







其中本次爬虫的主要思想是:首先是找到携程网url的编写规律,然后根据规律使用beautifulsoup4对所需的html语言中的信息提取,最后就是封装处理。爬取的信息只是用来本次毕设的研究非商业用途。对于毕设的相关总结在:旅游推荐系统毕业设计总结(包含旅游信息爬取、算法应用和旅游推荐系统实现)
如下是我爬取美食的代码:
# -*- coding: utf-8 -*-
import requests
import io
from bs4 import BeautifulSoup as BS
import time
import re
"""从网上爬取数据"""
headers = {
"Origin": "https://piao.ctrip.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
}
places=["beijing1","shanghai2","changsha148","sanya61","chongqing158","hongkong38","chengdu104","haerbin151",
"xian7","guangzhou152","hangzhou14"]
placenames=["北京","上海","长沙","三亚","重庆","香港","成都","哈尔滨","西安","广州","杭州"]
places=["changsha148"]
placenames=["长沙"]
base="https://you.ctrip.com/fooditem/";
base2="https://you.ctrip.com";
requestlist=[]
for j in range(len(places)): #爬取对应的特色菜
requestlist.append({"url":base+places[j]+".html","place":placenames[j]})
for i in range(2,2):
tmp=base+places[j]+"/s0-p"+str(i)+".html"
requestlist.append({"url":tmp,"place":placenames[j]});
#对应的url地址和所查询的位置
print(requestlist)
l=[]
count=1;
for i in range(len(requestlist)):
response = requests.get(requestlist[i]["url"], headers=headers)
#print(response)
html=response.text
#print(html)
soup=BS(html,'html.parser')
vs=soup.find_all(name="div",attrs={"class":"rdetailbox"})
print("len(vs)",len(vs))
for j in range(len(vs)):
print("正在打印的条数:",j)
try:
#获取子网页链接地址
href=vs[j].find(name="a",attrs={"target":"_blank"}).attrs["href"];
#print("href",href)
# 再次请求子网页,获取景点详细信息
res = requests.get(base2+href, headers=headers)
print("当前访问的网址:",base2+href)
with open("3.html","w",encoding="utf-8") as f:
f.write(res.text)
soupi = BS(res.text,"html.parser") #该网页的html代码
#print(soupi)
vis = soupi.find_all(name="li",attrs={"class":"infotext"}); #获取此时的dom文件位置所在
#print(vis)
introduce=[]
for i in range(len(vis)):
introduce.append(vis[i].get_text())
imgs=[];
imglinks=soupi.find_all(name="a",attrs={"href":"javascript:void(0)"})
#print(imte)
# print(imglinks)
# print(type(imglinks))
#for img in imte:
#imgs.append(img.attrs["src"])
tmp={};
tmp["id"]=count;
tmp["name"]=vs[j].find(name="a",attrs={"target":"_blank"}).string;
tmp["name"]=tmp["name"].replace(" ","").replace("\n","");
tmp["introduce"]=introduce
tmp["img"]=imglinks
tmp["city"]=requestlist[i]["place"]
count=count+1;
l.append(tmp);
time.sleep(1);
except Exception as e:
print(e)
pass
#print ("打印tmp",tmp)
# with open("datap/"+tmp["name"]+".pk",'wb') as f:
# pickle.dump(tmp,f);
with io.open("/Users/hujinhong/PycharmProjects/untitled5/food/changsha/"+tmp["name"]+".txt",'w',encoding="utf-8") as f:
f.write(str(tmp))
#print(l)
for i in l:
print((i))
成功的爬取如下数据:

爬取携程网景点代码如下:
# -*- coding: utf-8 -*-
import requests
import io
from bs4 import BeautifulSoup as BS
import time
"""从网上爬取数据"""
headers = {
"Origin": "https://piao.ctrip.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
}
places=["beijing1","shanghai2","changsha148","sanya61","chongqing158","hongkong38","chengdu104","haerbin151",
"xian7","guangzhou152","hangzhou14"]
placenames=["北京","上海","长沙","三亚","重庆","香港","成都","哈尔滨","西安","广州","杭州"]
places=["beijing1"]
placenames=["北京"]
city="beijing"
base="https://you.ctrip.com/sight/";
base2="https://you.ctrip.com";
requestlist=[]
for j in range(len(places)): #一个景区爬10页
requestlist.append({"url":base+places[j]+".html","place":placenames[j]})
for i in range(2,4):
tmp=base+places[j]+"/s0-p"+str(i)+".html"
requestlist.append({"url":tmp,"place":placenames[j]});
print(requestlist)
l=[]
count=1;
for i in range(len(requestlist)):
response = requests.get(requestlist[i]["url"], headers=headers)
html=response.text
soup=BS(html,'html.parser')
vs=soup.find_all(name="div",attrs={"class":"rdetailbox"})
print(len(vs))
for j in range(len(vs)):
print(j)
try:
#获取子网页链接地址
href=vs[j].find(name="a",attrs={"target":"_blank"}).attrs["href"];
# 再次请求子网页,获取景点详细信息
res = requests.get(base2+href, headers=headers)
print(base2+href)
with open("3.html","w",encoding="utf-8") as f:
f.write(res.text)
soupi = BS(res.text,"html.parser")
vis = soupi.find_all(name="div",attrs={"class":"text_style"});
introduce=[]
for i in range(len(vis)):
introduce.append(vis[i].get_text())
imgs=[];
imglinks=soupi.find_all(name="img",attrs={"width":"350"})
#print(imglinks)
for img in imglinks:
imgs.append(img.attrs["src"])
score=soupi.find(name="span",attrs={"class":"score"}).b.get_text()
scores=[];
scores.append(score);
scorelinks=soupi.find(name="dl",attrs={"class":"comment_show"}).find_all(name="dd")
for link in scorelinks:
scores.append(link.find(name="span",attrs={"class":"score"}).string)
comments=[];
commentlinks=soupi.find_all(name="span",attrs={"class":"heightbox"});
for link in commentlinks:
comments.append(link.get_text())
tmp={};
tmp["id"]=count;
tmp["name"]=vs[j].find(name="a",attrs={"target":"_blank"}).string;
tmp["name"]=tmp["name"].replace(" ","").replace("\n","");
tmp["introduce"]=introduce
tmp["score"]=scores;
tmp["position"]=vs[j].find_all(name="dd",attrs={"class":"ellipsis"})[0].string;
tmp["position"]=tmp["position"].replace(" ","").replace("\n","");
tmp["img"]=imgs
tmp["city"]=city
tmp["grade"]=soupi.find_all(name="span", attrs={"class": "s_sight_con"})[0].get_text()
tmp["grade"]=tmp["grade"].replace(" ","").replace("\n","")
#tmp["fujin"]=soupi.find_all(name="a", attrs={"class": "item"})
count=count+1;
l.append(tmp);
time.sleep(1);
except Exception as e:
print(e)
pass
print ("打印tmp",tmp)
# with open("datap/"+tmp["name"]+".pk",'wb') as f:
# pickle.dump(tmp,f);
with io.open("/Users/hujinhong/PycharmProjects/untitled5/jingdian/beijing/"+tmp["name"]+".txt",'w',encoding="utf-8") as f:
f.write(str(tmp))
print(l)
# # browser.close()#关闭浏览器
# with open("data2.txt",'w',encoding='utf-8') as f:
# f.write(str(l))
# with open("data2.pk","w",encoding="utf-8") as f:
# pickle.dump(l,f);
#https://hotels.ctrip.com/hotel/qingdao7/star2/k1%E4%BA%94%E5%9B%9B%E5%B9%BF%E5%9C%BA#ctm_ref=ctr_hp_sb_lst
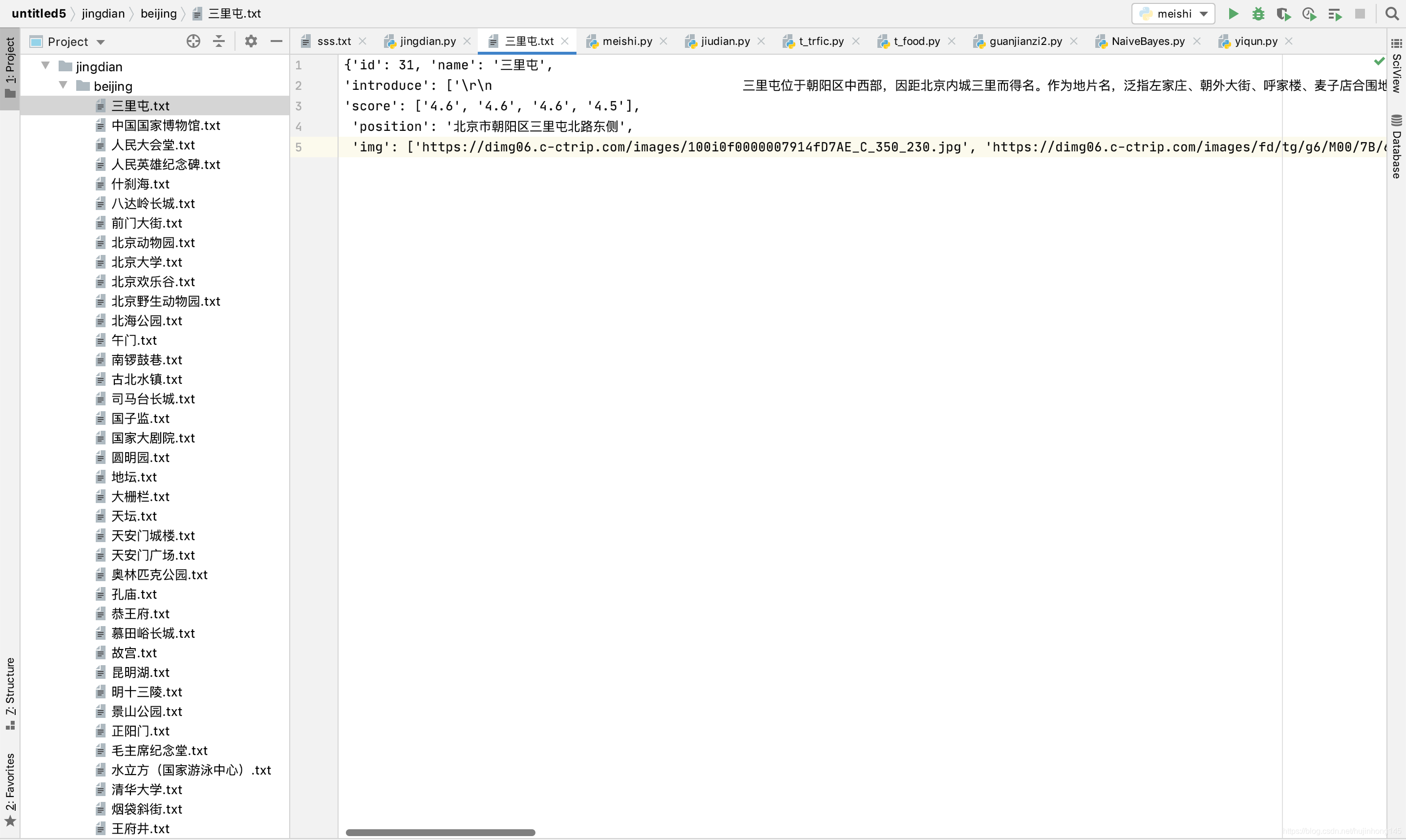
成功爬取到携程网的景点,截图如下:
爬取酒店信息代码
# -*- coding: utf-8 -*-
import requests
import io
from bs4 import BeautifulSoup as BS
import time
"""从网上爬取数据"""
headers = {
"Origin": "https://piao.ctrip.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
}
places=["beijing1","shanghai2","Changsha206","sanya61","chongqing158","hongkong38","chengdu104","haerbin151",
"xian7","guangzhou152","Hangzhou17"]
placenames=["北京","上海","长沙","三亚","重庆","香港","成都","哈尔滨","西安","广州","杭州"]
places=["Hangzhou17"]
placenames=["杭州"]
numid=17
base="https://hotels.ctrip.com/hotel/";
base2="https://you.ctrip.com";
requestlist=[]
for j in range(len(places)): #爬取对应的特色菜
requestlist.append({"url":base+places[j]+".html","place":placenames[j]})
for i in range(2,4):
tmp=base+places[j]+"/s0-p"+str(i)+".html"
requestlist.append({"url":tmp,"place":placenames[j]});
#对应的url地址和所查询的位置
print(requestlist)
l=[]
count=1;
for i in range(len(requestlist)):
response = requests.get(requestlist[i]["url"], headers=headers)
#print(response)
html=response.text
#print(html)
soup=BS(html,'html.parser')
print(soup)
vs=soup.find_all(name="div",attrs={"class":"hotel_new_list"})
print("len(vs)",vs)
for j in range(len(vs)):
print("正在打印的条数:",j)
try:
daid=vs[j].find(name="h2",attrs={"class":"hotel_name"}).attrs["data-id"]
#ss=vs[j].find(name="a",attrs={"data-dopost":"T"}).attrs["title"]
#print("ss",ss)
#print(type(daid))
#print(type(j))
#获取子网页链接地址
href1="https://hotels.ctrip.com/hotel/"+daid+".html?isFull=F"
print(daid)
href=href1+"&masterhotelid="+daid+"&hcityid="+str(numid)+"#ctm_ref=hod_sr_lst_dl_n_2_"+str(j+1);
print("href",href)
# 再次请求子网页,获取景点详细信息
res = requests.get(href, headers=headers)
#print("当前访问的网址:",base2+href)
with open("3.html","w",encoding="utf-8") as f:
f.write(res.text)
soupi = BS(res.text,"html.parser") #该网页的html代码
#print(soupi)
vis = soupi.find_all(name="div",attrs={"class":"hotel_info_comment"}); #获取此时的dom文件位置所在
#print(vis)
introduce=[]
for i in range(len(vis)):
introduce.append(vis[i].get_text())
imgs=[];
imglinks=soupi.find(name="div",attrs={"data-index":"0"}).attrs["_src"];
print(type(soupi.find(name="div",attrs={"data-index":"0"})))
#print(soupi)
#print(imte)
print(imglinks)
tmp={};
tmp["id"]=count;
tmp["name"]=vs[j].find(name="a",attrs={"data-dopost":"T"}).attrs["title"];
#函数是这种小括号,字典的话应该就是中括号
tmp["name"]=tmp["name"].replace(" ","").replace("\n","");
tmp["introduce"]=introduce
tmp["img"]=imglinks
tmp["city"]=placenames
count=count+1;
l.append(tmp);
time.sleep(1);
except Exception as e:
print(e)
pass
print ("打印tmp",tmp)
# with open("datap/"+tmp["name"]+".pk",'wb') as f:
# pickle.dump(tmp,f);
# with io.open("/Users/hujinhong/PycharmProjects/untitled5/hotle/hangzhou/"+tmp["name"]+".txt",'w',encoding="utf-8") as f:
# f.write(str(tmp))
print(l)
# # browser.close()#关闭浏览器
# with open("data2.txt",'w',encoding='utf-8') as f:
# f.write(str(l))
# with open("data2.pk","w",encoding="utf-8") as f:
# pickle.dump(l,f);
#https://hotels.ctrip.com/hotel/qingdao7/star2/k1%E4%BA%94%E5%9B%9B%E5%B9%BF%E5%9C%BA#ctm_ref=ctr_hp_sb_lst
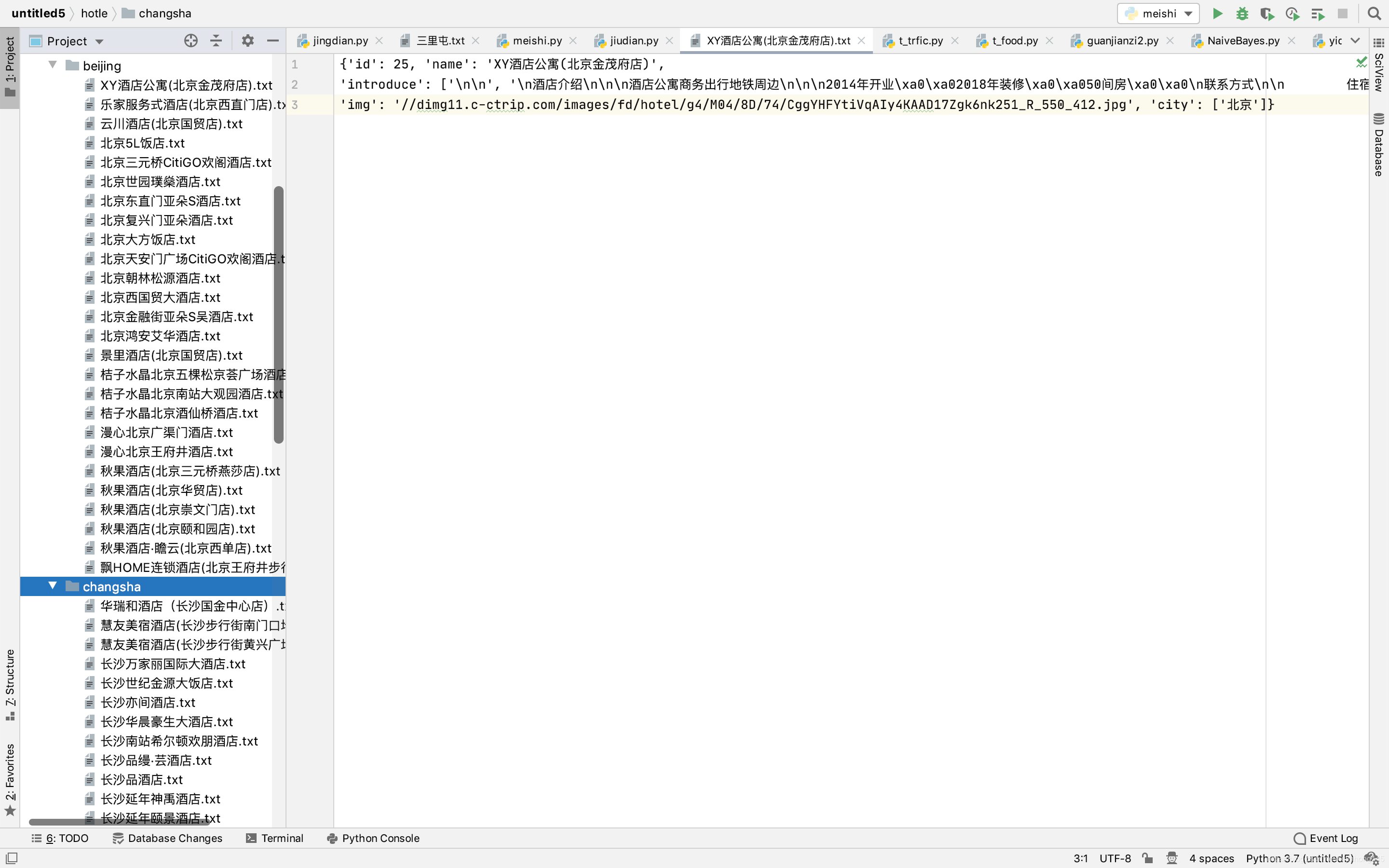
爬取信息截图如下:

















 2911
2911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









