







可以理解为一个损失函数
信息瓶颈理论把神经网络理解为一个编码器和一个解码器,编码器将输入x编码成Z,解码器将Z解码成输出y
而信息瓶颈理论的目标则是
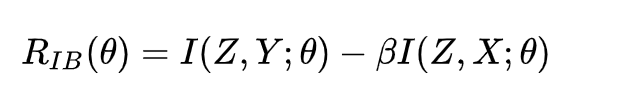
R
I
B
(
θ
)
R_{IB}(\theta)
RIB(θ)就是信息瓶颈,
θ
\theta
θ是网络的参数,也是要优化的东西
I
(
Z
,
Y
;
θ
)
I(Z,Y;\theta)
I(Z,Y;θ)就是输出Y和中间feature Z的互信息
I
(
Z
,
X
;
θ
)
I(Z,X;\theta)
I(Z,X;θ)是输入X和中间feature Z的互信息
互信息参考互信息的定义
在决策树的C4.5算法中又被叫做信息增益
信息瓶颈理论的本质就是:最大化Z和Y的互信息,尽量减少X和Z的互信息
互信息也可以简单理解成互相包含的信息。
按照这种理解,减少X和Z的互信息,同时增大Z和Y的互信息,实际上是希望Z中尽量减少X的与Y不相关的信息,保留X的和Y最相关的那部分信息。
通过公式推导,可以得到
R
I
B
(
θ
)
R_{IB}(\theta)
RIB(θ)的下界L,即
R
I
B
(
θ
)
》
L
R_{IB}(\theta)》L
RIB(θ)》L,最大化IB相当于最大化L,取L的相反数为
J
I
B
J_{IB}
JIB,即最大化IB相当于最小化
J
I
B
J_{IB}
JIB,因此,可以把
J
I
B
J_{IB}
JIB作为模型的损失函数:

上式中, q ( y n ∣ z ) q(y_n|z) q(yn∣z)即为模型的decoder, p ( z ∣ x n ) p(z|x_n) p(z∣xn)即为模型的encoder, ∣ ∣ || ∣∣是和的意思,即求这两者的KL散度
总结:
IB理论把深度学习阶段分为两部分,前一段时间尽量增加中间feature和Y的互信息,后一段时间尽量压缩X和中间feature的互信息,使得中间feature包含X最精华的信息。

















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









