



TPU
TPU, tensor processing unit, 张量处理器, 是Google为机器学习定制的专用芯片(ASIC),专为Google的深度学习框架TensorFlow而设计。
TPU 比现在的 CPU、GPU 在深度学习的推断任务上,要快 15~30 倍。而在能耗比上,更是好出 30~80 倍。
与图形处理器(GPU)相比,TPU采用低精度(8位)计算,以降低每步操作使用的晶体管数量。降低精度对于深度学习的准确度影响很小,但却可以大幅降低功耗、加快运算速度。同时,TPU使用了脉动阵列的设计,用来优化矩阵乘法与卷积运算,减少I/O操作。此外,TPU还采用了更大的片上内存,以此减少对DRAM的访问,从而更大程度地提升性能。
Google在2016年的Google I/O年会上首次公布了TPU。不过在此之前TPU已在Google内部的一些项目中使用了一年多,如Google街景服务、RankBrain以及其旗下DeepMind公司的围棋软件AlphaGo等都用到了TPU。而在2017年的Google I/O年会上,Google又公布了第二代TPU,并将其部署在Google云平台之上。第二代TPU的浮点运算能力高达每秒180万亿次
使用TPU训练tensorflow
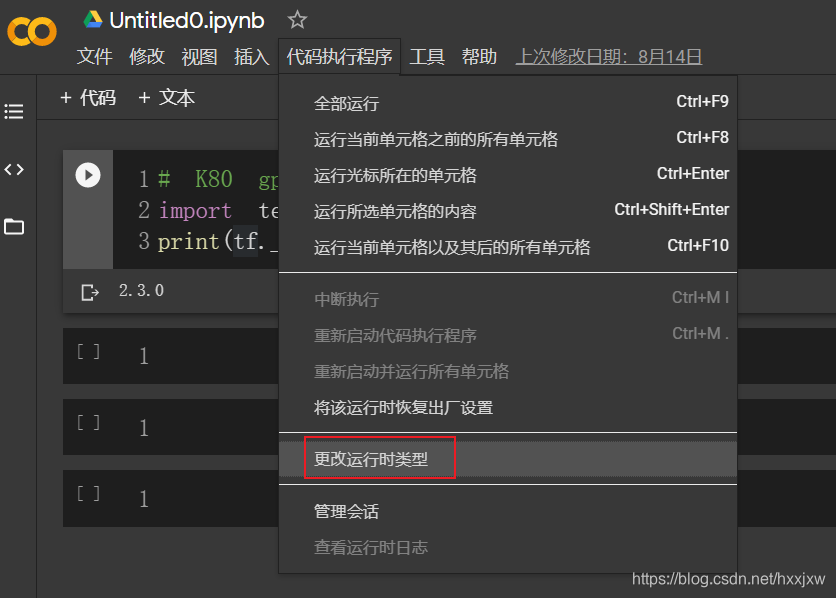
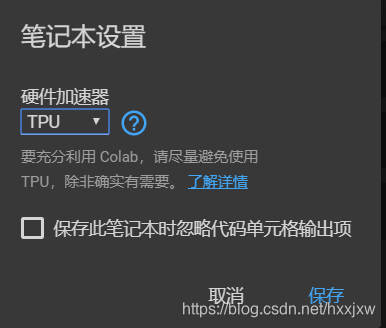
用google colab
直接执行下面代码即可
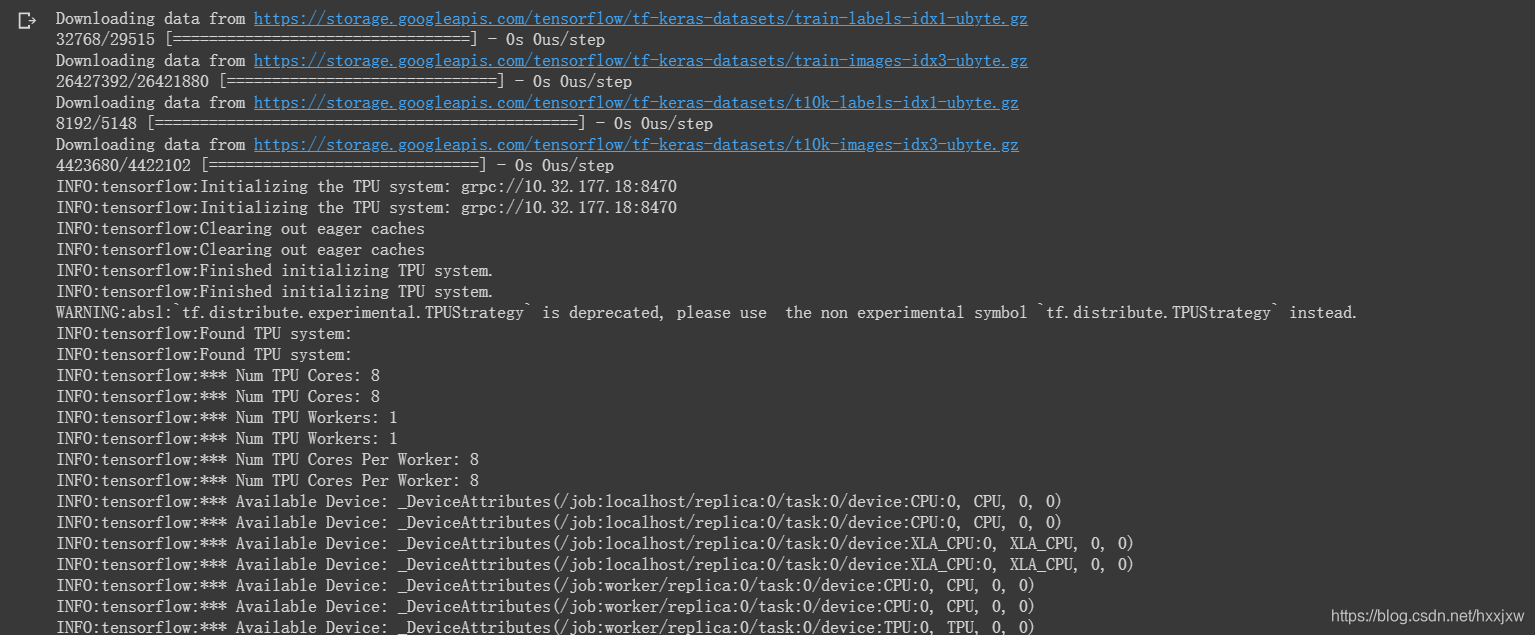
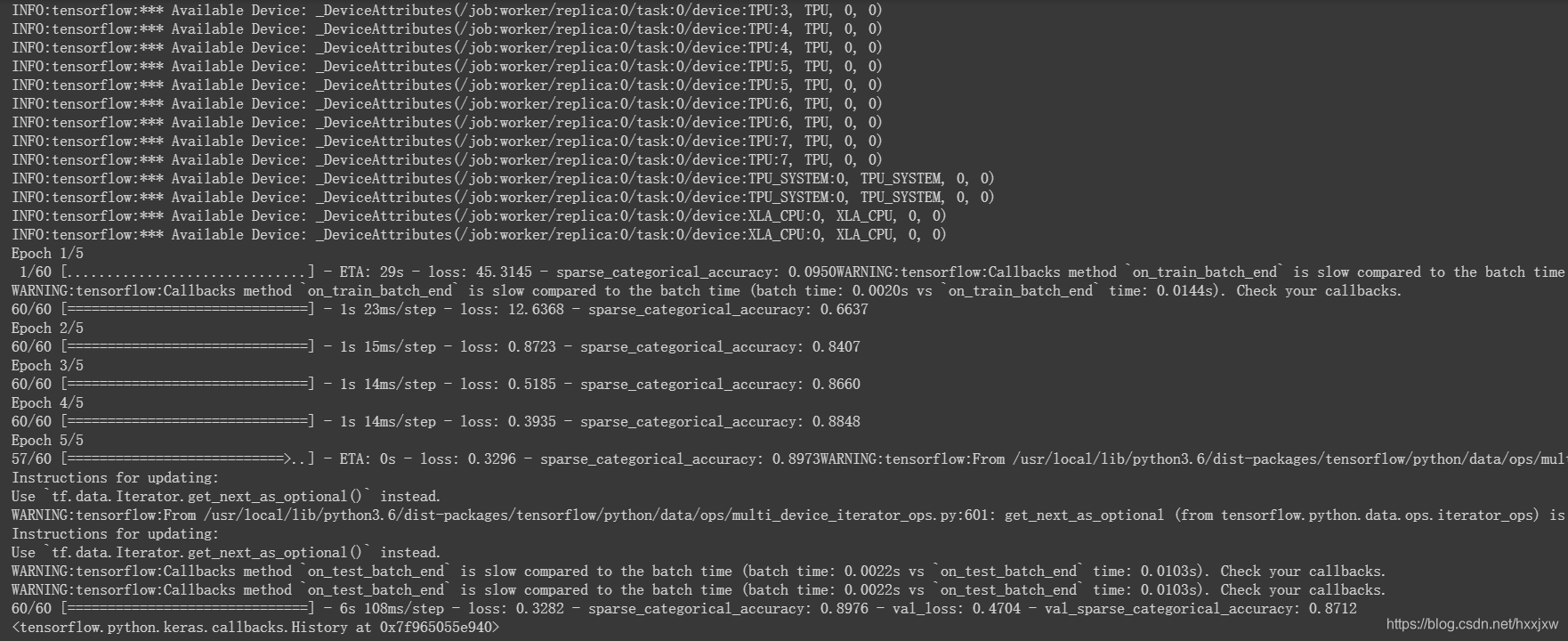
import tensorflow as tf import numpy as np import os (x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data() # add empty color dimension x_train = np.expand_dims(x_train, -1) x_test = np.expand_dims(x_test, -1) def create_model(): model = tf.keras.models.Sequential() model.add(tf.keras.layers.Conv2D(64, (3, 3), input_shape=x_train.shape[1:])) model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2))) model.add(tf.keras.layers.Activation('relu')) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(10)) model.add(tf.keras.layers.Activation('softmax')) return model tpu = tf.distribute.cluster_resolver.TPUClusterResolver() tf.config.experimental_connect_to_cluster(tpu) tf.tpu.experimental.initialize_tpu_system(tpu) strategy = tf.distribute.experimental.TPUStrategy(tpu) with strategy.scope(): model = create_model() model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3), loss=tf.keras.losses.sparse_categorical_crossentropy, metrics=[tf.keras.metrics.sparse_categorical_accuracy]) model.fit( x_train.astype(np.float32), y_train.astype(np.float32), epochs=5, steps_per_epoch=60, validation_data=(x_test.astype(np.float32), y_test.astype(np.float32)), validation_freq=5 )
TPU & 使用TPU训练tensorflow初探(Colab)
最新推荐文章于 2024-11-26 15:18:22 发布
 本文介绍Google专为TensorFlow设计的TPU芯片,在深度学习推断任务上的优势及如何使用Google Colab进行TPU训练。
本文介绍Google专为TensorFlow设计的TPU芯片,在深度学习推断任务上的优势及如何使用Google Colab进行TPU训练。

















 1361
1361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









