



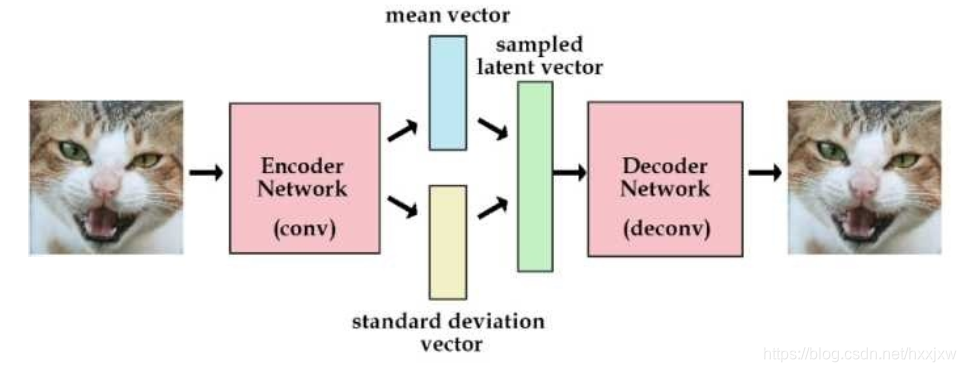
变分编码器(Variational AutoEncoder)是自动编码器的升级版本, 其结构跟自动编码器是类似的, 也由编码器和解码器构成。
回忆一下, 自动编码器有个问题, 就是并不能任意生成图片, 因为我们没有办法自己去构造隐藏向量, 需要通过一张图片输入编码我们才知道得到的隐含向量是什么, 这时我们就可以通过变分自动编码器来解决这个问题。
其实原理特别简单, 只需要在编码过程给它增加一些限制, 迫使其生成的隐含向量能够粗略的遵循一个标准正态分布, 这就是其与一般的自动编码器最大的不同。这样我们生成一张新图片就很简单了, 我们只需要给它一个标准正态分布的随机隐含向量, 这样通过解码器就能够生成我们想要的图片, 而不需要给它一张原始图片先编码。
一般来讲, 我们通过 encoder 得到的隐含向量并不是一个标准的正态分布, 为了衡量两种分布的相似程度, 我们使用 KL divergence, 这是用来衡量两种分布相似程度的统计量,它越小,表示两种概率分布越接近。
在实际情况中,需要在模型的准确率和encoder得到的隐含向量服从标准正态分布之间做一个权衡,所谓模型的准确率就是指解码器生成的图片与原始图片的相似程度。可以让神经网络自己做这个决定,只需要将两者都做一个loss,然后求和作为总的loss,这样网络就能够自己选择如何做才能使这个总的loss下降。
为了避免计算 KL divergence 中的积分, 我们使用重参数的技巧, 不是每次产生一个隐含向量, 而是生成两个向量, 一个表示均值, 一个表示标准差, 这里我们默认编码之后的隐含向量服从一个正态分布的之后, 就可以用一个标准正态分布先乘上标准差再加上均值来合成这个正态分布, 最后 loss 就是希望这个生成的正态分布能够符合一个标准正态分布, 也就是希望均值为 0, 方差为 1
所以标准的变分自动编码器VAE如下
import os import torch import torch.nn.functional as F from torch import nn from torch.utils.data import DataLoader from torchvision.datasets import MNIST from torchvision import transforms from torchvision.utils import save_image from visdom import Visdom class VAE(nn.Module): def __init__(self): super(VAE, self).__init__() self.fc1 = nn.Linear(784, 400) self.fc21 = nn.Linear(400, 20) # mean 均值 self.fc22 = nn.Linear(400, 20) # var 标准差 self.fc3 = nn.Linear(20, 400) self.fc4 = nn.Linear(400, 784) def encode(self, x): x = self.fc1(x) h1 = F.relu(x) mean = self.fc21(h1) var = self.fc22(h1) return mean, var #重参数化 def reparametrize(self, mean, logvar): std = logvar.mul(0.5).exp_() normal = torch.FloatTensor(std.size()).normal_() #生成标准正态分布 if torch.cuda.is_available(): normal = torch.tensor(normal.cuda()) else: normal = torch.tensor(normal) return normal.mul(std).add_(mean) #标准正态分布乘上标准差再加上均值 #这里返回的结果就是我们encoder得到的编码,也就是我们decoder要decode的编码 def decode(self, z): z = self.fc3(z) z = F.relu(z) z = self.fc4(z) z = torch.tanh(z) return z def forward(self, x): mean, logvar = self.encode(x) # 编码 z = self.reparametrize(mean, logvar) # 重新参数化成正态分布 return self.decode(z), mean, logvar # 解码, 同时输出均值方差 def loss_function(recon_image, image, mean, logvar): """ recon_x: generating images x: origin images mu: latent mean logvar: latent log variance """ reconstruction_function = nn.MSELoss(reduction='sum') MSE = reconstruction_function(recon_image, image) # loss = 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2) KLD_element = mean.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar) KLD = torch.sum(KLD_element).mul_(-0.5) # KL divergence return MSE + KLD def to_img(x): ''' 定义一个函数将最后的结果转换回图片 ''' x = 0.5 * (x + 1.) x = x.clamp(0, 1) x = x.view(x.shape[0], 1, 28, 28) return x img_transforms = transforms.Compose([ transforms.ToTensor(), transforms.Normalize([0.5], [0.5]) # 标准化 ]) train_set = MNIST( root='dataset/', transform=img_transforms ) train_data = DataLoader( dataset=train_set, batch_size=128, shuffle=True ) net = VAE() # 实例化网络 if torch.cuda.is_available(): net = net.cuda() optimizer = torch.optim.Adam(net.parameters(), lr=1e-3) viz = Visdom() viz.line([0.], [0.], win='loss', opts=dict(title='loss')) for epoch in range(100): for image, _ in train_data: image = image.view(image.shape[0], -1) image = torch.tensor(image) if torch.cuda.is_available(): image = image.cuda() recon_image, mean, logvar = net(image) loss = loss_function(recon_image, image, mean, logvar) / image.shape[0] # 将 loss 平均 optimizer.zero_grad() loss.backward() optimizer.step() print('epoch: {}, Loss: {:.4f}'.format(epoch, loss.item())) save = to_img(recon_image.cpu().data) if not os.path.exists('./vae_img'): os.mkdir('./vae_img') save_image(save, './vae_img/image_{}.png'.format(epoch)) viz.line([loss.item()], [epoch], win='loss', update='append')
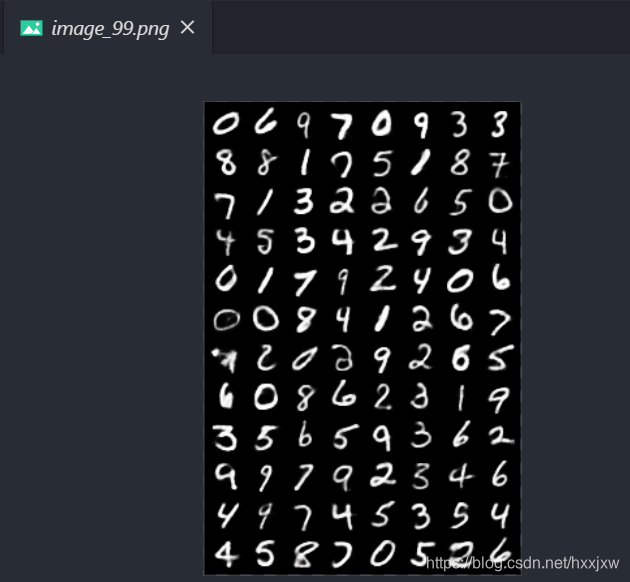
运行100个eopch之后,可以看出来结果比自动编码器清晰一点,本质上VAE就是在encoder的结果添加了高斯噪声,通过训练要使得decoder对噪声有一定的鲁棒性,这样的话我们生成一张图片就没有必须用一张图片先做编码了,可以想象,我们只需要利用训练好的encoder对一张图片编码得到其分布后,符合这个分布的隐含向量理论上都可以通过decoder得到类似这张图片的图片。
KL越小,噪声越大(可以这麽理解,我们强行让z的分布符合正态分布,其和N(0,1)越接近,KL越小,相当于我们添加的噪声越大),所以直觉上来想loss合并后的训练过程:
- 当 decoder 还没有训练好时(重构误差远大于 KL loss),就会适当降低噪声(KL loss 增加),使得拟合起来容易一些(重构误差开始下降);
- 反之,如果 decoder 训练得还不错时(重构误差小于 KL loss),这时候噪声就会增加(KL loss 减少),使得拟合更加困难了(重构误差又开始增加),这时候 decoder 就要想办法提高它的生成能力了。
变分自动编码器虽然比一般的自动编码器效果要好, 而且也限制了其输出的编码(code) 的概率分布, 但是它仍然是通过直接计算生成图片和原始图片的均方误差来生成 loss, 这个方式并不好。
在之后生成对抗网络中, 我们会讲一讲这种方式计算 loss 的局限性, 然后会介绍一种新的训练办法, 就是通过生成对抗的训练方式来训练网络而不是直接比较两张图片的每个像素点的均方误差
Pytorch之经典神经网络Generative Model(二) —— VAE (MNIST)
于 2020-06-22 20:43:50 首次发布
 本文深入解析变分自编码器(VAE)的工作原理,对比自动编码器,介绍了如何通过约束隐含向量的分布,实现图像的生成与重构。通过编码器和解码器的配合,VAE能在生成新图片时无需原始图片输入,只需标准正态分布的随机向量。
本文深入解析变分自编码器(VAE)的工作原理,对比自动编码器,介绍了如何通过约束隐含向量的分布,实现图像的生成与重构。通过编码器和解码器的配合,VAE能在生成新图片时无需原始图片输入,只需标准正态分布的随机向量。
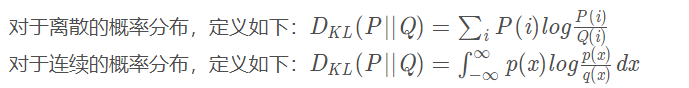

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









