







文章目录
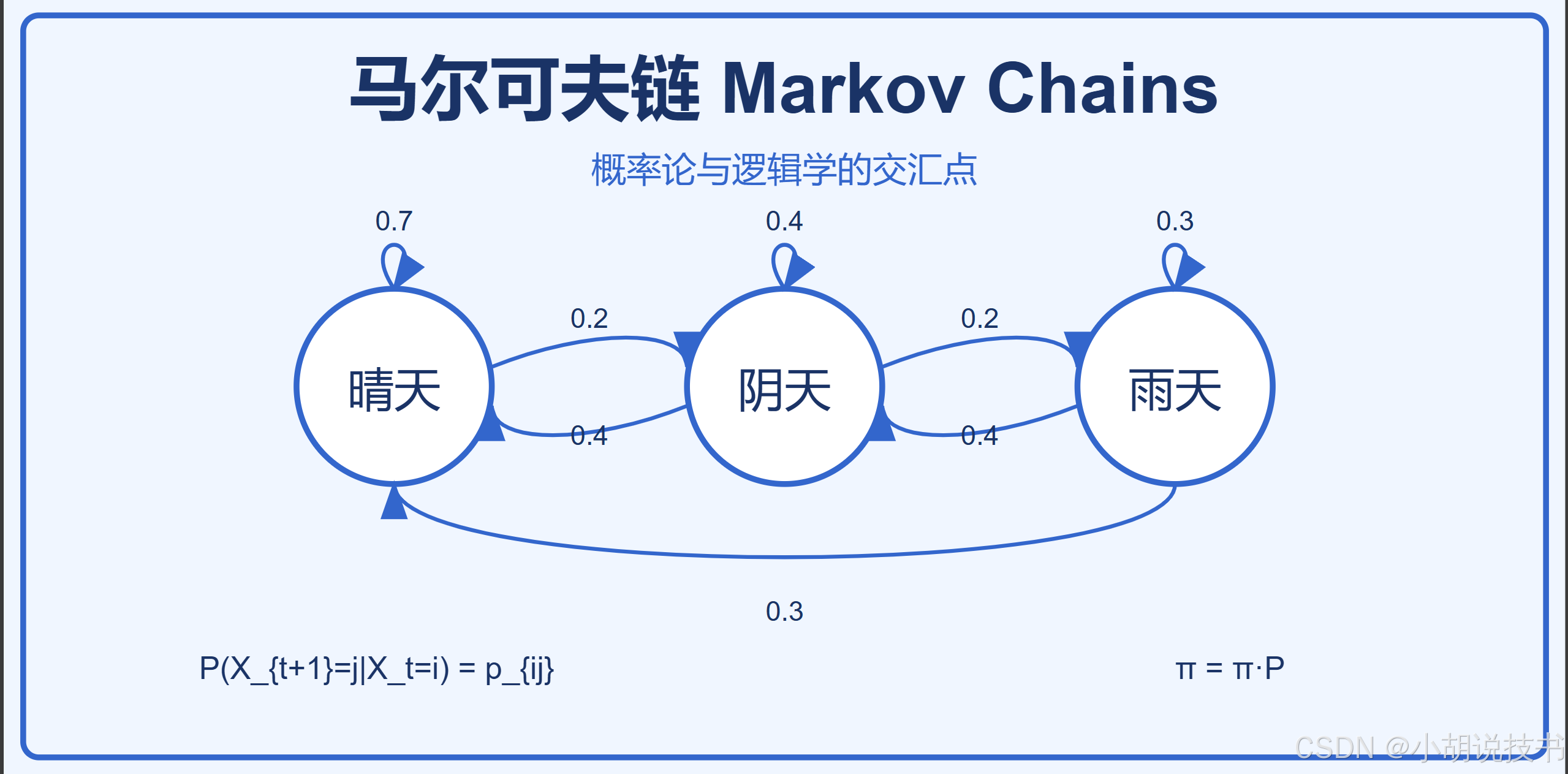
一、马尔可夫链的基本概念与逻辑基础
1.1 随机过程与马尔可夫性质
马尔可夫链(Markov Chain)是概率论与数理统计中的一个核心概念,由俄罗斯数学家安德烈·马尔可夫(Andrey Markov)于20世纪初提出。从逻辑学的角度看,马尔可夫链体现了一种特殊的因果关系思想:系统的未来状态仅依赖于当前状态,而与历史路径无关。
马尔可夫性质(Markov Property):系统下一时刻的状态仅依赖于当前时刻的状态,而与之前的状态历史无关。形式化地说,如果一个随机过程 { X t } \{X_t\} {Xt} 满足条件概率关系: P ( X n + 1 = x ∣ X 0 = x 0 , X 1 = x 1 , . . . , X n = x n ) = P ( X n + 1 = x ∣ X n = x n ) P(X_{n+1}=x|X_0=x_0, X_1=x_1,...,X_n=x_n) = P(X_{n+1}=x|X_n=x_n) P(Xn+1=x∣X0=x0,X1=x1,...,Xn=xn)=P(Xn+1=x∣Xn=xn),则称该随机过程具有马尔可夫性质。
这一性质蕴含了深刻的逻辑内涵:它是对复杂系统的一种简化假设,通过"无记忆性"的特点使得复杂系统的分析变得可行。从哲学上讲,这体现了"现在包含了预测未来所需的全部信息"这一思想。
1.2 状态空间与转移概率
马尔可夫链的基础是其状态空间和转移规则。状态空间定义了系统可能处于的所有状态,而转移规则则通过概率描述了系统如何从一个状态变化到另一个状态。
状态空间(State Space):马尔可夫链中所有可能出现的状态集合,通常表示为 S = { s 1 , s 2 , . . . , s n } S = \{s_1, s_2, ..., s_n\} S={s1,s2,...,sn},可以是有限的或可数无限的。
转移概率(Transition Probability):从状态 i i i 转移到状态 j j j 的概率,表示为 P i j = P ( X n + 1 = j ∣ X n = i ) P_{ij} = P(X_{n+1}=j|X_n=i) Pij=P(Xn+1=j∣Xn=i)。所有转移概率构成的矩阵称为转移概率矩阵(Transition Probability Matrix) P P P。
从逻辑学角度看,转移概率矩阵代表了一种条件概率系统,遵循概率论的公理。矩阵的每一行概率之和必须等于1,这反映了逻辑的完备性:系统在下一时刻必然处于某个状态,不会"凭空消失"。
1.3 马尔可夫链的数学表示
马尔可夫链的数学表示融合了图论、线性代数和概率论。一个马尔可夫链可以表示为一个三元组 ( S , P , π 0 ) (S, P, \pi_0) (S,P,π0),其中:
- S S S 是状态空间
- P P P 是转移概率矩阵
- π 0 \pi_0 π0 是初始状态分布
从线性代数角度看,如果我们用向量 π t \pi_t πt 表示系统在时刻 t t t 的状态分布,那么状态的演化可以表示为矩阵乘法: π t + 1 = π t P \pi_{t+1} = \pi_t P πt+1=πtP。多步转移则可以表示为: π t + n = π t P n \pi_{t+n} = \pi_t P^n πt+n=πtPn。
这种表示方法揭示了马尔可夫链的一个深刻特性:系统的长期行为可以通过矩阵的幂运算来研究,这为我们分析复杂系统提供了强大工具。
二、马尔可夫链的分类与性质
2.1 状态分类:常返状态与瞬态
马尔可夫链中的状态可以根据其长期行为进行分类,这种分类反映了系统的动态特性。
常返状态(Recurrent State):如果从状态 i i i 出发,系统最终必然会返回该状态的概率为1,则称状态 i i i 为常返状态。形式化地,定义 f i i = P ( 系统从状态 i 出发后某时刻会返回状态 i ) f_{ii} = P(系统从状态i出发后某时刻会返回状态i) fii=P(系统从状态i出发后某时刻会返回状态i),若 f i i = 1 f_{ii} = 1 fii=1,则 i i i 是常返状态。
瞬态(Transient State):如果从状态 i i i 出发,系统最终返回该状态的概率小于1,则称状态 i i i 为瞬态。即 f i i < 1 f_{ii} < 1 fii<1。
从逻辑学角度看,这种分类体现了系统中的"必然性"与"可能性"的区别。常返状态表示系统必然会反复访问这些状态,而瞬态则可能在有限时间内被系统"遗忘"。
2.2 周期性与遍历性
马尔可夫链的另一个重要特性是周期性和遍历性,这些特性描述了系统的长期行为模式。
周期性(Periodicity):如果状态 i i i 的周期 d ( i ) > 1 d(i) > 1 d(i)>1,则称状态 i i i 具有周期性。周期定义为: d ( i ) = g c d { n > 0 : P i i ( n ) > 0 } d(i) = gcd\{n > 0: P_{ii}^{(n)} > 0\} d(i)=gcd{n>0:Pii(n)>0},其中 g c d gcd gcd 表示最大公约数, P i i ( n ) P_{ii}^{(n)} Pii(n) 表示 n n n 步后从状态 i i i 返回状态 i i i 的概率。
遍历性(Ergodicity):如果马尔可夫链是不可约的(任意两状态间都存在可达路径)且所有状态都是非周期的(周期为1),则称该马尔可夫链具有遍历性。
遍历性是马尔可夫链中最重要的性质之一,它保证了系统长期行为的稳定性和可预测性。从逻辑角度看,遍历性意味着"充分长的时间内,系统的经验分布将趋近于其理论分布",这为我们研究复杂系统提供了强大的分析工具。
2.3 稳态分布与平衡方程
马尔可夫链最引人注目的特性之一是其稳态行为。在一定条件下,无论初始状态如何,系统的状态分布最终都会收敛到一个固定的分布。
稳态分布(Stationary Distribution):如果存在概率分布 π \pi π,使得 π = π P \pi = \pi P π=πP,则称 π \pi π 为马尔可夫链的稳态分布。
稳态分布满足平衡方程(Balance Equation): π j = ∑ i ∈ S π i P i j \pi_j = \sum_{i \in S} \pi_i P_{ij} πj=∑i∈SπiPij,这意味着流入状态 j j j 的概率质量等于流出的概率质量,系统达到了一种"概率平衡"。
从逻辑学视角看,稳态分布代表了一种"不动点"(fixed point)的思想,这在数学哲学中有深远的意义:复杂的动态系统最终会达到某种平衡状态,这种思想在物理学、经济学和社会科学中都有广泛应用。
三、马尔可夫链的应用
3.1 人工智能与机器学习中的应用
马尔可夫链在人工智能和机器学习领域有广泛的应用,它为处理序列数据和时间序列建模提供了理论基础。
隐马尔可夫模型(Hidden Markov Models, HMMs):隐马尔可夫模型是马尔可夫链的扩展,其中系统的真实状态无法直接观察,但可以通过观察与状态相关的输出来推断。HMMs在语音识别、自然语言处理和生物信息学中有广泛应用。
马尔可夫决策过程(Markov Decision Processes, MDPs):马尔可夫决策过程是马尔可夫链的进一步扩展,引入了动作和奖励的概念。MDPs是强化学习的理论基础,用于建模智能体与环境交互的决策问题。
从逻辑角度看,这些应用展示了马尔可夫链如何被用来构建更复杂的推理系统,特别是在不确定性条件下的决策推理。
3.2 随机文本生成与自然语言处理
马尔可夫链在文本生成和自然语言处理中有经典应用。通过分析文本中单词或字符的转移概率,可以构建简单但有效的语言模型。
N-gram模型:N-gram模型是一种基于马尔可夫假设的语言模型,假设当前单词仅依赖于前面N-1个单词。例如,二元语法(bigram)模型假设当前单词只依赖于前一个单词。
尽管现代自然语言处理已经发展出更复杂的模型(如Transformer和BERT),但马尔可夫链提供的基本思想——序列中的元素依赖于其前面的有限上下文——仍然是许多语言模型的核心概念。
3.3 蒙特卡洛方法与马尔可夫链蒙特卡洛
马尔可夫链蒙特卡洛(Markov Chain Monte Carlo, MCMC)方法是一类强大的算法,用于从复杂的概率分布中抽样。
MCMC方法:MCMC通过构造马尔可夫链,使其稳态分布等于目标分布,然后通过模拟该马尔可夫链来生成符合目标分布的样本。常见的MCMC算法包括Metropolis-Hastings算法和Gibbs采样。
从逻辑学角度看,MCMC方法展示了马尔可夫链如何被用作推理工具:在直接计算变得困难时,我们可以通过模拟随机过程来获得近似结果,这种思想在现代贝叶斯统计和概率推理中至关重要。
四、马尔可夫链的Python实现
4.1 简单马尔可夫链模拟
以下是一个简单的马尔可夫链模拟,我们模拟一个天气模型,有"晴天"、"阴天"和"雨天"三种状态:
import numpy as np
import matplotlib.pyplot as plt
# 定义状态空间
states = ["晴天", "阴天", "雨天"]
# 定义转移概率矩阵
transition_matrix = np.array([
[0.7, 0.2, 0.1], # 晴天转移概率
[0.4, 0.4, 0.2], # 阴天转移概率
[0.3, 0.4, 0.3] # 雨天转移概率
])
# 初始状态分布
initial_state = 0 # 从晴天开始
# 模拟马尔可夫链
def simulate_markov_chain(transition_matrix, initial_state, num_steps):
# 记录状态序列
states_sequence = [initial_state]
current_state = initial_state
# 模拟状态转移
for _ in range(num_steps):
# 根据当前状态的转移概率选择下一个状态
next_state = np.random.choice(len(transition_matrix), p=transition_matrix[current_state])
states_sequence.append(next_state)
current_state = next_state
return states_sequence
# 运行模拟
np.random.seed(42) # 设置随机种子以确保结果可重现
sequence = simulate_markov_chain(transition_matrix, initial_state, 100)
# 统计各状态出现的频率
state_counts = np.zeros(len(states))
for state in sequence:
state_counts[state] += 1
frequencies = state_counts / len(sequence)
def compute_stationary_distribution(transition_matrix):
# 构建矩阵方程 (P^T - I)π = 0,并替换一行为和为1的约束
P = transition_matrix.T
n = P.shape[0]
A = P - np.eye(n)
# 替换最后一行为全1(概率和为1的约束)
A[-1] = np.ones(n)
# 右侧向量,除了最后一个方程是1,其他都是0
b = np.zeros(n)
b[-1] = 1
# 求解线性方程组
pi = np.linalg.solve(A, b)
return pi
theoretical_distribution = compute_stationary_distribution(transition_matrix)
# 绘制结果
plt.figure(figsize=(10, 6))
bar_width = 0.35
index = np.arange(len(states))
plt.bar(index, frequencies, bar_width, label='模拟频率')
plt.bar(index + bar_width, theoretical_distribution, bar_width, label='理论稳态分布')
plt.xlabel('状态')
plt.ylabel('概率')
plt.title('马尔可夫链模拟与理论稳态分布对比')
plt.xticks(index + bar_width/2, states)
plt.legend()
plt.tight_layout()
plt.show()
这个例子展示了马尔可夫链的模拟过程,以及如何计算和验证稳态分布。从逻辑学角度看,这个模拟展示了理论预测与实际观察的一致性,这是科学方法论的核心。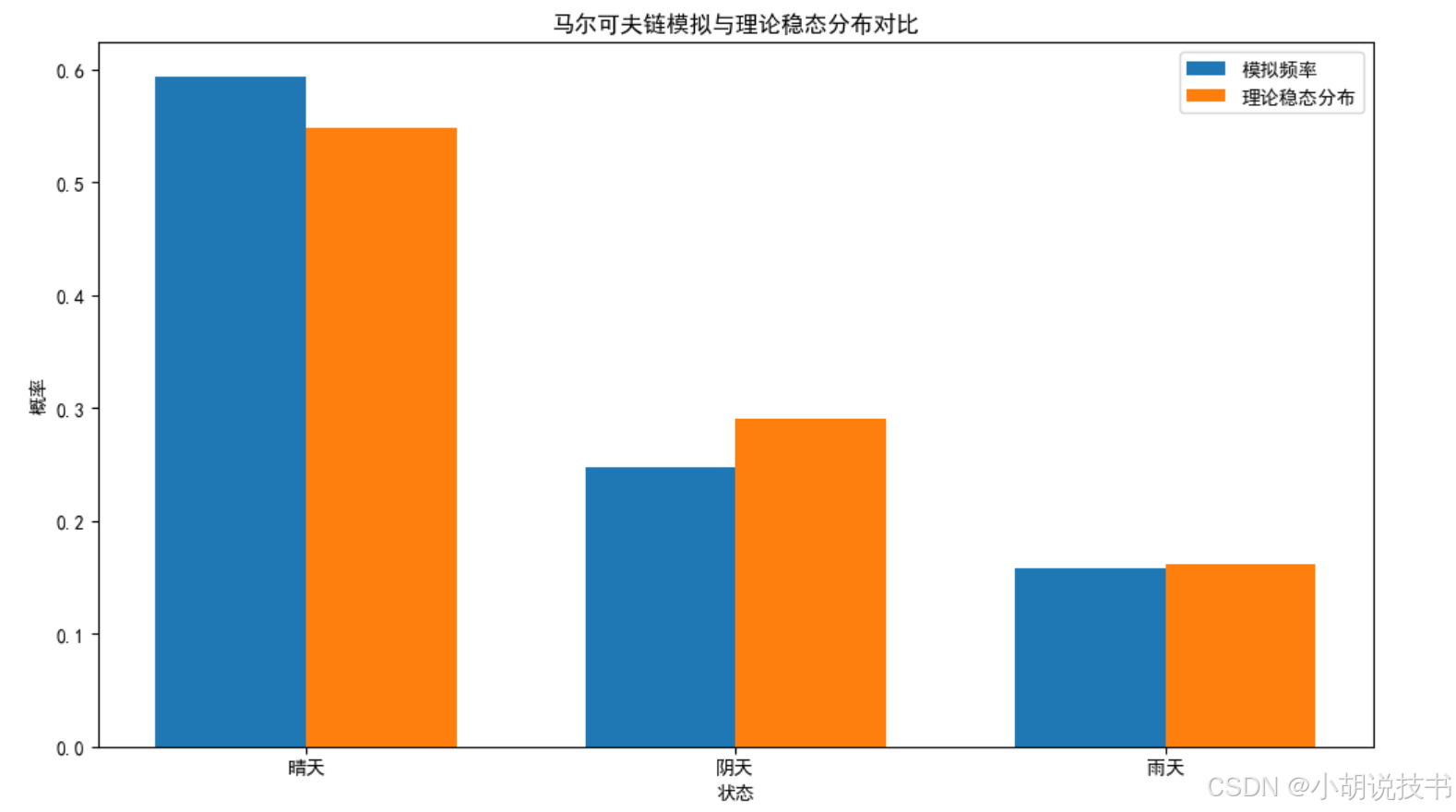
4.2 文本生成实例
以下是一个基于马尔可夫链的简单文本生成器:
import random
import re
class MarkovTextGenerator:
def __init__(self, order=2):
self.order = order # 马尔可夫链的阶数
self.model = {} # 存储转移概率的字典
self.starters = [] # 可用作句子开头的n元组
def train(self, text):
"""从文本中学习转移概率"""
# 预处理文本
text = re.sub(r'\s+', ' ', text).strip()
words = text.split()
# 处理句子开头
for i in range(len(words) - self.order):
window = tuple(words[i:i+self.order])
if re.match(r'^[A-Z]', words[i]) and words[i-1][-1] in '.!?':
self.starters.append(window)
# 构建模型
if window not in self.model:
self.model[window] = []
self.model[window].append(words[i+self.order])
def generate(self, max_words=100):
"""生成文本"""
if not self.model or not self.starters:
return "需要先训练模型"
# 选择起始词组
current = random.choice(self.starters)
result = list(current)
# 生成文本
for _ in range(max_words - self.order):
if current not in self.model:
break
# 根据转移概率选择下一个词
next_word = random.choice(self.model[current])
result.append(next_word)
# 更新当前状态
current = tuple(result[-self.order:])
return ' '.join(result)
# 示例使用
sample_text = """
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大。
机器学习是人工智能的一个分支,它使用各种算法来解析数据、学习数据,然后对新数据进行预测。机器学习算法通过构建模型从数据中学习,以便能够执行没有明确编程的任务。深度学习是机器学习的一个子领域,它使用多层神经网络来模拟人脑的工作方式。
自然语言处理是人工智能的另一个重要分支,它赋予机器理解人类语言的能力。自然语言处理技术使得像机器翻译、情感分析和语音识别这样的应用成为可能。
"""
generator = MarkovTextGenerator(order=2)
generator.train(sample_text)
generated_text = generator.generate(max_words=50)
print(generated_text)
这个例子展示了如何使用马尔可夫链来建模文本并生成新的文本。从逻辑学角度看,这种生成模型体现了一种条件概率推理:基于当前的上下文预测下一个最可能的词。
4.3 马尔可夫决策过程实现
以下是一个简单的马尔可夫决策过程(MDP)实现,用于解决一个简单的网格世界问题:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
class GridWorldMDP:
def __init__(self, width=4, height=4):
self.width = width
self.height = height
self.n_states = width * height
self.n_actions = 4 # 上、右、下、左
# 状态转移概率
self.transition_probs = np.zeros((self.n_states, self.n_actions, self.n_states))
# 奖励函数
self.rewards = np.zeros((self.n_states, self.n_actions, self.n_states))
# 设置目标状态和障碍物
self.goal_state = self.width * self.height - 1 # 右下角
self.obstacle_states = [5, 7, 11, 12] # 一些障碍物位置
# 初始化转移概率和奖励
self._init_transition_probs()
self._init_rewards()
def _init_transition_probs(self):
# 定义动作:0=上, 1=右, 2=下, 3=左
for s in range(self.n_states):
# 跳过目标状态和障碍物
if s == self.goal_state or s in self.obstacle_states:
continue
row, col = s // self.width, s % self.width
# 上
next_row = max(0, row - 1)
next_state = next_row * self.width + col
if next_state not in self.obstacle_states:
self.transition_probs[s, 0, next_state] = 1.0
else:
self.transition_probs[s, 0, s] = 1.0 # 如果是障碍物,保持原位
# 右
next_col = min(self.width - 1, col + 1)
next_state = row * self.width + next_col
if next_state not in self.obstacle_states:
self.transition_probs[s, 1, next_state] = 1.0
else:
self.transition_probs[s, 1, s] = 1.0
# 下
next_row = min(self.height - 1, row + 1)
next_state = next_row * self.width + col
if next_state not in self.obstacle_states:
self.transition_probs[s, 2, next_state] = 1.0
else:
self.transition_probs[s, 2, s] = 1.0
# 左
next_col = max(0, col - 1)
next_state = row * self.width + next_col
if next_state not in self.obstacle_states:
self.transition_probs[s, 3, next_state] = 1.0
else:
self.transition_probs[s, 3, s] = 1.0
def _init_rewards(self):
# 到达目标的奖励
for s in range(self.n_states):
for a in range(self.n_actions):
self.rewards[s, a, self.goal_state] = 1.0
# 对障碍物施加负奖励
for obs in self.obstacle_states:
self.rewards[s, a, obs] = -1.0
def value_iteration(self, gamma=0.9, epsilon=1e-6):
"""价值迭代算法求解最优策略"""
# 初始化价值函数
V = np.zeros(self.n_states)
while True:
# 保存旧的价值函数
V_old = V.copy()
for s in range(self.n_states):
# 跳过目标状态和障碍物
if s == self.goal_state or s in self.obstacle_states:
continue
# 计算每个动作的期望回报
q_values = np.zeros(self.n_actions)
for a in range(self.n_actions):
for next_s in range(self.n_states):
q_values[a] += self.transition_probs[s, a, next_s] * (
self.rewards[s, a, next_s] + gamma * V_old[next_s]
)
# 选择最佳动作的价值
V[s] = np.max(q_values)
# 检查收敛
if np.max(np.abs(V - V_old)) < epsilon:
break
# 提取最优策略
policy = np.zeros(self.n_states, dtype=int)
for s in range(self.n_states):
if s == self.goal_state or s in self.obstacle_states:
continue
q_values = np.zeros(self.n_actions)
for a in range(self.n_actions):
for next_s in range(self.n_states):
q_values[a] += self.transition_probs[s, a, next_s] * (
self.rewards[s, a, next_s] + gamma * V[next_s]
)
policy[s] = np.argmax(q_values)
return V, policy
def visualize_policy(self, policy):
"""可视化策略"""
plt.figure(figsize=(8, 8))
# 创建网格
grid = np.zeros((self.height, self.width))
# 标记障碍物和目标
for obs in self.obstacle_states:
row, col = obs // self.width, obs % self.width
grid[row, col] = -1 # 障碍物
row, col = self.goal_state // self.width, self.goal_state % self.width
grid[row, col] = 2 # 目标
# 绘制网格
cmap = ListedColormap(['white', 'black', 'green'])
plt.imshow(grid, cmap=cmap)
# 绘制策略(箭头)
for s in range(self.n_states):
if s == self.goal_state or s in self.obstacle_states:
continue
row, col = s // self.width, s % self.width
action = policy[s]
# 箭头方向
if action == 0: # 上
plt.arrow(col, row, 0, -0.3, head_width=0.1, head_length=0.1, fc='blue', ec='blue')
elif action == 1: # 右
plt.arrow(col, row, 0.3, 0, head_width=0.1, head_length=0.1, fc='blue', ec='blue')
elif action == 2: # 下
plt.arrow(col, row, 0, 0.3, head_width=0.1, head_length=0.1, fc='blue', ec='blue')
elif action == 3: # 左
plt.arrow(col, row, -0.3, 0, head_width=0.1, head_length=0.1, fc='blue', ec='blue')
# 设置坐标
plt.grid(True)
plt.xticks(np.arange(self.width))
plt.yticks(np.arange(self.height))
plt.title('最优策略')
plt.show()
# 创建并求解MDP
mdp = GridWorldMDP(width=4, height=4)
values, policy = mdp.value_iteration()
# 可视化结果
mdp.visualize_policy(policy)
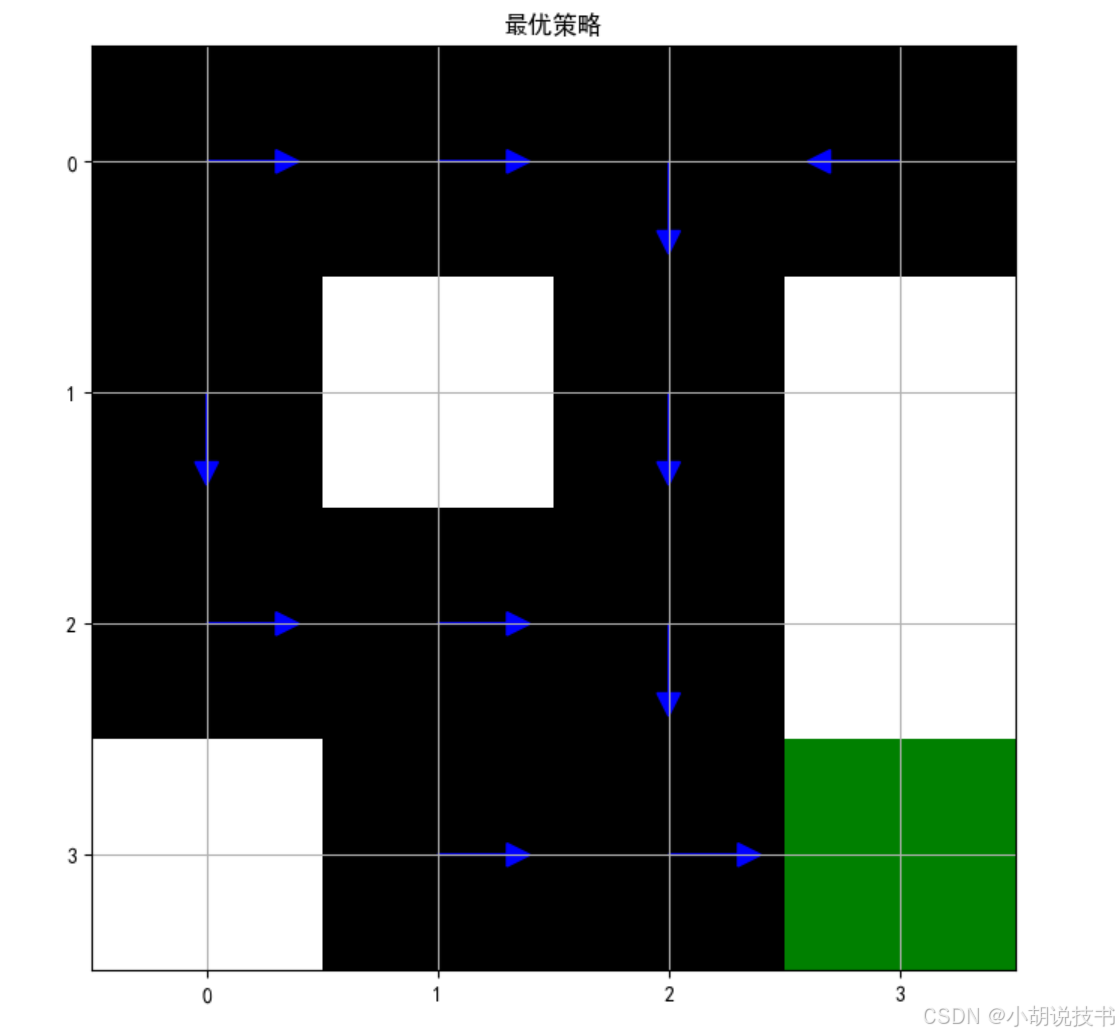
这个例子实现了一个网格世界中的马尔可夫决策过程,并使用价值迭代算法求解最优策略。从逻辑学角度看,这种求解方法体现了一种基于动态规划的推理方式:通过迭代改进价值估计,最终收敛到最优解。
五、逻辑学视角下的马尔可夫链
5.1 逻辑推理与概率推理的联系
马尔可夫链在逻辑学中的地位体现了确定性逻辑与概率逻辑的桥接。传统逻辑关注的是确定性的推理,即从已知前提严格推导出结论。而马尔可夫链则代表了一种概率性推理,其中的"推理"结果是具有不确定性的。
逻辑推理与概率推理:传统逻辑推理基于确定性规则(如三段论、命题逻辑等),而概率推理则基于不确定性和随机性。马尔可夫链提供了将确定性规则(转移矩阵)与不确定性结果(概率分布)结合的框架。
从哲学角度看,马尔可夫链代表了一种"软逻辑"(soft logic)的思想,即推理的结果不是非黑即白的,而是具有概率分布的。这种思想在处理现实世界的复杂性和不确定性时尤为重要。
5.2 马尔可夫逻辑网络简介
马尔可夫逻辑网络(Markov Logic Networks, MLN)是一种将马尔可夫网络与一阶逻辑相结合的概率图模型,它为不确定知识提供了表达和推理的方式。
马尔可夫逻辑网络:MLN由一组带权重的一阶逻辑公式组成,可以看作是一种模板,用于生成马尔可夫随机场。一阶逻辑公式的权重反映了该公式的"强度":权重越高,违反该公式的可能性越小。
从逻辑学角度看,MLN代表了一种知识表示的革新:它不仅能表示"什么是真的",还能表示"有多大可能是真的"。这种融合了逻辑和概率的框架可以处理现实世界中的不确定性和复杂性。
5.3 时序逻辑与马尔可夫链
时序逻辑(Temporal Logic)与马尔可夫链的结合提供了分析动态系统的强大工具。时序逻辑关注的是命题在不同时间点的真值如何变化,而马尔可夫链则提供了一种对这种变化进行概率建模的方式。
概率时序逻辑(Probabilistic Temporal Logic):将时序逻辑与马尔可夫过程结合,可以表达和推理形如"事件A发生后,事件B在未来5个时间单位内发生的概率至少为0.9"的陈述。
这种结合体现了逻辑学与概率论的深度融合,为形式化验证、系统分析和人工智能推理提供了理论基础。
专业名称附录表
A
- 阿贝尔链(Abelian Chain):状态转移矩阵中所有元素可交换的马尔可夫链
- 吸收态(Absorbing State):一旦进入就无法离开的状态
B
- 不可约链(Irreducible Chain):任意两个状态之间都存在可达路径的马尔可夫链
- 闭集(Closed Set):一旦进入就无法离开的状态集合
C
- 常返性(Recurrence):从某状态出发,最终返回该状态的概率为1的性质
- 常返状态(Recurrent State):具有常返性的状态
D
- 等价类(Equivalence Class):具有相同可达性质的状态集合
- 多步转移概率(n-step Transition Probability):n步后从状态i到状态j的概率
F
- 非周期性(Aperiodicity):状态的周期为1的性质
- 分布收敛定理(Convergence Theorem):描述马尔可夫链长期行为的定理
G
- 概率矩阵(Stochastic Matrix):每行元素之和为1的非负矩阵
- 鸽巢原理(Pigeonhole Principle):在马尔可夫链分析中常用的组合数学原理
H
- 混合时间(Mixing Time):马尔可夫链接近稳态分布所需的时间
- 汉密尔顿路径(Hamiltonian Path):在马尔可夫链的状态转移图中访问每个状态恰好一次的路径
J
- 聚类系数(Clustering Coefficient):用于分析马尔可夫链网络结构的度量
- 均衡分布(Equilibrium Distribution):马尔可夫链的稳态分布
K
- 可数状态空间(Countable State Space):状态数量可数的马尔可夫链
- 可达性(Accessibility):从一个状态能够到达另一个状态的性质
M
- 马尔可夫性质(Markov Property):未来状态仅依赖于当前状态的性质
- 马尔可夫链蒙特卡洛(Markov Chain Monte Carlo, MCMC):基于马尔可夫链的采样方法
- 马尔可夫决策过程(Markov Decision Process, MDP):引入动作和奖励的马尔可夫链扩展
P
- 平稳分布(Stationary Distribution):满足π = πP的概率分布
- 平衡方程(Balance Equation):描述稳态分布的方程
Q
- 强大数定律(Strong Law of Large Numbers):马尔可夫链极限行为的基础
- 切普曼-科尔莫戈洛夫方程(Chapman-Kolmogorov Equation):描述多步转移概率的方程
S
- 随机矩阵(Random Matrix):元素为随机变量的矩阵
- 收敛速率(Convergence Rate):马尔可夫链趋近稳态分布的速度
T
- 通信类(Communicating Class):状态之间可以相互到达的集合
- 停时(Stopping Time):马尔可夫链达到某个条件的随机时间
W
- 稳态分布(Stationary Distribution):随着时间推移,系统状态的长期概率分布
- 无记忆性(Memorylessness):系统的未来状态只依赖于当前状态,而与过去历史无关的性质
X
- 谢尔伍德定理(Sherwood’s Theorem):关于马尔可夫链收敛性的定理
- 信息熵(Information Entropy):度量马尔可夫链不确定性的度量
Y
- 遍历性(Ergodicity):马尔可夫链的时间平均等于空间平均的性质
- 遍历定理(Ergodic Theorem):描述马尔可夫链长期行为的基本定理
Z
- 转移核(Transition Kernel):描述连续状态马尔可夫链状态转移的函数
- 转移概率矩阵(Transition Probability Matrix):描述离散状态马尔可夫链状态转移的矩阵
- 周期性(Periodicity):状态可能返回的时间间隔的最大公约数大于1的性质
马尔可夫链是概率论与逻辑学交汇的一个绝佳例子,它不仅提供了分析复杂系统的数学工具,也深刻影响了我们对因果关系、决策理论和推理模式的理解。从逻辑学角度看,马尔可夫链代表了一种将确定性规则与不确定性结果结合的推理框架,这种框架在人工智能、自然语言处理和复杂系统建模中有着广泛应用。理解马尔可夫链的原理,不仅有助于掌握相关的技术应用,也能够深化我们对概率推理本质的理解。



















 5236
5236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











