







编辑:Happy
首发:AIWalker

paper:https://arxiv.org/abs/2006.09603
Code: https://github.com/LongguangWang/SMSR
本文是国防科大王龙光等人在图像超分高效推理方面的尝试,已被CVPR2021接收。本文从特征稀疏性、不同区域的重建需求角度出发,提出了一种自适应学习空域掩码与通道掩码的方案,并利用该掩码构建稀疏卷积,在保持模型性能不变的同时,大幅减少模型的计算量。比如,在x2超分任务上,其计算量空域减少41%且性能保持同等水平。
Abstract
当前基于CNN的图像超分对所有位置同等对待,即每个位置都需要经过网络进行处理。实际上,低分辨率图像的细节缺失主要位于边缘、纹理区域,而平坦区域则较少缺失,故而赋予更少的计算量处理亦可。这就意味着现有基于CNN的图像超分方法在平坦区域存在计算量冗余问题,限制了对应方法在移动端的应用。
为解决上述问题,我们对图像超分中的稀疏性问题进行了探索,并用于改善超分网络的推理高效性。具体来说,我们设计了一种Sparse Mask SR(SMSR)学习稀疏掩码以剪枝冗余计算量。结合所提SMSR,空域掩码学习判别“重要性”区域而通道掩码学习冗余通道(即不重要区域)。因此,冗余计算空域被精确的定位并跳过,同时保持同等性能。
最后,我们通过实验证实:SMSR取得了SOTA性能,同时x2/3/4被超分的计算量降低41%、33%以及27%。
本文的主要贡献包含以下几点:
- 我们提出了一种SMSR动态跳过冗余计算以达成高效图像超分;
- 我们提出通过学习空域与通道掩码定位冗余计算,两者协同达成细粒度的冗余计算定位;
- 所提方法取得了SOTA性能,同时具有更好的推理效率。
Sparsity in SISR
我们先来看一下SISR固有的稀疏性,然后调研了SOTA超分方法中的特征稀疏性。

上图给出了Bicubic结果、RCAN结果、HR三者之间的差异图。从上图可以看到:
- 对于平坦区域,Bicubic结果已经足够好,仅仅非常小比例的区域(约17%,即 ∣ I H R − I B i c u b i c S R ∣ > 0.1 |I^{HR} - I_{Bicubic}^{SR}| > 0.1 ∣IHR−IBicubicSR∣>0.1)存在可见的细节损失。也就是说,超分任务存在空域稀疏性。
- 相比Bicubic,RCAN在边缘区域表现更好,同时平坦区域具有相当性能。
- 尽管RCAN聚焦于对边缘区域的纹理进行重建,但是平坦区域同时被均等对待。因此,RCAN存在大量的冗余计算。

上图给出了RCAN骨干模块ReLU后的特征可视化图,从中可以看到:
- 不同通道的空域稀疏性各不相同;
- 有大量通道的稀疏性非常高,比如大于0.8,即仅有边缘、纹理区域被激活了;
总而言之,RCAN对于不重要区域激活了少量通道,对于重要区域激活了更多的通道。受此启发,我们学习稀疏掩码去定位并跳过冗余计算。
SMSR
如前所述,SMSR采用稀疏掩码模块(SMM)进行冗余计算剪枝。每个SMM将生成空域与通道掩码并用于定位冗余计算,见下图;然后采用L个稠密连接稀疏掩码卷积动态跳过冗余计算。由于仅有必要计算才会执行,SMSR可以取得更高的效率,同时具有相当的性能。
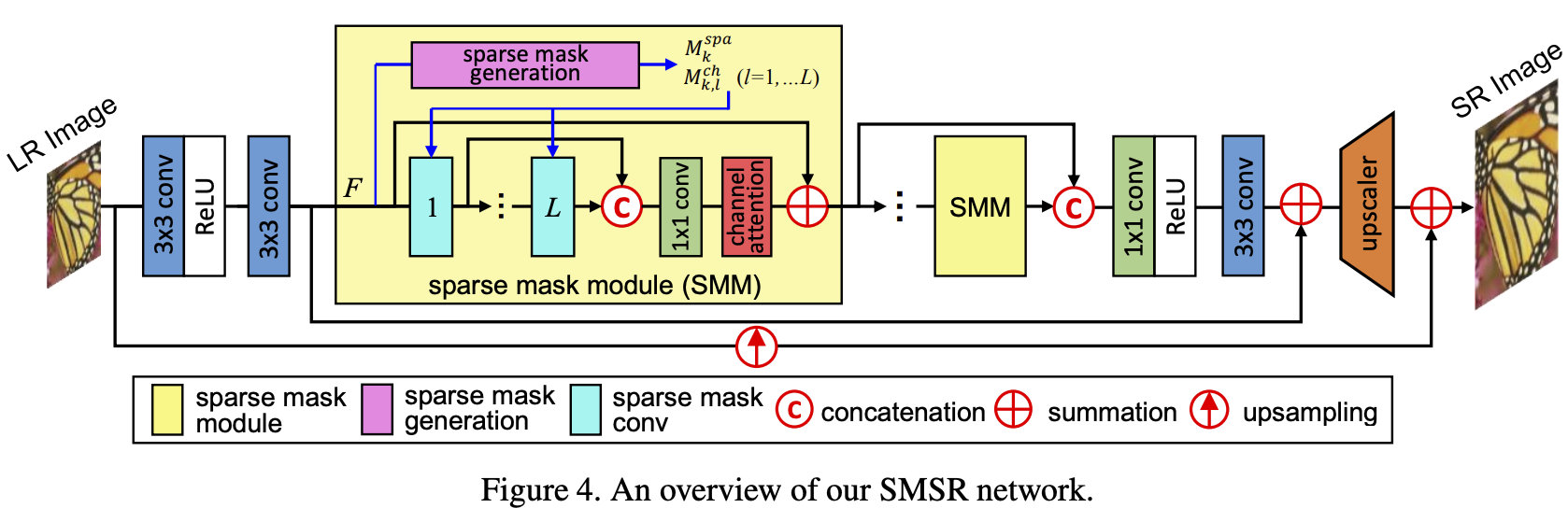
Sparse Mask Generation
Spatial Mask 空域掩码的目的是判别特征的重要区域。为使得二值稀疏掩码可学习,我们采用Gumbel Softmax分布近似one-hot分布。具体来说,输入特征
F
∈
R
C
×
H
×
W
F\in R^{C\times H \times W}
F∈RC×H×W首先融入hourglass模块生成
F
s
p
a
∈
R
2
×
H
×
W
F^{spa} \in R^{2\times H \times W}
Fspa∈R2×H×W,见下图。

然后,采用Gumbel Softmax技巧生成空域掩码
M
k
s
p
a
∈
R
H
×
W
M_k^{spa} \in R^{H\times W}
Mkspa∈RH×W:
M
k
s
p
a
[
x
,
y
]
=
e
x
p
(
(
F
s
p
a
[
1
,
x
,
y
]
+
G
k
s
p
a
[
1
,
x
,
y
]
)
/
τ
)
∑
i
=
1
2
e
x
p
(
(
F
s
p
a
[
i
,
x
,
y
]
+
G
k
s
p
a
[
i
,
x
,
y
]
)
/
τ
)
M_k^{spa}[x,y] = \frac{exp((F^{spa}[1,x,y] + G_k^{spa}[1,x,y])/\tau)}{\sum_{i=1}^2 exp((F^{spa}[i,x,y] + G_k^{spa}[i,x,y])/\tau)}
Mkspa[x,y]=∑i=12exp((Fspa[i,x,y]+Gkspa[i,x,y])/τ)exp((Fspa[1,x,y]+Gkspa[1,x,y])/τ)
当
τ
→
0
\tau \rightarrow 0
τ→0时,Gumbel Softmax退化为均匀分布;当
τ
→
0
\tau \rightarrow 0
τ→0时,Gumbel Softmax分布就变为了one-hot分布。实际上,我们采用比较高的值作为起始,然后逐渐衰减到一个比较小的值以得到二值空域掩码。
Channel Mask 除了空域掩码外,通道研磨用于标记这些不重要区域对应的冗余通道。我们仍采用Gumbel Softmax技巧生成二值通道掩码。对于第
k
t
h
k^{th}
kth个SMM的
l
t
h
l^{th}
lth卷积层,我们将辅助参数
S
k
,
l
∈
R
2
×
C
S_{k,l} \in R^{2\times C}
Sk,l∈R2×CGumbel Softmax层生成通道掩码
M
k
,
l
c
h
∈
R
C
M_{k,l}^{ch} \in R^C
Mk,lch∈RC:
M
k
,
l
c
h
[
c
]
=
e
x
p
(
(
S
k
,
l
[
1
,
c
]
+
G
k
,
l
c
h
[
1
,
c
]
)
/
τ
)
∑
i
=
1
2
e
x
p
(
(
S
k
,
l
[
i
,
c
]
+
G
k
,
l
c
h
[
i
,
c
]
)
/
τ
)
M_{k,l}^{ch}[c] = \frac{exp((S_{k,l}[1,c] + G_{k,l}^{ch}[1,c])/\tau)}{\sum_{i=1}^2 exp((S_{k,l}[i,c] + G_{k,l}^{ch}[i,c])/\tau)}
Mk,lch[c]=∑i=12exp((Sk,l[i,c]+Gk,lch[i,c])/τ)exp((Sk,l[1,c]+Gk,lch[1,c])/τ)
在实验过程中,
S
k
,
l
S_{k,l}
Sk,l按照
N
(
0
,
1
)
N(0,1)
N(0,1)分布随机初始化。
Sparsity Regularization 基于空域与通道掩码,我们定义稀疏项
η
k
,
l
\eta_{k,l}
ηk,l(表示输出特征激活位置的比例):
η
k
,
l
=
1
C
×
H
×
W
∑
c
,
x
,
y
(
(
1
−
M
k
,
l
c
h
)
×
M
k
s
p
a
[
x
,
y
]
+
M
k
,
l
c
h
[
c
]
×
I
[
x
,
y
]
)
\eta_{k,l} = \frac{1}{C \times H \times W} \sum_{c,x,y} ((1-M_{k,l}^{ch}) \times M_k^{spa}[x,y] + M_{k,l}^{ch}[c] \times I[x,y])
ηk,l=C×H×W1c,x,y∑((1−Mk,lch)×Mkspa[x,y]+Mk,lch[c]×I[x,y])
为促使输出特征尽可能的稀疏,我们引入了稀疏正则损失:
L
r
e
g
=
1
K
×
L
∑
k
,
l
η
k
,
l
L_{reg} = \frac{1}{K\times L} \sum_{k,l} \eta_{k,l}
Lreg=K×L1k,l∑ηk,l
Training Strategy 在训练过程中,Gumbel Softmax层的参数
τ
\tau
τ按照
τ
=
m
a
x
(
0.4
,
1
−
t
T
T
e
m
p
)
\tau=max(0.4, 1-\frac{t}{T_{Temp}})
τ=max(0.4,1−TTempt)方式衰减。随着
τ
\tau
τ下降,``Gumbel Softmax分布将朝着one-hot`分布近似,进而生成二值空域与通道掩码。
Inference 由于训练过程中,Gumbel Softmax分布被迫使近似one-hot分布。因此,推理阶段我们可以采用argmax层替换Gumbel Softmax层以生成二值空域与通道掩码,见下图c。
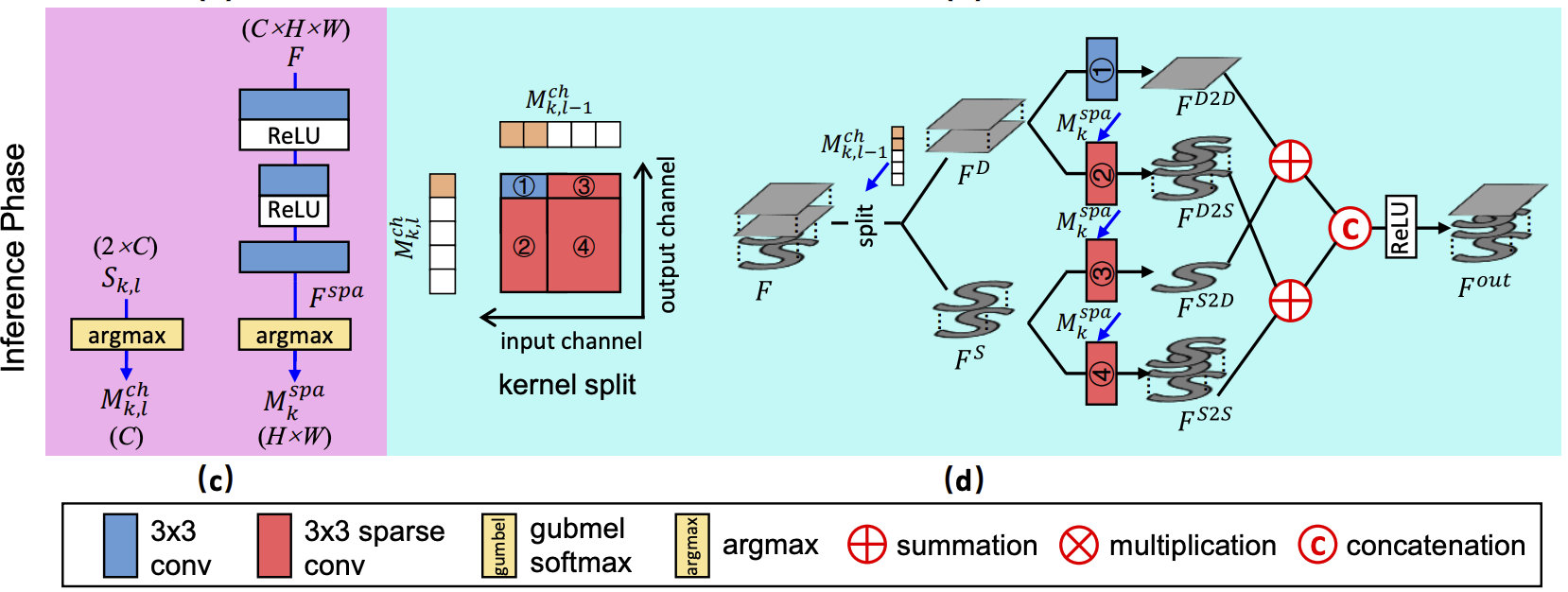
Sparse Mask Convolution
Training Phase 为使得所有位置都可以进行梯度回传,在训练阶段我们并没有显示执行稀疏卷积。相反,我们采用常规卷积的结果与预测的空域和通道掩码相乘,见下图b。具体来说,输入特征乘以 M k , l − 1 c h , ( 1 − M k , l − 1 c h ) M_{k,l-1}^{ch}, (1-M_{k,l-1}^{ch}) Mk,l−1ch,(1−Mk,l−1ch)得到 F D , F S F^D, F^S FD,FS;然后两者送入共享权值的卷积中;其次,所得特征乘以不同的组合系数以激活不同部分特征;最后这些特征相加以生成输出特征。

Inference Phase 在推理阶段,基于预测的空域与通道掩码执行稀疏卷积,见上图d。以第 k t h k^{th} kth个SMM的 l t h l^{th} lth层为例,它的kernel首先按照 M k , l − 1 c h , M k , l c h M_{k,l-1}^{ch}, M_{k,l}^{ch} Mk,l−1ch,Mk,lch划分为四个子核并得到四个卷积;同时,输入特征拆分为 F D , F S F^D, F^S FD,FS;然后, F D F^D FD送入卷积1和卷积2生成 F D 2 D , F D 2 S F^{D2D}, F^{D2S} FD2D,FD2S,类似的 F S F^S FS送入卷积3和卷积4生成 F S 2 D , F S 2 S F^{S2D},F^{S2S} FS2D,FS2S。最后,上述所得四个特征相加、concate得到输出特征。通过稀疏卷积,不重要的区域与通道将被跳过以达成高效推理。
Experiments
接下来,我们将从不同的角度来分析所提方法的有效性,最后再将其与SOTA方法进行对比。

上表对比了稀疏掩码的有效性,从中可以看到:
- 当没有空域与通道掩码时,所有位置与通道均等处理,因此Model1具有非常高的计算量;
- 当采用通道掩码时,冗余通道的所有位置都进行了剪枝,故而Model2等价于剪枝。尽管具有更少的参数和FLOPs,但同时也出现了显著的性能下降,约0.12dB;
- 当采用位置掩码时,由于通道的冗余计算无法很好处理,因此其计算量性能存在轻微的下降;
- 当同时采用位置与通道掩码时,SMSR可以在细粒度层面更好的定位并跳过冗余计算,在节省39%计算量的同时保持同等性能。

上表对比了稀疏性的影响性分析,见上表。可以看到:
- 随着 λ 0 \lambda_0 λ0提升,SMSR具有更高的稀疏性,更多的FLOPs与内存占用得以减少;
- 所提方法在CPU与移动端处理器上取得了显著的加速,比如Kirin 810可以加速55%;
- 受限于稀疏卷积(依赖于特定的加速设计)无法充分GPU的并行特性特性,在GPU端的反而出现了耗时增加;
- 相比其他方法(比如IDN、CARN、FLASR),所提SMSR在移动端处理器上取得了更高的性能、更低的内存占用与更少的推理耗时。
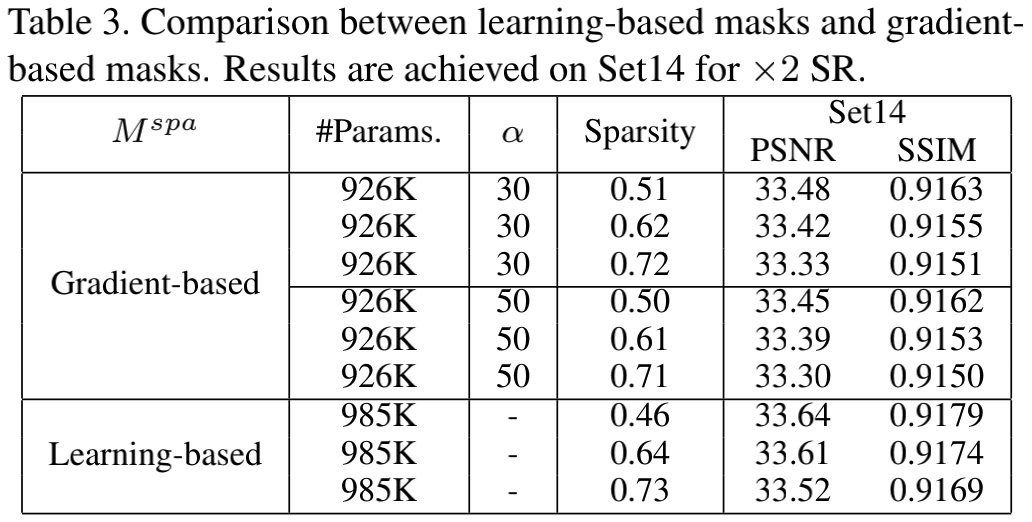
上表对比了可学习掩码与先验掩码的稀疏性以及性能对比,从中可以看到:在同等稀疏性下,基于梯度的掩码方案存在显著的性能下降问题,比如33.53vs33.33。
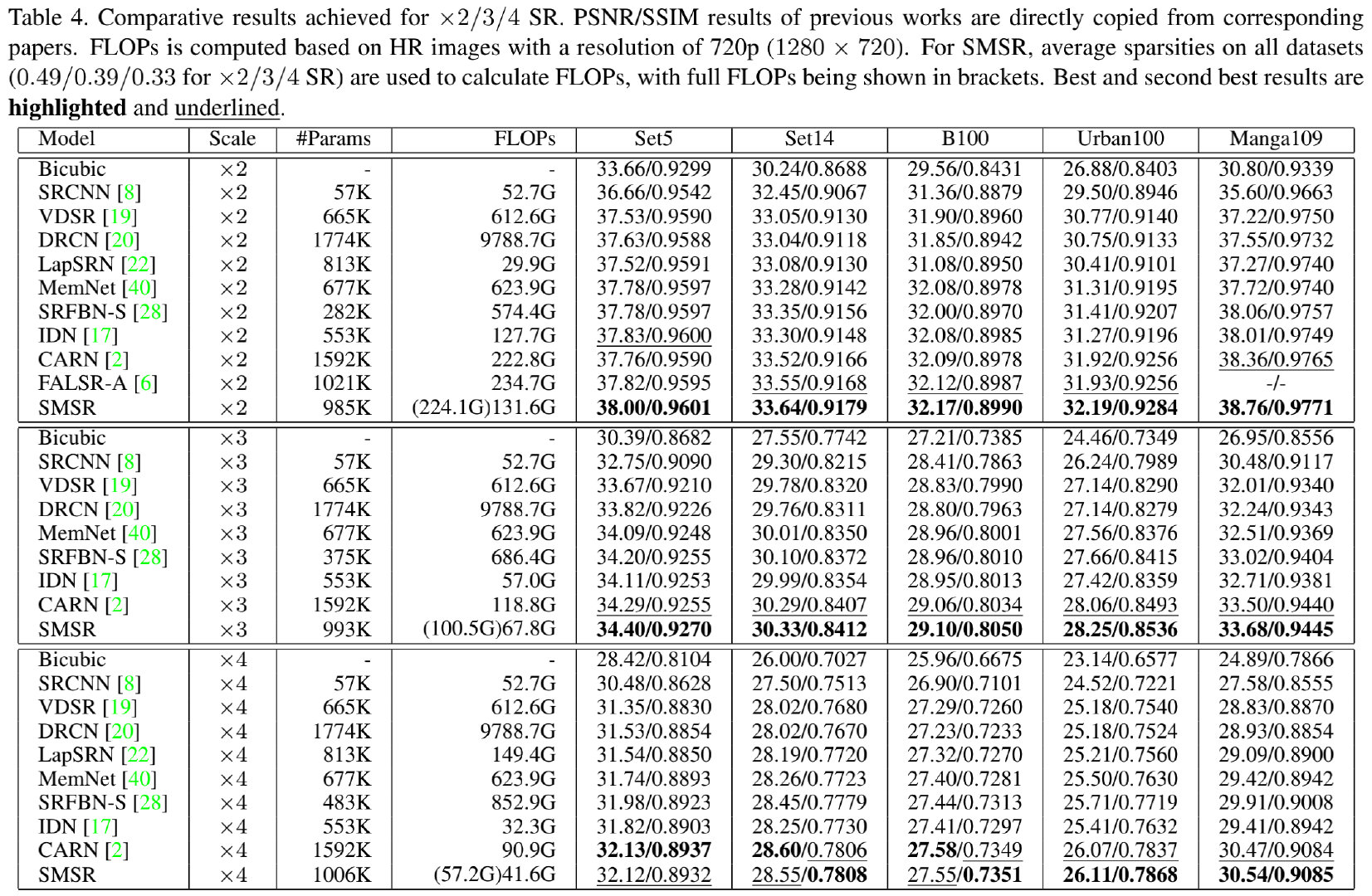
上表给出了所提方法与其他方案的参数量、计算量以及性能对比,从中可以看到:
- 在大多数数据集上,所提SMSR取得了SOTA性能;
- 在x2任务上,相比CARN,所提方法的参数量降低38%,计算量减低41%,同时具有更高性能;
- 相比FALSR-A,在同等模型大小下,SMSR具有更高指标,同时具有更快的推理效率;
- 相比IDN,在同等计算量下,所提方法具有更高的PSNR指标;
- 由于采用了稀疏掩码跳过冗余计算,SMSR在保持同等性能的同时,计算量得到了显著的减小。
- 下图给出了不同方案在参数量、PSNR指标以及FLOPs方面的对比,SMSR具有更高的PSNR,同时具有更低的计算量。


最后,上图给出了不同方法的视觉效果对比。可以看到:
- 在合成数据方面,SMSR结果具有更好的视觉效果且具有更少的伪影;
- 在真实数据方面,SMSR结果具有更好的感知质量,而其他存在可见的伪影问题。
题外语
low-level领域,尤其是图像超分存在大量的计算冗余,这是一个显而易见的现象。但是如何有效的节省这个计算仍是一个关键性的工程问题。
与该文比较类似的一个思路,权值的非结构化剪枝可以达到类似的效果,在具有极高稀疏性的同时,大幅减少理论计算量。但实际推理方面则很难出现显著的加速,稀疏卷积不利用并行加速,同时依赖于特定的指令优化;而现有的推理框架在稀疏卷积方面的支持度显然不够。
另外一个与本文比较类似的是笔者之前分享的CVPR2021|超分性能不变,计算量降低50%,董超等人提出用于low-level加速的ClassSR,它采用一个分类器将图像区域进行划分,不同的区域采用不同复杂度的超分模型进行处理,在保持性能无明显降低的同时,大幅降低计算量。相对来说,ClassSR的工程意义要更大一些。
尽管low-level的计算量问题已经得到了广泛的关注,但截至目前其高计算量问题仍是其应用的关键性阻碍。ClassSR、SMSR从不同区域重建难度、稀疏性角度提出了解决方案,但这些仍然不够,我们期待着更多“实用化”的方案…
推荐阅读
- CMDSR | 为解决多退化盲图像超分问题,浙江大学&字节跳动提出了具有退化信息提取功能的CMDSR
- 你的感知损失可能用错了,沈春华团队提出随机权值广义感知损失
- CVPR2021|超分性能不变,计算量降低50%,董超等人提出用于low-level加速的ClassSR
- SANet|融合空域与通道注意力,南京大学提出置换注意力机制
- GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
- 图像超分中的那些知识蒸馏
- ICLR2021 | 显著提升小模型性能,亚利桑那州立大学&微软联合提出SEED
- RepVGG|让你的ConVNet一卷到底,plain网络首次超过80%top1精度
- Transformer再下一城!low-level多个任务榜首被占领
- 通道注意力新突破!从频域角度出发,浙大提出FcaNet
- 无需额外数据、Tricks、架构调整,CMU开源首个将ResNet50精度提升至80%+新方法
- 46FPS+1080Px2超分+手机NPU,arm提出一种基于重参数化思想的超高效图像超分方案
- 动态卷积超进化!通道融合替换注意力,减少75%参数量且性能显著提升 ICLR 2021
- CVPR2021|“无痛涨点”的ACNet再进化,清华大学&旷视科技提出Inception类型的DBB
- CVPR2021|将无监督对比学习与超分相结合,国防科大提出了用于盲图像超分的无监督退化表达学习DASR















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











