 树莓派智能语音助手实践
树莓派智能语音助手实践








基于上一篇文章《初步融合snowboy+pyttsx3+espeak+sherpa-ncnn的python代码》,今天把rasa的chatbot功能也融合进去,真正实现智能语音助手的人机对话。
在demo.py中添加新功能之前,我们还是要将原来的代码做些调整。
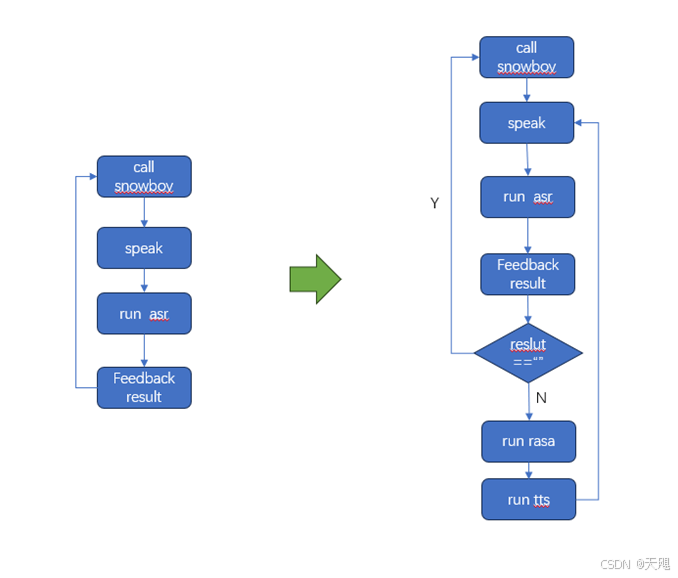
之前流程的不足之处就是无法正常对话,要说一句喊一次snowboy,很不方便。这次则改成喊一次snowboy后,就开始正常对话,直到无声后结束,然后重新再唤醒snowboy,开启下一轮对话。
要实现上述目标,首先我要对asr.py做调整,不能用原来直接基于麦克风识别,而是要改成基于录音识别。具体做法就是增加一个识别录音的函数:
def asr_by_wav():
recognizer = init()
filename=("audio_record.wav")
print("开始识别……")
with wave.open(filename) as f:
assert f.getframerate() == recognizer.sample_rate, (
f.getframerate(),
recognizer.sample_rate,
)
assert f.getnchannels() == 1, f.getnchannels()
assert f.getsampwidth() == 2, f.getsampwidth() # it is in bytes
num_samples = f.getnframes()
samples = f.readframes(num_samples)
samples_int16 = np.frombuffer(samples, dtype=np.int16)
samples_float32 = samples_int16.astype(np.float32)
samples_float32 = samples_float32 / 32768
recognizer.accept_waveform(recognizer.sample_rate, samples_float32)
tail_paddings = np.zeros(
int(recognizer.sample_rate * 0.5), dtype=np.float32
)
recognizer.accept_waveform(recognizer.sample_rate, tail_paddings)
recognizer.input_finished()
result = recognizer.text
return result
第二步,增加一个实现录音的新文件record.py。
import sounddevice as sd
import soundfile as sf
class SPEECH2FILE:
def __init__(self):
self.duration = 5 # 录制时长(秒)
self.sample_rate = 16000 # 采样率
def record_audio(self):
print(f"说些什么...(时长为{self.duration}秒)")
audio = sd.rec(int(self.duration * self.sample_rate), samplerate=self.sample_rate, channels=1)
sd.wait()
return audio
def save_audio_to_file(self, audio, file_path):
sf.write(file_path, audio, self.sample_rate)
def record():
speech2file = SPEECH2FILE()
audio = speech2file.record_audio()
file_path = 'audio_record.wav'
speech2file.save_audio_to_file(audio, file_path)
第三步,增加一个rasabot.py,调用聊天机器人功能。需要补充,为了确保聊天机器人正常启动,需要提前把rasa服务开起来:rasa run --enable-api 。rasabot.py的代码如下:
from urllib import request, parse
import json
headers = {'content-type': 'application/json'}
def ask(text):
try:
data = json.dumps({'sender':'snowboy','message':text})
req = request.Request(url='http://localhost:5005/webhooks/rest/webhook', data=bytes(data, 'utf8'), headers=headers)
response = request.urlopen(req).read().decode('utf-8')
resp = json.loads(response)
return resp[0]['text']
except:
return '这真是个好问题,哈哈哈'
最后,修改demo.py中的callback函数,注意不要在文件头部import record。
def callback():
tts.text_to_speech('我在听……')
status = 1
while status == 1:
record.record()
text=asr.asr_by_wav()
print("识别结果:"+text)
if text == "":
print("对话结束,等待呼唤……")
status = 0
else:
print("等待答复……")
resp = rasabot.ask(text)
print("回复内容:"+resp)
tts.text_to_speech(resp)
time.sleep(0.5)
完成上述修改后,执行python demo.py,得到如下结果:
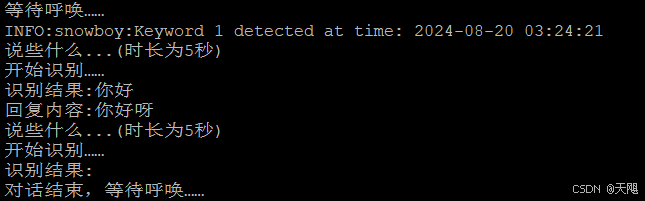
智能语音助手的聊天功能就这么上线了,至于对话内容的深度和广度,还要看以后进一步的模型训练了,哈哈哈……


















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











