






声明:
使用反向卷积进行图片分割
反向卷积(deconvolution)不止应用于图片分割领域,在各种输入维度小于输出维度的领域都有应用。
1. 什么是图片分割

图片分割是将一个图片划分成不同的区域,进而帮助我们理解图片内容。
现在,CNN是目前最高效的图片识别手段,但却难以解决图片分割问题。why?

CNN的整个卷积过程相当于一个下采样(提取关键特征)的过程,最后在一个特征向量上做分类识别。但是图片分割需要得到每一个像素点的类别,不能直接应用下采样。所以,我们用了上采样的卷积层——反向卷积层(deconvolution layer)
2. 什么是deconvolution
为了在输出层输出一个同等大小的图片,需要进行上采样操作,而简单的上采样会导致信息的丢失。因此,需要一个可训练(层内参数随网络的训练而更新)的上采样层。
大体的网络结构就是先convolution,在deconvolution,最后的输出图片上每个像素点都对应一个label,标识着该像素点属于哪个区域。这种网络结构有点类似于encoder-deconder。
顾名思义,deconvoluion的操作与convolution相反,但不是绝对的反卷积。反卷积的数学含义,通过反卷积可以将通过卷积的输出信号,完全还原输入信号。而事实是,deconvolution只能还原shape大小,不能还原value。
2.1 详解deconvolution
以一维卷积和一维deconvolution为例。
x:1-D输入
y:卷积输出
一维卷积核大小:4
步长:2

一维卷积核
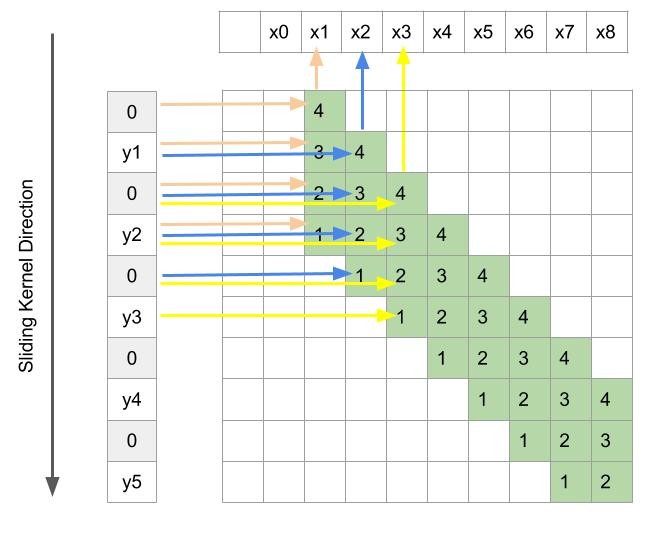
卷积的示意图如下所示:
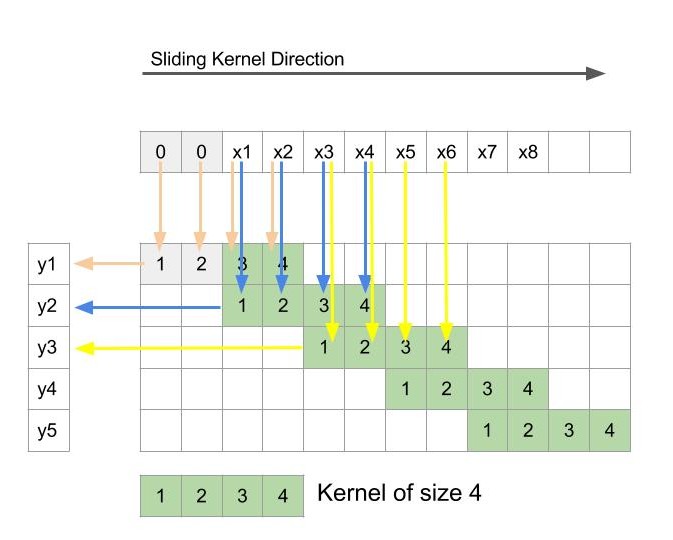
解释:上方是输入x,x前面的两个0是padding的结果;左侧是输出y,是一维卷积核对x进行卷积的结果。
卷积运算就是对应区域相乘再求和。
橙色箭头=> y1=0×1+0×2+x1×3+x2×4 y 1 = 0 × 1 + 0 × 2 + x 1 × 3 + x 2 × 4
蓝色箭头=> y2=x1×1+x2×2+x3×3+x4×4 y 2 = x 1 × 1 + x 2 × 2 + x 3 × 3 + x 4 × 4
黄色箭头=> y3=x3×1+x4×2+x5×3+x6×4 y 3 = x 3 × 1 + x 4 × 2 + x 5 × 3 + x 6 × 4
现在,我们将上述一维卷积操作反转。
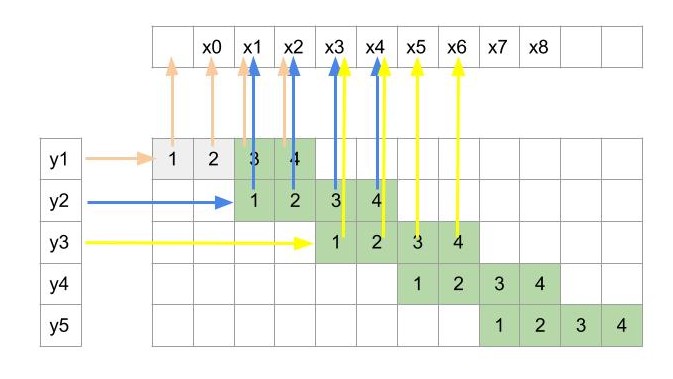
现在输入是y,输出是x,一个输入对4个输出节点产生影响。
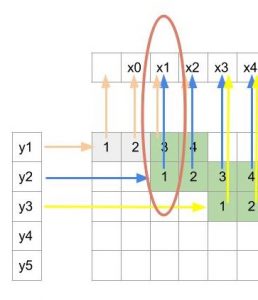
反转后的卷积,输出x1只依赖于输入y1和y2。也就是说,前面卷积操作中,每个输出yi依赖于4个输入xi;反转后的卷积操作中,每个输出xi依赖于2个输入yi。
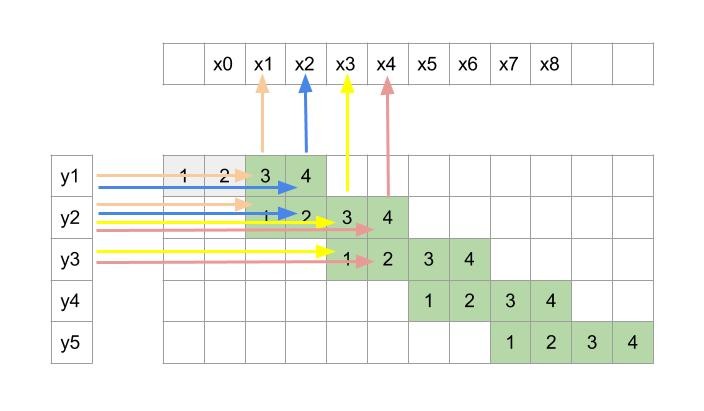
一维deconvolution示意图
在一维deconvolution示意图中可以发现,奇数次的输出
x2i−1
x
2
i
−
1
由卷积核[3, 1]计算而来,偶数次的输出
x2i
x
2
i
由卷积核[4, 2]计算而来。不过这种计算方法效率不高,下面我们来对效率做一点优化。
PERFECT!!
3. 初始化deconvolution层
深度神经网络的性能受层初始化的方式影响很大。 所以让我们来看看解卷积层初始化的细节。前面我们讨论过,反卷积操作的概念源自类似特征上采样的概念。 所以,deconvolution层的初始化思想在很大程度上受到启发和设计。
3.1 图片上采样

假设上图12个点代表有12个像素的一维图片。其中,红色点代表像素值==1,记为O点;绿色点代表像素值==0,记为N点。对于连续的4个点[O1, N1, N2, O2],如果进行3倍图片上采样,即原来有4个正像素点,上采样后要变成12个,即N1和N2都要为正。
根据bilinear插值法, distance(N1,O1)distance(N1,O2)=12 d i s t a n c e ( N 1 , O 1 ) d i s t a n c e ( N 1 , O 2 ) = 1 2 ,所以 contribution(N1,O1)=23 c o n t r i b u t i o n ( N 1 , O 1 ) = 2 3 , contribution(N1,O2)=13 c o n t r i b u t i o n ( N 1 , O 2 ) = 1 3
3.2 初始化deconvolution层

一个五维的卷积核

N1=23×O1+13×O2 N 1 = 2 3 × O 1 + 1 3 × O 2

N2=13×O1+23×O2 N 2 = 1 3 × O 1 + 2 3 × O 2
O2=1×O2 O 2 = 1 × O 2
tensorflow代码实现
def get_bilinear_filter(filter_shape, upscale_factor):
# filter_shape == [width, height, num_in_channels, num_out_channels]
kernel_size = filter_shape[1]
# 卷积核中心
if kernel_size % 2 == 1:
centre_location = upscale_factor - 1
else:
centre_location = upscale_factor - 0.5
bilinear = np.zeros([filter_shape[0], filter_shape[1]])
for x in range(filter_shape[0]):
for y in range(filter_shape[1]):
# 插值计算
value = (1 - abs((x - centre_location) / upscale_factor)) * (1 - abs((y - centre_location)/ upscale_factor))
bilinear[x, y] = value
weights = np.zeros(filter_shape)
for i in range(filter_shape[2]):
weights[:, :, i, i] = bilinear
init = tf.constant_initializer(value=weights, dtype=tf.float32)
bilinear_weights = tf.get_variable(name="decon_bilinear_filter", initializer=init, shape=weights.shape)
return bilinear_weights4. 代码实践
def upsample_layer(bottom, n_channels, name, upscale_factor):
"""
bottom: 输入tensor
n_channels: 通道数
name: 上采样层名称
upscale_factor: 上采样倍率
"""
kernel_size = 2*upscale_factor - upscale_factor%2
stride = upscale_factor
strides = [1, stride, stride, 1]
with tf.variable_scope(name):
# Shape of the bottom tensor
in_shape = tf.shape(bottom)
h = ((in_shape[1] - 1) * stride) + 1
w = ((in_shape[2] - 1) * stride) + 1
new_shape = [in_shape[0], h, w, n_channels]
output_shape = tf.stack(new_shape)
filter_shape = [kernel_size, kernel_size, n_channels, n_channels]
weights = get_bilinear_filter(filter_shape,upscale_factor)
deconv = tf.nn.conv2d_transpose(bottom, weights, output_shape,
strides=strides, padding='SAME')
return deconv这里最困难的就是shape的问题,可以参考这个github连接。















 474
474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









