






1998年 Yann Lecun 提出的
也是首次提出CNN
使用LeNet5网络对CIFAR-10数据集进行分类
f指pooling层的feature map大小,即kernel size
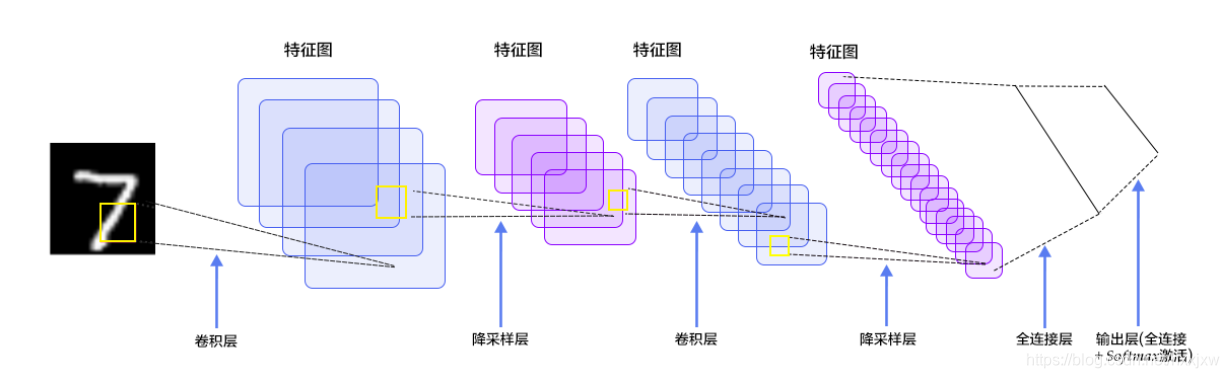
LeNet5网络结构
LeNet5是一个总共5层的卷积神经网络(也有说是7层的)
- 卷积层1
- 池化层(降采样层)1
- 卷积层2
- 池化层(降采样层)2
- 全连接层
- softmax层
即
- (INPUT)
- C1
- S2
- C3
- S4
- C5
- F6
- OUTPUT
OUTPUT是全连接层,softmax层)
说7层的指的是C1-OUTPUT说5层的指的是C1-C5
网络解析(一):LeNet-5详解 - 枫飞飞 - 博客园
CIFAR10数据集
CIFAR10是32*32的
一共6w张照片,其中用于训练的5w张,用于test的1w张


数据加载及预处理
import torchvision from torchvision import transforms from torchvision.transforms import ToPILImage from torchvision import datasets import torch batch_size = 512 # 定义对数据的预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5,), (0.5, 0.5, 0.5,)) ]) trainset = datasets.CIFAR10( root='dataset/', train=True, download=True, transform=transform ) testset = datasets.CIFAR10( root='dataset/', train=False, download=True, transform=transform ) trainloader = torch.utils.data.DataLoader( dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=0 ) # num_workers默认是0 testloader = torch.utils.data.DataLoader( dataset=testset, batch_size=batch_size, shuffle=False, num_workers=0 ) # Dataset对象是一个数据集,可以按下标访问,返回形如(data,label)的数据 classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') data, label = trainset[100] #这是单独取trainset中的一个图片和一个label:第100个 #trainset是5w张 #data 是 [3, 32, 32] 的tensor print(classes[label]) show = ToPILImage() img = show((data + 1) / 2).resize((100, 100)) #show((data + 1) / 2) 是为了还原被归一化的数据。因为我们transforms.Normalize()的时候是对数据x-0.5/0.5,即2x+1 #如果光img = show((data + 1) / 2) 的话,size是(32,32) img.show() # Dataloader是一个可迭代的对象,它将dataset返回的每一条数据样本拼接成一个batch, # 并提供多线程加速优化和数据打乱等操作。当程序对dataset的所有数据遍历完一遍之后, # 对Dataloader也完成了一次迭代。 dataiter = iter(trainloader) images, labels = dataiter.next() # 返回4张图片及标签 print(' '.join('%11s' % classes[labels[j]] for j in range(4))) img = show(torchvision.utils.make_grid((images + 1) / 2)).resize((400, 100)) img.show()


定义网络
nn.Conv2d() 与 F.conv2d()
nn.Conv2d() 类式接口
F.conv2d() 函数式接口
layer = nn.Conv2d(in_channels=1, out_channels=3, kernel_size=(3,3), stride=1, padding=0) #out_channels就是卷积核的数量 #kernel_size,如(3,2), 3等于(3,3)nn.MaxPool2d() 与 F.max_pool2d()
下采样是下采样
avgpool也好,maxpool也好,都是下采样nn.AvgPool2d 与 F.avg_pool2d()
卷积后图片大小的计算公式
关于下采样部分,有用maxpool的,也有用avgpool的,都可以,用maxpool的更多
没有专门的softmax层,softmax层的实现就和 全连接网络(MNIST) 一样,只是一个全连接层最后输出的结点数为10,然后在test的时候用argmax函数选出最大值的下标作为pred_label (注意是test的时候,训练的时候还是直接10维的vector输入loss function)
import torchvision from torchvision import transforms from torchvision.transforms import ToPILImage from torchvision import datasets import torch from torch import nn class Net(nn.Module): def __init__(self): super(Net,self).__init__() # 初始化父类 self.conv_unit = nn.Sequential( # x的输入: [b,3,32,32] 3是彩色图片三通道 nn.Conv2d(in_channels=3, out_channels=6, kernel_size=(5,5), stride=1, padding=0), #此时输出的shape变成了[b,6,28,28] nn.MaxPool2d(kernel_size=(2,2), stride=2, padding=0), # 此时输出的shape变成了[b,6,14,14] nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(5,5), stride=1, padding=0), # 此时输出的shape变成了[b,16,10,10] nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0), # 此时输出的shape变成了[b,16,5,5] ) self.fc_unit = nn.Sequential( # 此时输出的shape变成了[b,16,5,5] nn.Linear(16*5*5, 120), nn.ReLU(), nn.Linear(120,84), nn.ReLU(), nn.Linear(84,10) ) def forward(self, x): #x的输入: [b,3,32,32] 3是彩色图片三通道 batch_size = x.size(0) #就是b # [b,3,32,32] => [b,16,5,5] x = self.conv_unit(x) #下面该是fc层了,但是fc输入的要是二维的,所以需要reshape一下 x = x.view(batch_size, 16*5*5) # [b,16*5*5] => [b,10] x = self.fc_unit(x) return x batch_size=512 # 定义对数据的预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5,), (0.5, 0.5, 0.5,)) ]) trainset = datasets.CIFAR10( root='dataset/', train=True, download=True, transform=transform ) testset = datasets.CIFAR10( root='dataset/', train=False, download=True, transform=transform ) trainloader = torch.utils.data.DataLoader( dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=0 ) # num_workers默认是0 testloader = torch.utils.data.DataLoader( dataset=testset, batch_size=batch_size, shuffle=False, num_workers=0 ) # Dataset对象是一个数据集,可以按下标访问,返回形如(data,label)的数据 # classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # data, label = trainset[100] #这是单独取trainset中的一个图片和一个label:第100个 #trainset是5w张 #data 是 [3, 32, 32] 的tensor # print(classes[label]) # show = ToPILImage() # img = show((data + 1) / 2).resize((100, 100)) # #show((data + 1) / 2) 是为了还原被归一化的数据。因为我们transforms.Normalize()的时候是对数据x-0.5/0.5,即2x+1 # #如果光img = show((data + 1) / 2) 的话,size是(32,32) # img.show() # Dataloader是一个可迭代的对象,它将dataset返回的每一条数据样本拼接成一个batch, # 并提供多线程加速优化和数据打乱等操作。当程序对dataset的所有数据遍历完一遍之后, # 对Dataloader也完成了一次迭代。 # dataiter = iter(trainloader) # images, labels = dataiter.next() # 返回4张图片及标签 # print(' '.join('%11s' % classes[labels[j]] for j in range(4))) # img = show(torchvision.utils.make_grid((images + 1) / 2)).resize((400, 100)) # img.show() net = Net() print(net)
如何理解深度学习源码里经常出现的logits
其实我们现在应该可以很好的理解了,我们说softmax其实就是nn.Linear()的输出是10个节点,但是它不是真正的softmax,因为softmax还要处理一下,取一下对数,全都转换成正值,然后归一化一下,使得10个值加起来为1.
那么,刚才nn.Linear()的10个节点输出,还没经过处理的值,就叫logits


训练网络
nn.CrossEntropyLoss (内置了Softmax),即你输入的时候输入的是 logits 和 label,一个是10维的vector,一个是一个数字,这样可以是因为nn.CrossEntropyLoss里面会先把10维的vector进行softmax
而像上一个全连接层的MNIST数据集使用MSE loss的时候,要么输入10维vector,把label也进行one_hot转换成10维。要么用argmax把logits的10维vector中选出一个最大的
import torchvision from torchvision import transforms from torchvision.transforms import ToPILImage from torchvision import datasets import torch from torch import nn from torch import optim import matplotlib.pyplot as plt class Net(nn.Module): def __init__(self): super(Net,self).__init__() # 初始化父类 self.conv_unit = nn.Sequential( # x的输入: [b,3,32,32] 3是彩色图片三通道 nn.Conv2d(in_channels=3, out_channels=6, kernel_size=(5,5), stride=1, padding=0), #此时输出的shape变成了[b,6,28,28] nn.MaxPool2d(kernel_size=(2,2), stride=2, padding=0), # 此时输出的shape变成了[b,6,14,14] nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(5,5), stride=1, padding=0), # 此时输出的shape变成了[b,16,10,10] nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0), # 此时输出的shape变成了[b,16,5,5] ) self.fc_unit = nn.Sequential( # 此时输出的shape变成了[b,16,5,5] nn.Linear(16*5*5, 120), nn.ReLU(), nn.Linear(120,84), nn.ReLU(), nn.Linear(84,10) ) def forward(self, x): #x的输入: [b,3,32,32] 3是彩色图片三通道 batch_size = x.size(0) #就是b # [b,3,32,32] => [b,16,5,5] x = self.conv_unit(x) #下面该是fc层了,但是fc输入的要是二维的,所以需要reshape一下 x = x.view(batch_size, 16*5*5) # [b,16*5*5] => [b,10] x = self.fc_unit(x) return x batch_size=512 # 定义对数据的预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5,), (0.5, 0.5, 0.5,)) ]) trainset = datasets.CIFAR10( root='dataset/', train=True, download=True, transform=transform ) testset = datasets.CIFAR10( root='dataset/', train=False, download=True, transform=transform ) trainloader = torch.utils.data.DataLoader( dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=0 ) # num_workers默认是0 testloader = torch.utils.data.DataLoader( dataset=testset, batch_size=batch_size, shuffle=False, num_workers=0 ) # Dataset对象是一个数据集,可以按下标访问,返回形如(data,label)的数据 # classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # data, label = trainset[100] #这是单独取trainset中的一个图片和一个label:第100个 #trainset是5w张 #data 是 [3, 32, 32] 的tensor # print(classes[label]) # show = ToPILImage() # img = show((data + 1) / 2).resize((100, 100)) # #show((data + 1) / 2) 是为了还原被归一化的数据。因为我们transforms.Normalize()的时候是对数据x-0.5/0.5,即2x+1 # #如果光img = show((data + 1) / 2) 的话,size是(32,32) # img.show() # Dataloader是一个可迭代的对象,它将dataset返回的每一条数据样本拼接成一个batch, # 并提供多线程加速优化和数据打乱等操作。当程序对dataset的所有数据遍历完一遍之后, # 对Dataloader也完成了一次迭代。 # dataiter = iter(trainloader) # images, labels = dataiter.next() # 返回4张图片及标签 # print(' '.join('%11s' % classes[labels[j]] for j in range(4))) # img = show(torchvision.utils.make_grid((images + 1) / 2)).resize((400, 100)) # img.show() net = Net() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=1e-3) train_loss = [] for epoch in range(3): for idx,data in enumerate(trainloader): inputs, labels = data optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() train_loss.append(loss.item()) if idx % 30 == 0: print(epoch, idx, loss.item()) plt.plot(range(0,len(train_loss)), train_loss, color='blue') plt.legend(['value'], loc='upper right') plt.xlabel('step') plt.ylabel('value') plt.show()


测试
这里为了方便已经加上了model的保存与载入
训练完后先预测一下看看大体效果
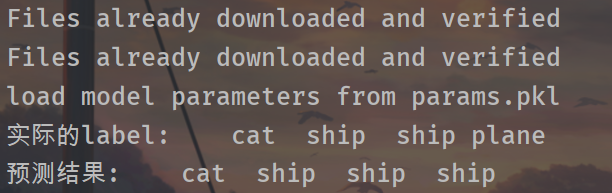
import torchvision from torchvision import transforms from torchvision.transforms import ToPILImage from torchvision import datasets import torch from torch import nn from torch import optim import matplotlib.pyplot as plt import os class Net(nn.Module): def __init__(self): super(Net,self).__init__() # 初始化父类 self.conv_unit = nn.Sequential( # x的输入: [b,3,32,32] 3是彩色图片三通道 nn.Conv2d(in_channels=3, out_channels=6, kernel_size=(5,5), stride=1, padding=0), #此时输出的shape变成了[b,6,28,28] nn.MaxPool2d(kernel_size=(2,2), stride=2, padding=0), # 此时输出的shape变成了[b,6,14,14] nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(5,5), stride=1, padding=0), # 此时输出的shape变成了[b,16,10,10] nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0), # 此时输出的shape变成了[b,16,5,5] ) self.fc_unit = nn.Sequential( # 此时输出的shape变成了[b,16,5,5] nn.Linear(16*5*5, 120), nn.ReLU(), nn.Linear(120,84), nn.ReLU(), nn.Linear(84,10) ) def forward(self, x): #x的输入: [b,3,32,32] 3是彩色图片三通道 batch_size = x.size(0) #就是b # [b,3,32,32] => [b,16,5,5] x = self.conv_unit(x) #下面该是fc层了,但是fc输入的要是二维的,所以需要reshape一下 x = x.view(batch_size, 16*5*5) # [b,16*5*5] => [b,10] x = self.fc_unit(x) return x batch_size=512 # 定义对数据的预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5,), (0.5, 0.5, 0.5,)) ]) trainset = datasets.CIFAR10( root='dataset/', train=True, download=True, transform=transform ) testset = datasets.CIFAR10( root='dataset/', train=False, download=True, transform=transform ) trainloader = torch.utils.data.DataLoader( dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=0 ) # num_workers默认是0 testloader = torch.utils.data.DataLoader( dataset=testset, batch_size=batch_size, shuffle=False, num_workers=0 ) # Dataset对象是一个数据集,可以按下标访问,返回形如(data,label)的数据 classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # data, label = trainset[100] #这是单独取trainset中的一个图片和一个label:第100个 #trainset是5w张 #data 是 [3, 32, 32] 的tensor # print(classes[label]) show = ToPILImage() # img = show((data + 1) / 2).resize((100, 100)) # #show((data + 1) / 2) 是为了还原被归一化的数据。因为我们transforms.Normalize()的时候是对数据x-0.5/0.5,即2x+1 # #如果光img = show((data + 1) / 2) 的话,size是(32,32) # img.show() # Dataloader是一个可迭代的对象,它将dataset返回的每一条数据样本拼接成一个batch, # 并提供多线程加速优化和数据打乱等操作。当程序对dataset的所有数据遍历完一遍之后, # 对Dataloader也完成了一次迭代。 # dataiter = iter(trainloader) # images, labels = dataiter.next() # 返回4张图片及标签 # print(' '.join('%11s' % classes[labels[j]] for j in range(4))) # img = show(torchvision.utils.make_grid((images + 1) / 2)).resize((400, 100)) # img.show() net = Net() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=1e-3) train_loss = [] if os.path.isfile('params.pkl'): net.load_state_dict(torch.load('params.pkl')) print('load model parameters from params.pkl') else: for epoch in range(3): for idx,data in enumerate(trainloader): inputs, labels = data optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() train_loss.append(loss.item()) if idx % 30 == 0: print(epoch, idx, loss.item()) print('Finished Training') torch.save(net.state_dict(), 'params.pkl') print('model has been save into params.pkl.') # plt.plot(range(0,len(train_loss)), train_loss, color='blue') # plt.legend(['value'], loc='upper right') # plt.xlabel('step') # plt.ylabel('value') # plt.show() #此处仅训练了3个epoch(遍历完一遍数据集称为一个epoch),来看看网络有没有效果。将测试图片输入到网络中,计算它的label,然后与实际的label进行比较。 images, labels = next(iter(testloader)) # 一个batch返回4张图片 images = images[0:4,:,:,:] labels = labels[0:4] # print(images.shape) print('实际的label: ', ' '.join('%5s'%classes[labels[j]] for j in range(4))) img = show(torchvision.utils.make_grid(images / 2 - 0.5)).resize((400,100)) plt.imshow(img) plt.show() # 接着计算网络预测的label: # 计算图片在每个类别上的分数 outputs = net(images) # 得分最高的那个类 _, predicted = torch.max(outputs.data, 1) print('预测结果: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) # 已经可以看出效果,准确率50%,但这只是一部分的图片,再来看看在整个测试集上的效果。
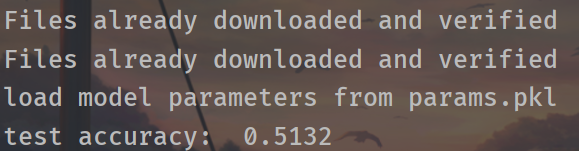
import torchvision from torchvision import transforms from torchvision.transforms import ToPILImage from torchvision import datasets import torch from torch import nn from torch import optim import matplotlib.pyplot as plt import os class Net(nn.Module): def __init__(self): super(Net,self).__init__() # 初始化父类 self.conv_unit = nn.Sequential( # x的输入: [b,3,32,32] 3是彩色图片三通道 nn.Conv2d(in_channels=3, out_channels=6, kernel_size=(5,5), stride=1, padding=0), #此时输出的shape变成了[b,6,28,28] nn.MaxPool2d(kernel_size=(2,2), stride=2, padding=0), # 此时输出的shape变成了[b,6,14,14] nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(5,5), stride=1, padding=0), # 此时输出的shape变成了[b,16,10,10] nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0), # 此时输出的shape变成了[b,16,5,5] ) self.fc_unit = nn.Sequential( # 此时输出的shape变成了[b,16,5,5] nn.Linear(16*5*5, 120), nn.ReLU(), nn.Linear(120,84), nn.ReLU(), nn.Linear(84,10) ) def forward(self, x): #x的输入: [b,3,32,32] 3是彩色图片三通道 batch_size = x.size(0) #就是b # [b,3,32,32] => [b,16,5,5] x = self.conv_unit(x) #下面该是fc层了,但是fc输入的要是二维的,所以需要reshape一下 x = x.view(batch_size, 16*5*5) # [b,16*5*5] => [b,10] x = self.fc_unit(x) return x batch_size=512 # 定义对数据的预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5,), (0.5, 0.5, 0.5,)) ]) trainset = datasets.CIFAR10( root='dataset/', train=True, download=True, transform=transform ) testset = datasets.CIFAR10( root='dataset/', train=False, download=True, transform=transform ) trainloader = torch.utils.data.DataLoader( dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=0 ) # num_workers默认是0 testloader = torch.utils.data.DataLoader( dataset=testset, batch_size=batch_size, shuffle=False, num_workers=0 ) # Dataset对象是一个数据集,可以按下标访问,返回形如(data,label)的数据 classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # data, label = trainset[100] #这是单独取trainset中的一个图片和一个label:第100个 #trainset是5w张 #data 是 [3, 32, 32] 的tensor # print(classes[label]) show = ToPILImage() # img = show((data + 1) / 2).resize((100, 100)) # #show((data + 1) / 2) 是为了还原被归一化的数据。因为我们transforms.Normalize()的时候是对数据x-0.5/0.5,即2x+1 # #如果光img = show((data + 1) / 2) 的话,size是(32,32) # img.show() # Dataloader是一个可迭代的对象,它将dataset返回的每一条数据样本拼接成一个batch, # 并提供多线程加速优化和数据打乱等操作。当程序对dataset的所有数据遍历完一遍之后, # 对Dataloader也完成了一次迭代。 # dataiter = iter(trainloader) # images, labels = dataiter.next() # 返回4张图片及标签 # print(' '.join('%11s' % classes[labels[j]] for j in range(4))) # img = show(torchvision.utils.make_grid((images + 1) / 2)).resize((400, 100)) # img.show() net = Net() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=1e-3) train_loss = [] if os.path.isfile('params.pkl'): net.load_state_dict(torch.load('params.pkl')) print('load model parameters from params.pkl') else: for epoch in range(3): for idx,data in enumerate(trainloader): inputs, labels = data optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() train_loss.append(loss.item()) if idx % 30 == 0: print(epoch, idx, loss.item()) print('Finished Training') torch.save(net.state_dict(), 'params.pkl') print('model has been save into params.pkl.') # plt.plot(range(0,len(train_loss)), train_loss, color='blue') # plt.legend(['value'], loc='upper right') # plt.xlabel('step') # plt.ylabel('value') # plt.show() # #此处仅训练了3个epoch(遍历完一遍数据集称为一个epoch),来看看网络有没有效果。将测试图片输入到网络中,计算它的label,然后与实际的label进行比较。 # images, labels = next(iter(testloader)) # 一个batch返回4张图片 # images = images[0:4,:,:,:] # labels = labels[0:4] # # print(images.shape) # print('实际的label: ', ' '.join('%5s'%classes[labels[j]] for j in range(4))) # img = show(torchvision.utils.make_grid(images / 2 - 0.5)).resize((400,100)) # plt.imshow(img) # plt.show() # # 接着计算网络预测的label: # # 计算图片在每个类别上的分数 # outputs = net(images) # # 得分最高的那个类 # _, predicted = torch.max(outputs.data, 1) # # print('预测结果: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) # # 已经可以看出效果,准确率50%,但这只是一部分的图片,再来看看在整个测试集上的效果。 total_correct = 0 # 由于测试的时候不需要求导,可以暂时关闭autograd,提高速度,节约内存 with torch.no_grad(): for idx, data in enumerate(testloader): inputs, labels = data outputs = net(inputs) pred = outputs.argmax(dim=1) correct = pred.eq(labels).sum().float().item() # correct的结果就是220,386,......, 表示每次512张图片中有几个是预测对了的 total_correct += correct accuracy = total_correct / len(testloader.dataset) # 或者len(testset) print('test accuracy: ', accuracy)训练的准确率远比随机猜测(准确率10%)好,证明网络确实学到了东西。

GPU训练
就像之前把Tensor从CPU转到GPU一样,模型也可以类似地从CPU转到GPU
①net那里改
②training和testing时的 inputs和labels那里改
import torchvision from torchvision import transforms from torchvision.transforms import ToPILImage from torchvision import datasets import torch from torch import nn from torch import optim import matplotlib.pyplot as plt import os class Net(nn.Module): def __init__(self): super(Net,self).__init__() # 初始化父类 self.conv_unit = nn.Sequential( # x的输入: [b,3,32,32] 3是彩色图片三通道 nn.Conv2d(in_channels=3, out_channels=6, kernel_size=(5,5), stride=1, padding=0), #此时输出的shape变成了[b,6,28,28] nn.MaxPool2d(kernel_size=(2,2), stride=2, padding=0), # 此时输出的shape变成了[b,6,14,14] nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(5,5), stride=1, padding=0), # 此时输出的shape变成了[b,16,10,10] nn.MaxPool2d(kernel_size=(2, 2), stride=2, padding=0), # 此时输出的shape变成了[b,16,5,5] ) self.fc_unit = nn.Sequential( # 此时输出的shape变成了[b,16,5,5] nn.Linear(16*5*5, 120), nn.ReLU(), nn.Linear(120,84), nn.ReLU(), nn.Linear(84,10) ) def forward(self, x): #x的输入: [b,3,32,32] 3是彩色图片三通道 batch_size = x.size(0) #就是b # [b,3,32,32] => [b,16,5,5] x = self.conv_unit(x) #下面该是fc层了,但是fc输入的要是二维的,所以需要reshape一下 x = x.view(batch_size, 16*5*5) # [b,16*5*5] => [b,10] x = self.fc_unit(x) return x batch_size=512 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 定义对数据的预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5,), (0.5, 0.5, 0.5,)) ]) trainset = datasets.CIFAR10( root='dataset/', train=True, download=True, transform=transform ) testset = datasets.CIFAR10( root='dataset/', train=False, download=True, transform=transform ) trainloader = torch.utils.data.DataLoader( dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=0 ) # num_workers默认是0 testloader = torch.utils.data.DataLoader( dataset=testset, batch_size=batch_size, shuffle=False, num_workers=0 ) # Dataset对象是一个数据集,可以按下标访问,返回形如(data,label)的数据 classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # data, label = trainset[100] #这是单独取trainset中的一个图片和一个label:第100个 #trainset是5w张 #data 是 [3, 32, 32] 的tensor # print(classes[label]) show = ToPILImage() # img = show((data + 1) / 2).resize((100, 100)) # #show((data + 1) / 2) 是为了还原被归一化的数据。因为我们transforms.Normalize()的时候是对数据x-0.5/0.5,即2x+1 # #如果光img = show((data + 1) / 2) 的话,size是(32,32) # img.show() # Dataloader是一个可迭代的对象,它将dataset返回的每一条数据样本拼接成一个batch, # 并提供多线程加速优化和数据打乱等操作。当程序对dataset的所有数据遍历完一遍之后, # 对Dataloader也完成了一次迭代。 # dataiter = iter(trainloader) # images, labels = dataiter.next() # 返回4张图片及标签 # print(' '.join('%11s' % classes[labels[j]] for j in range(4))) # img = show(torchvision.utils.make_grid((images + 1) / 2)).resize((400, 100)) # img.show() net = Net() net.to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=1e-3) train_loss = [] if os.path.isfile('params.pkl'): net.load_state_dict(torch.load('params.pkl')) print('load model parameters from params.pkl') else: for epoch in range(3): for idx,data in enumerate(trainloader): inputs, labels = data inputs = inputs.to(device) labels = labels.to(device) optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() train_loss.append(loss.item()) if idx % 30 == 0: print(epoch, idx, loss.item()) print('Finished Training') torch.save(net.state_dict(), 'params.pkl') print('model has been save into params.pkl.') # plt.plot(range(0,len(train_loss)), train_loss, color='blue') # plt.legend(['value'], loc='upper right') # plt.xlabel('step') # plt.ylabel('value') # plt.show() # #此处仅训练了3个epoch(遍历完一遍数据集称为一个epoch),来看看网络有没有效果。将测试图片输入到网络中,计算它的label,然后与实际的label进行比较。 # images, labels = next(iter(testloader)) # 一个batch返回4张图片 # images = images[0:4,:,:,:] # labels = labels[0:4] # # print(images.shape) # print('实际的label: ', ' '.join('%5s'%classes[labels[j]] for j in range(4))) # img = show(torchvision.utils.make_grid(images / 2 - 0.5)).resize((400,100)) # plt.imshow(img) # plt.show() # # 接着计算网络预测的label: # # 计算图片在每个类别上的分数 # outputs = net(images) # # 得分最高的那个类 # _, predicted = torch.max(outputs.data, 1) # # print('预测结果: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) # # 已经可以看出效果,准确率50%,但这只是一部分的图片,再来看看在整个测试集上的效果。 total_correct = 0 # 由于测试的时候不需要求导,可以暂时关闭autograd,提高速度,节约内存 with torch.no_grad(): for idx, data in enumerate(testloader): inputs, labels = data inputs = inputs.to(device) labels = labels.to(device) outputs = net(inputs) pred = outputs.argmax(dim=1) correct = pred.eq(labels).sum().float().item() # correct的结果就是220,386,......, 表示每次512张图片中有几个是预测对了的 total_correct += correct accuracy = total_correct / len(testloader.dataset) # 或者len(testset) print('test accuracy: ', accuracy)
如果发现在GPU上并没有比CPU提速很多,实际上是因为网络比较小,GPU没有完全发挥自己的真正实力
















 4246
4246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









