"))
.addConfiguration("mysql.port",conf.getInt("mysql.port"))
.addConfiguration("mysql.schema",conf.getString("mysql.schema"));
builder.setBolt("rec-redis-bolt" , new RedisRecBolt() , 1).allGrouping("nt-spout" , "nt")
.addConfiguration("mysql.host", conf.getString("mysql.host"))
.addConfiguration("mysql.usr",conf.getString("mysql.usr"))
.addConfiguration("mysql.pass",conf.getString("mysql.pass"))
.addConfiguration("mysql.port",conf.getInt("mysql.port"))
.addConfiguration("mysql.schema",conf.getString("mysql.schema"));注意事项:
1、bolt的outputcollector对于并发可能报错,需要一个定制的线程安全的outputcollector 。
2、这种实现方式属于试验性,不知其是否科学
3、storm会自动重启bolt , 理由是worker heartbeat timeout , 引起这个的问题可能是worker gc的问题。因为我这里有很多的内存缓存,所以会出现频繁full gc
以至于超时。这种频繁的full gc很可能是由于定期向下游放水时短时间内生成大量对象造成的。
4、以上代码仅限结构参考,没有整理。我们用到了kafka.















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









