







一.ControlNet是什么
1.ControlNet就是用来控制构图的,LoRA就是用来控制风格的
2.要点:
2.1.ControlNet本质是文生图(txt2img),使用ControlNet请优先使用txt2img这个页签
2.2.尽量要保证预处理器(preprocessor)跟模型(model)是同类的
二.安装插件
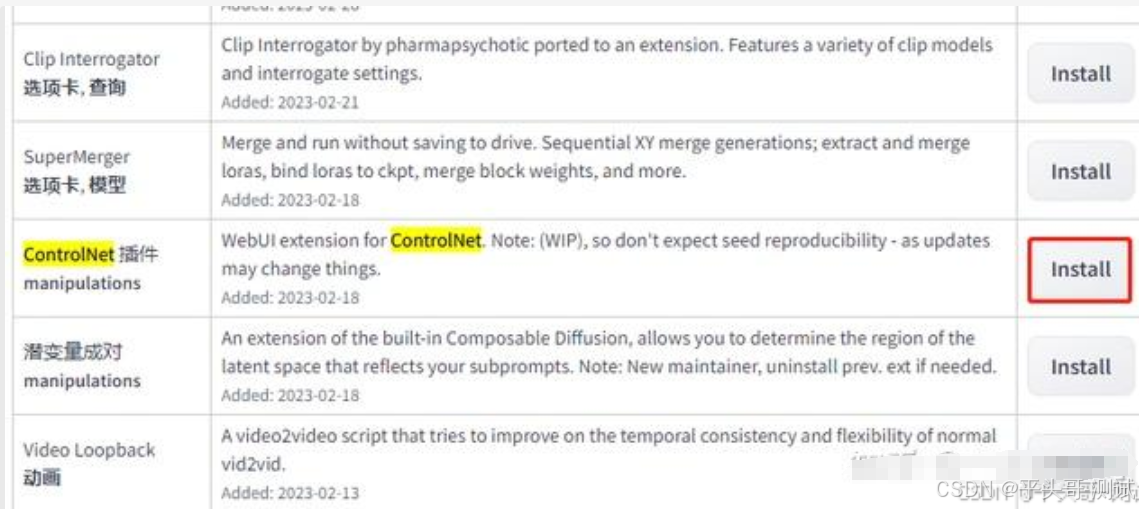
1.ControlNet安装方法一
1.1.stable diffusion工作台,扩展-可用-勾选掉本地化翻译-点击加载,稍等片刻就会加载出可用插件
1.2.这时按下键盘上的Ctrl+F ,调出搜索框,输入“controlnet”,找到controlnet插件点击安装,即可
2.ControlNet安装方法二
2.1.来到stable diffusion工作台,扩展-从网址安装,输入插件安装网址
https://github.com/Mikubill/sd-webui-controlnet.git
2.2.然后点击安装即可
3.ControlNet安装方法三
3.1.来到插件的下载地址,点击右侧的绿色按钮,下载安装包
3.2.然后解压到*\stable-diffusion-webui\extensions\sd-webui-controlnet目录下即可
三.安装模型
1.模型地址:https://github.com/Mikubill/sd-webui-controlnet/wiki/Model-download
2.模型地址二:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
3.模型地址三:https://huggingface.co/lllyasviel/sd_control_collection/tree/main
4.下载完后的模型放到下面的路径下方:*\stable-diffusion-webui\extensions\sd-webui-controlnet\models
5.下面以canny模型为例,需要把下图红框内的两个文件都下载下来,点击右方的下载按钮
5.1.更多其它插件可以看:stable diffusion常用插件安装【插件篇】
https://zhuanlan.zhihu.com/p/691390997
三.界面介绍
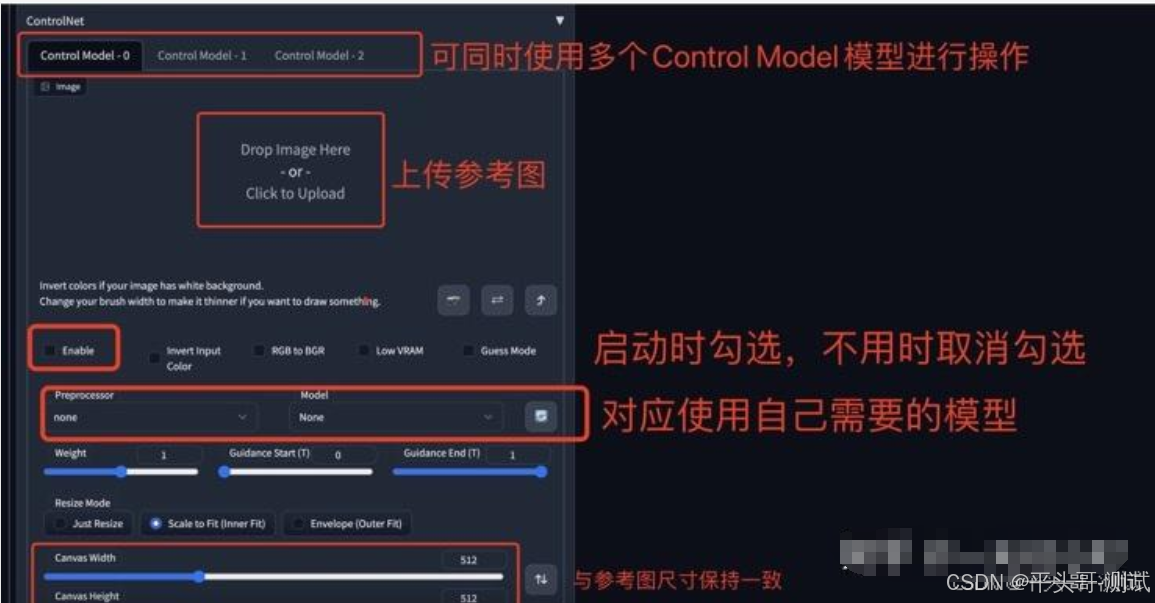
1.通过线稿、动作识别、深度信息等对原有的图像进行控制
1.1.用户可以手动编辑源图像,控制其某些属性
1.2.改变图像的画风、动作、颜料等,生成新的图像
2.启用『完美像素』让『ControlNet』自适应匹配设置的输出图像的宽度,高度根据输入原图像自动计算
2.1.开启后会隐藏 Resolution 滑动条(分辨率)
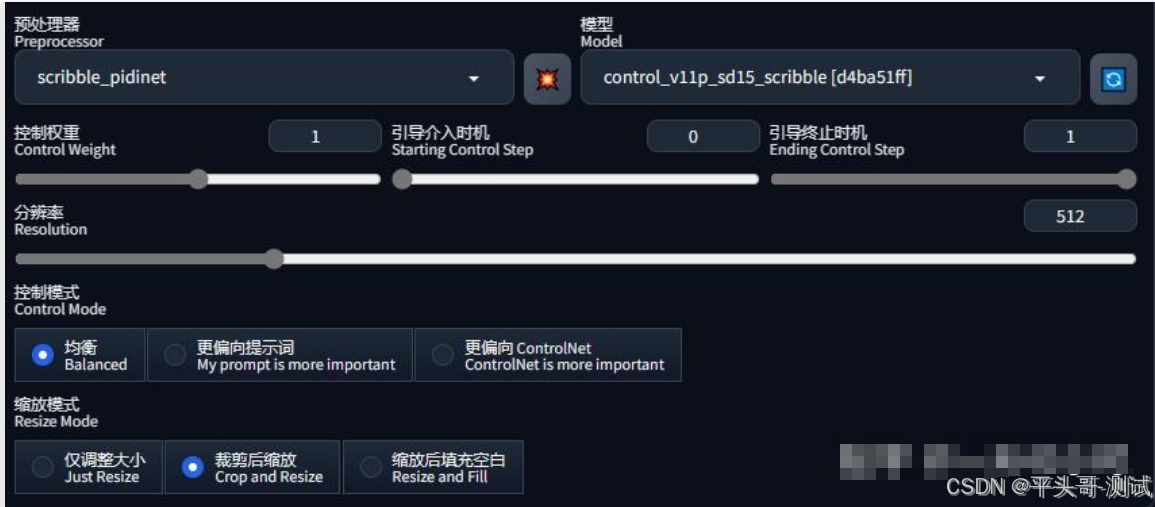
3.Control Weight控制权重:使用ControlNet生成图片的权重占比影响
3.1.(多个 ControlNet组合使用时,需要调整权重占比)
4.Starting Control Step:ControlNet开始参与生图的步数。
4.1.设为0.2表示图像生成 20%时开始介入
5.Ending Control Step:ControlNet结束参与生图的步数
5.1.设为0.8表示图像生成80%时停止影响
6.Resolution分辨率:预处理器分辨率默认512,数值越高线条越精细,数值越低线条越粗糙
6.1.当启用“完美像素模式”后,系统会自动设置预处理分辨率,通常为最低可用分辨率
6.2.如果需要更高精度的结果(如高清线稿图),则需要手动设置分辨率
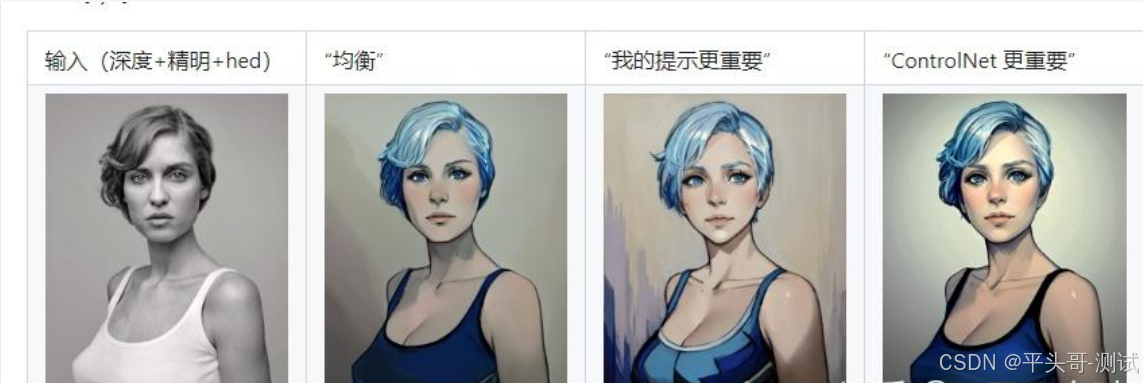
7.控制模式:提供均衡、更偏向提示词、更偏向『ControlNet』三种选项,字面意思即可理解
7.1.一般就用默认的均衡
四.线稿类(5个)
1.用各种预处理器给处理成线稿
1.1.当然也可以支持用别的软件自己画出来的线稿,在这种场景下预处理那里选择none就可以
1.2.然后基于这个线稿再去让AI对他进行美化
1)Canny边缘检测 :边缘检测,提取线稿(常用于复刻图片)
2)MLSD直线检测:直线检测(适用于建筑、室内设计)
3)lineart:提取精细线稿
4)SoftEdge:软边缘检测,保留更多边缘细节
5)Scribble涂鸦:自己随便涂几笔,剩下交给AI去发挥,效果真的蛮惊艳

2.Canny边缘检测
2.1.Canny是比较常用的一种线稿提取方式,该模型能够很好的识别出图像内各对象的边缘轮廓
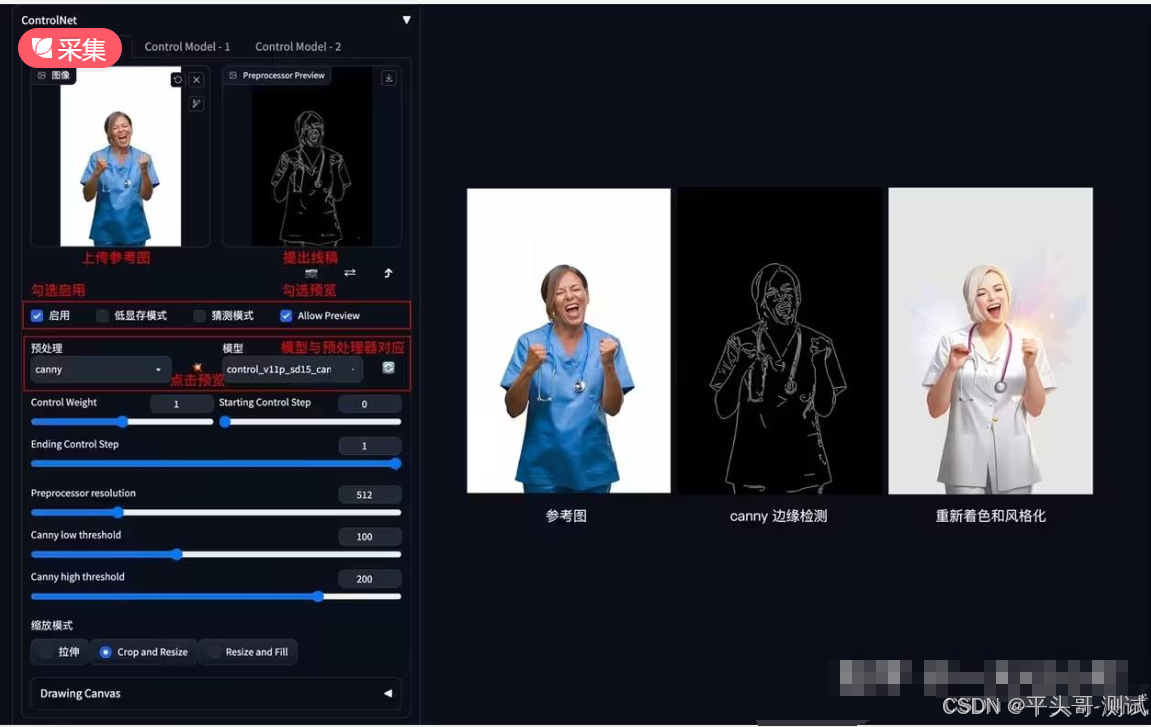
2.2.有时候线条过于复杂,这时候就需要通过改变阈值来实现。以隐藏一些不必要的线条

2.3.低阈值/高阈值:数值越低线条越复杂,数值越高线条越简单
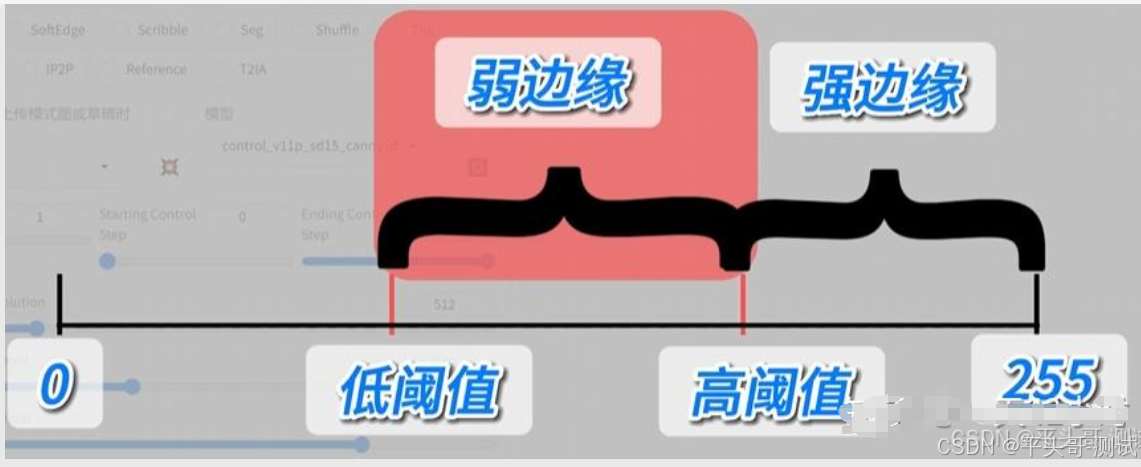
2.3.1.0-低阈值为隐藏部分;保留强边缘;保留部分弱边缘
2.4.Canny Low Threshold低阈值:去掉过细的线段。大于低阈值的线段被认定为边缘
2.5.Canny High Threshold高阈值:去掉零散的线段
2.5.1.大于高阈值的线段被认定为强边缘,全部保留
2.5.2.高阈值和低阈值之间的线段认定为弱边缘,只保留强边缘相邻的弱边缘
2.6.如果低阀值>高阀值时,高低阀值就会互换
2.7.总结
2.7.1.使用canny模型可以对原图细节进行很优秀的检测,让新生成的可以获得更多细节还原
2.7.2.若想要更多的复刻图片的话,这里建议使用canny模型

3.MLSD直线检测
3.1.通过ControlNet的MLSD模型提取建筑的线条结构和几何形状,构建出建筑线框
3.1.1.可提取参考图线条,或者手绘线条
3.1.2.再配合提示词和建筑/室内设计风格模型来生成图像
3.2.应用模型:MLSD
3.2.1.功能:忽略图像中的曲线,只提取曲线,适用于建筑这些直线元素较多的图像扩散
3.3.建筑/室内设计风格模型下载
https://civitai.com/?query=Interior
https://civitai.com/?query=building
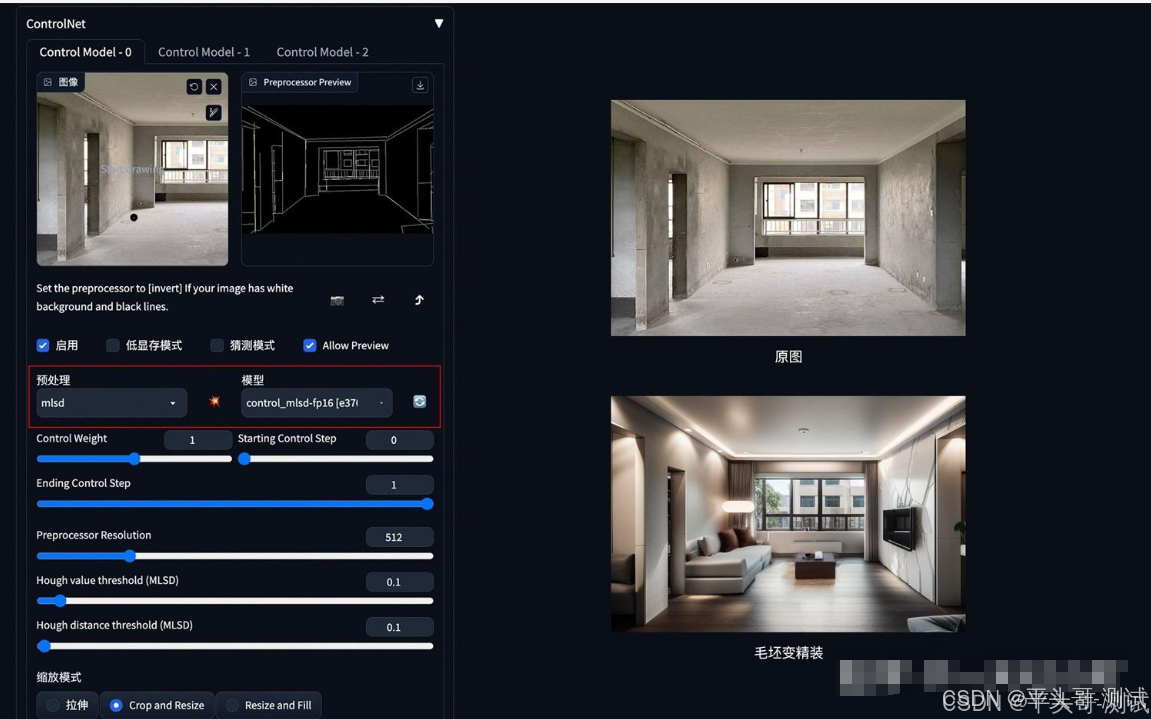
3.3.1.毛坯变精装

3.4.专有参数
MLSD Value Threshold:直线阈值。值越低,检测的直线越多。范围 0.01~2
MLSD Distance Threshold:距离阈值。对检测的之间进行距离筛选。取值范围 0.01~20
4.lineart线稿
4.1.Lineart 精细线稿提取是 ControlNet1.1 版本中新增的模型
4.2.Lineart的线条有粗细深浅的区别,相比Canny,除能够控制构图,还可以更好的还原图片深度
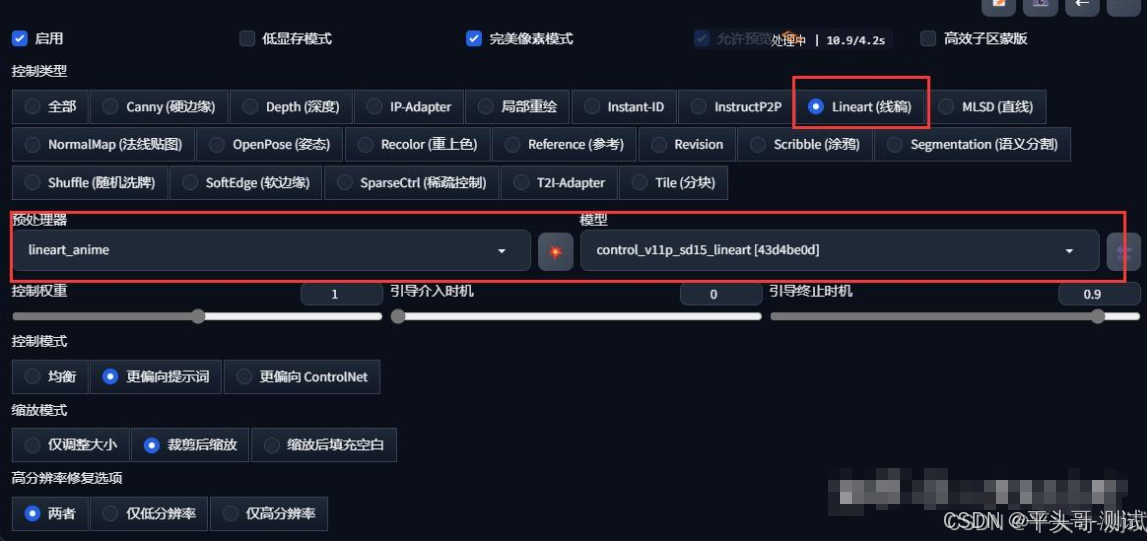
4.3.【预处理器】里面的各种模型可以识别不同图片的线稿
4.3.1.none(无): 不使用预处理器,需要直接上传一张处理好白线黑景线稿图
4.3.2.lineart_standard(标准线稿提取-白底黑线反色):从图片提取线稿图的标准版处理器
4.3.3.invert(对白色背景黑色线条图像反相处理):反色图片,适合从白色背景、黑色线条的图片中提取线稿图
4.3.4.lineart_realistic(写实线稿提取):从真实视觉的图片中提取线稿图
4.3.5.lineart_coarse (粗略线稿提取):从图片中粗略提取线稿图,忽略不突出的细节,生图时自由度更高
4.3.6.lineart_anime_denoise(动漫线稿提取-去噪):适合从动漫图片中提取线稿图,并去掉噪点
4.3.7.lineart_anime(动漫线稿提取):适合从动漫图片中提取线稿图
4.4.【模型】
4.4.1.control_v11p_sd15_lineart:通用线稿图生成模型
4.4.2.control_v11p_sd15s2_lineart_anime:二次元线稿图生成模型


4.5.实际使用:它的应用场景主要有
4.5.1.提取动漫的线稿,再重新上色
4.5.2.给素描图片上色
4.5.3.上传自己的照片,提取出线稿,然后生成自己的二次元头像
4.5.4.给黑白线稿上色
4.5.5.如果是动漫图片呢,预处理器模型则选择anime或anime_denoise
4.5.5.1.相对来说,anime_denoise比anime细节更多一点
4.5.6.如果是素描图片,则建议使用coarse,它从图片中粗略提取线稿图
4.5.6.1.忽略不突出的细节,生图时自由度更高
4.5.7.写实图片呢,建议选择realistic
4.5.8.黑白线稿呢,则可以选择standard
4.5.9.颜色反转、反色图片,则适合从白色背景、黑色线条的图片中提取线稿图
4.5.10.不使用预处理器,需要直接上传一张处理好白线黑景线稿图
5.SoftEdge软边缘检测
5.1.使用软边缘图像生成训练,平滑的边缘、更好的深度,忽略内部细节
5.1.1.方便创作更具绘画特征或艺术风格的图片
5.2.相比Canny、Lineart,SoftEdge除稳定构图,更好的图片深度控制
5.2.1.还拥有更多的自由度
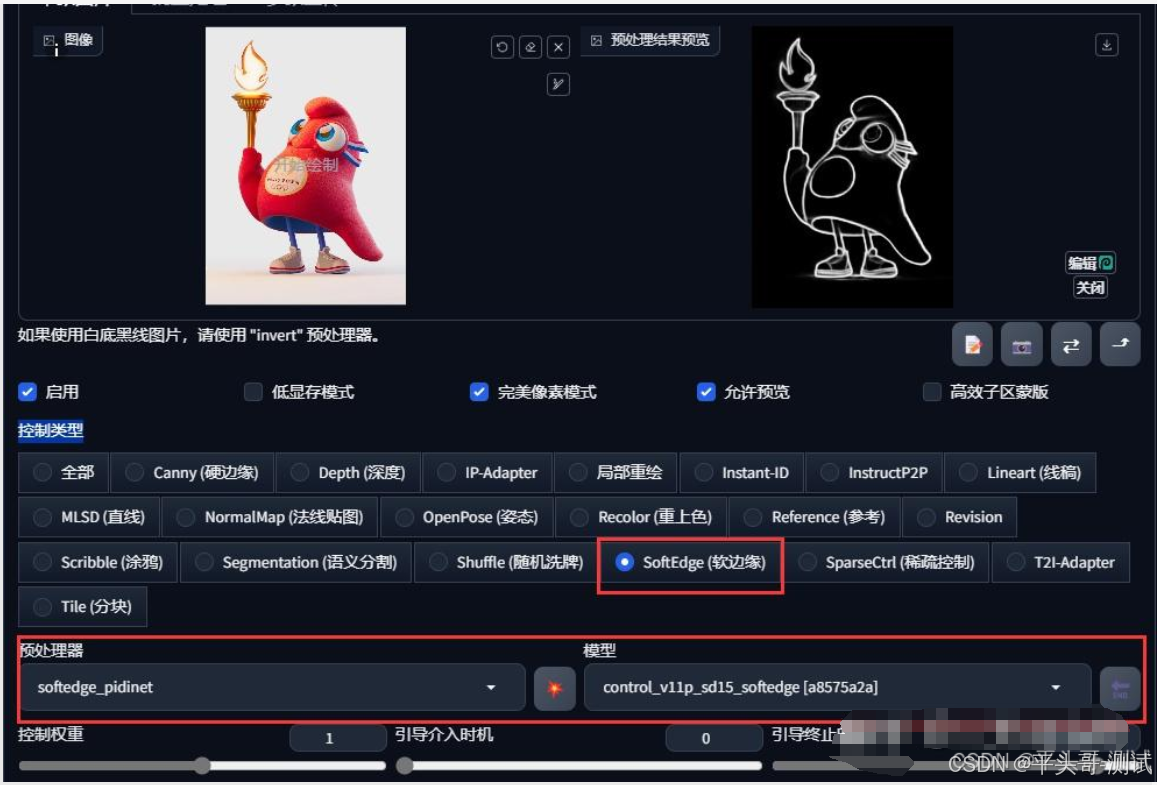
5.3.【预处理器】中有4个不同的预处理器,按结果质量排序:
SoftEdge_HED>SoftEdge_PIDI>SoftEdge_HED_safe>SoftEdge_PIDI_safe
5.4.其中带safe的预处理器可以防止生成的图像带有不良内容
5.4.1.SoftEdge_PiDiNet(软边缘检测-PiDi算法)
优:保留原图中更多的细节,图片完整性更好
缺:对于轮廓内外的区别准确度稍差,所以在刻画内部线条时会出现一些不合理的情况(例如人物五官不清晰)
5.4.2.softedge_teed(软边缘检测-高效边缘检测)
5.4.3.SoftEdge_PiDiNetSafe(软边缘检测-保守PiDiNet算法) :在PiDiNet版本基础上降低细节
5.4.4.SoftEdge HEDSafe(软边缘检测-保守HED算法):在HED版本基础上降低细节
5.4.5.softedge_hed(软边缘检测-HED)
优:能够较为合理的保留图片中的主体,会忽略掉一些不必要的细节
缺:相对于HED来说保留的细节较少
5.4.6.softedge_anyline(软边缘检测-全部线条)
5.5.个人喜欢用PiDiNet,更稳定一些

6.Scribble涂鸦
6.1.Scribble/Sketch算法能够提取图片中曝光对比度比较明显的区域,生成黑白稿,涂鸦成图
6.1.1.其比Canny算法的自由度更高,也可以用于对手绘线稿进行着色处理
6.2.可以看到提取的涂鸦,不但保留了曝光度对比较大的部分
6.2.1.而且细节保留的也很不错
6.2.2.细节保留的越多,那么SD重新生成图片时所能更改的部分就越少
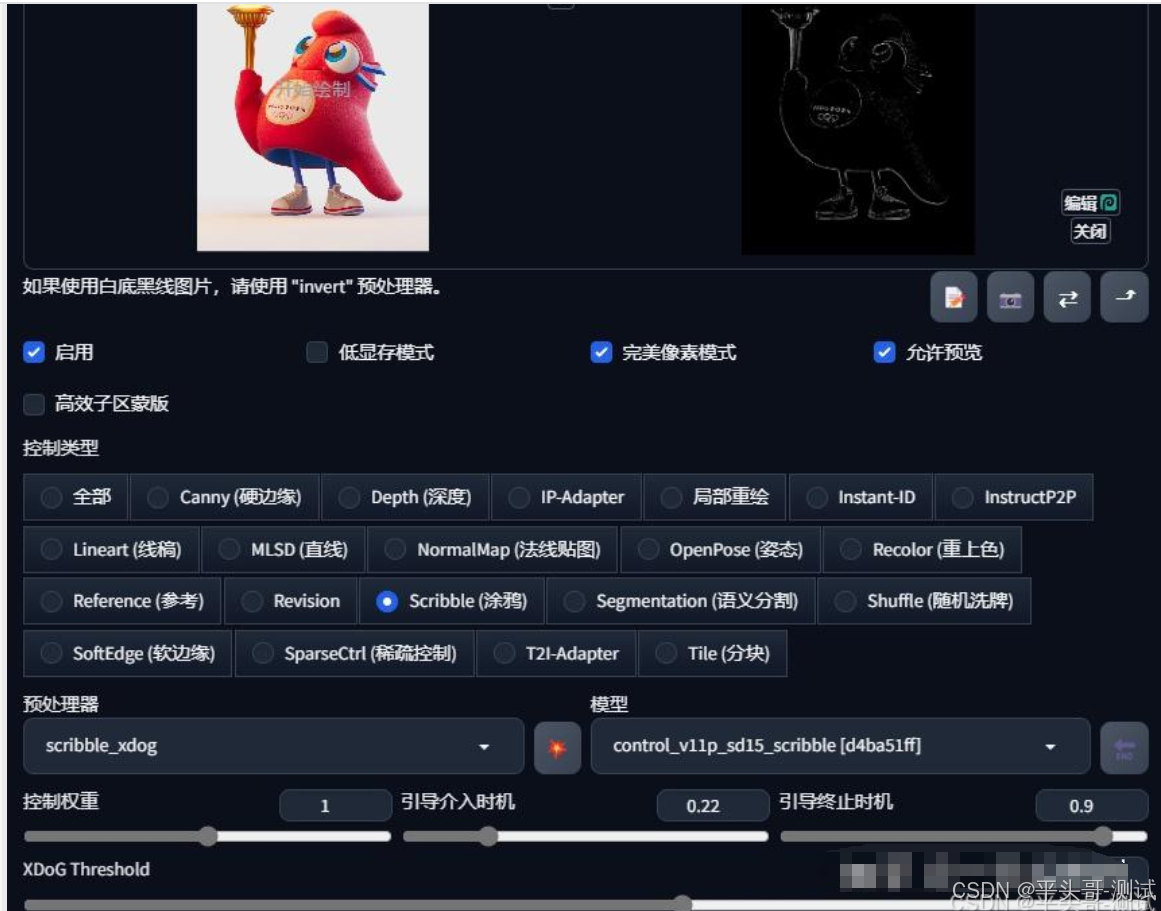
6.3.预处理器解析
6.3.1.无:不对参考图进行预处理,需要自己上传处理好的涂鸦图,白色代表线条
6.3.2.scribble hed(涂鸦-整体嵌套):粗线合成涂鸦图,用来生成随机性较强的图(线条较粗)
6.3.3.scribble_pidinet(涂鸦-像素差分):粗线简笔合成涂鸦图,生成图片的自由度比 scribble_hed 弱(推荐)
6.3.4.scribble_xdog(涂鸦-强化边缘):从图片中提取更多的细节生成涂鸦图,结构和轮廓的限制更多
6.6.4.1.(有阀值参数可以控制精细程度,数值越小精度越高)
6.3.5.invert(对白色背最黑色线条图像反相处理):简单的反转图片中的黑白色,适合黑白图的处理
6.4.预处理器
6.4.1.Scribble也可以用来处理真实的图片
6.4.2.与Canny、Lineart、SoftEdge相比,最大的变化就是,构图会发生一些变化
6.4.3.而且它没有对图片深度的处理,但它能接受粗糙的手绘

五.总结(线稿类)

1.canny是基于精细的边缘检测,准确还原图片的结构和特征
1.1.提取的边缘图中的线条是没有粗细、深浅之分的
1.2.如果是生成棱角分明或者机甲一类的图像,我们推荐使用Canny算法
2.而Lineart的线条有粗细深浅的区别,相比Canny,除了能够控制构图
2.1.还可以更好的还原图片深度
3.同样相比Canny、Lineart呢,SoftEdge除了稳定构图,更好的图片深度控制
3.1.还拥有更多的自由度
4.Canny更注重于细节,Softedge更偏向框架,而lineart呢,则介于两者之间
4.1.可以把Canny算法理解为用铅笔提取边缘,而softedge_hed预处理器则是换用毛笔
4.2.被提取的图像边缘将会非常柔和,细节也会更加丰富,绘制的人物明暗对比明显
4.3.轮廓感更强,适合在保持原来构图的基础上重新着色和对画面风格进行改变
5.总之
5.1.想最大程度还原照片:canny
5.2.只想控制构图,给SD更多可以变化的地方:softedge
5.3.真人、素描等照片:lineart
5.4.建筑物装修:mlsd
6.效果对比
6.1.考虑到Scribble对原图的变化过大,这里只对比前三个
6.1.1.可以看到SoftEdge对构图和深度处理的最好,当然细节上也更自由

六.结构类(3个)
1.depth深度检测:景深图。根据深度和轮廓,然后模型去出图
2.seg:图像的语义分割图,不同颜色对应不同的对象类型
2.1.譬如粉色是建筑物、绿色是植物等等,可以通过PS改变颜色从而指定生成某种对象
3.normalbae:法线贴图,提取法线信息
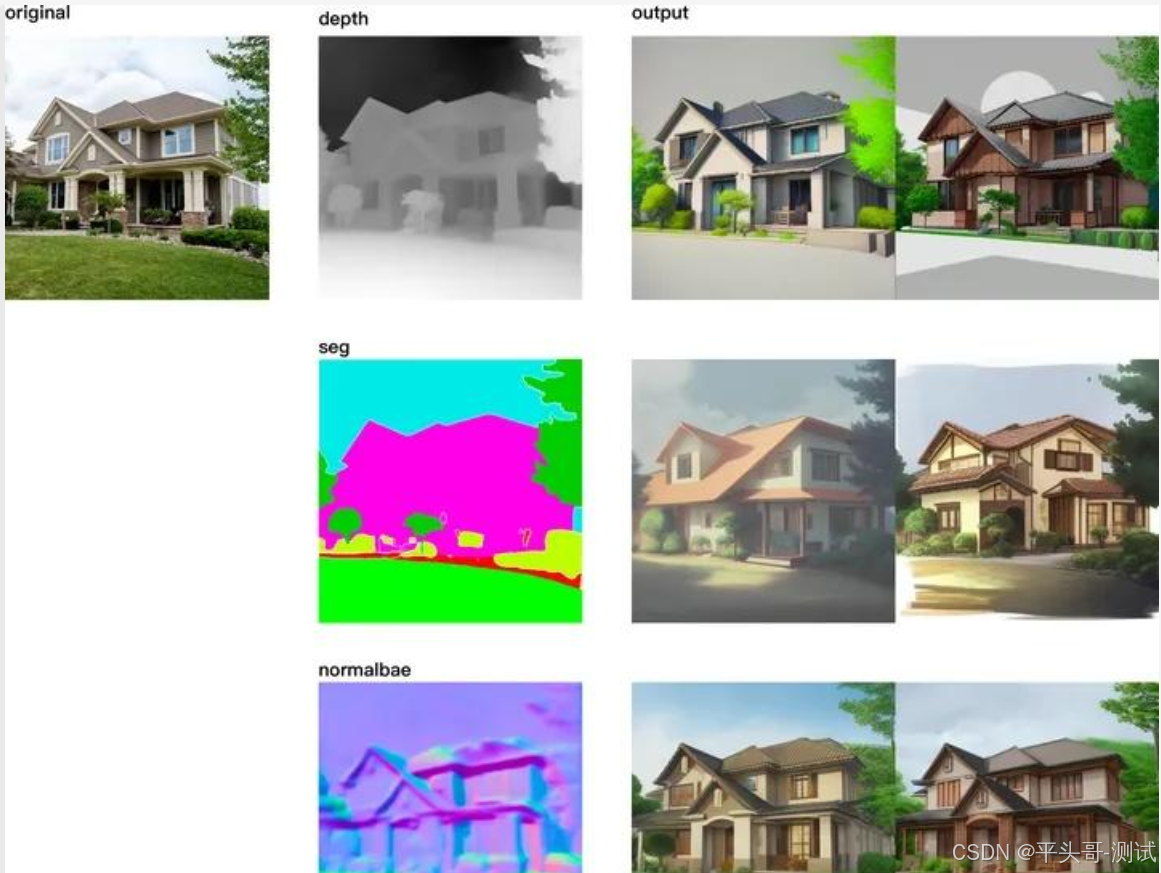
4.depth深度检测
4.1.深度图(Depth Map)是描述场景中各个像素距离相机远近的信息
4.2.深度图通常是灰度图像,其中亮度值表示深度值(白色表示近处,黑色表示远处)


4.3.预处理器类型
4.3.1.无
4.3.2.depth_midas(MiDas深度图估算)
4.3.2.1.MiDaS深度信息估算是一种常用的预处理器
4.3.2.2.它能够通过控制空间距离来更好地表达较大纵深的风景的远近关系
4.3.2.3.此外,Depth模式还可以生成遮罩蒙版
4.3.2.4.帮助用户更好地控制图像中不同元素的显示效果
4.3.3.depth_zoe(ZoE深度图估算)
4.3.3.1.Zoe深度信息计算可以作为一个预处理器或者一个模块来使用
4.3.3.2.它可以帮助用户更好地理解图像中的深度信息
4.3.3.3.从而更好地控制和处理图像生成、分割、增强等任务
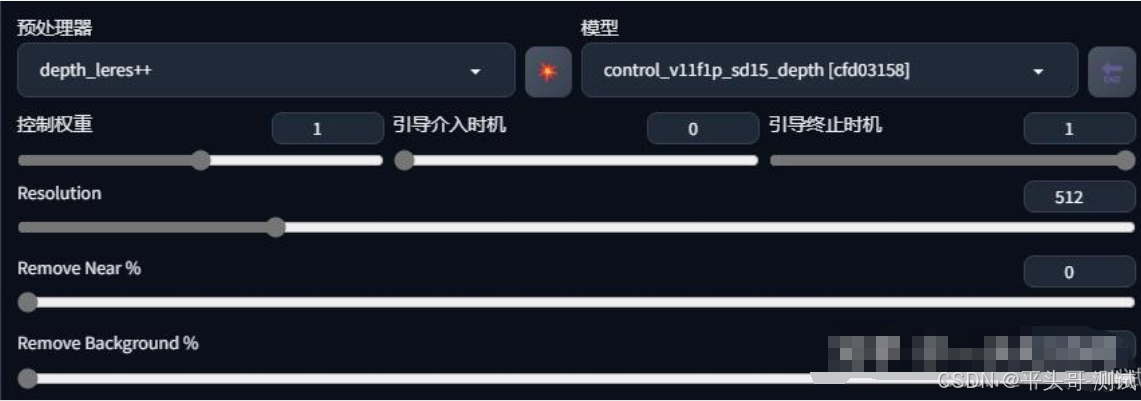
4.3.4.depth _leres(LeRes深度图估算)
4.3.4.1.depth_leres预处理器的成像焦点在中间景深层,这样的好处是能有更远的景深
4.3.4.2.且中距离物品边缘成像会更清晰,但近景图像的边缘会比较模糊
4.3.5.depth _leres++(LeRes深度图估算++)
4.3.5.1.depth_leres++预处理器在depth_leres预处理器的基础上做了优化,能够有更多的细节
4.3.6.因此,当需要突出中景细节或者对整体深度感有更高要求时,可以选择使用LeReS方法
4.3.7.然而,LeReS方法在处理近景图像时可能会产生一些模糊,特别是近景物品的边缘部分
4.3.8.如果近景细节是关键或者画面中有大量的近景内容时,可能需要考虑使用MiDaS方法
4.3.9.depth hand refiner(深度手部细化)
depth_anything_v2
depth_anything
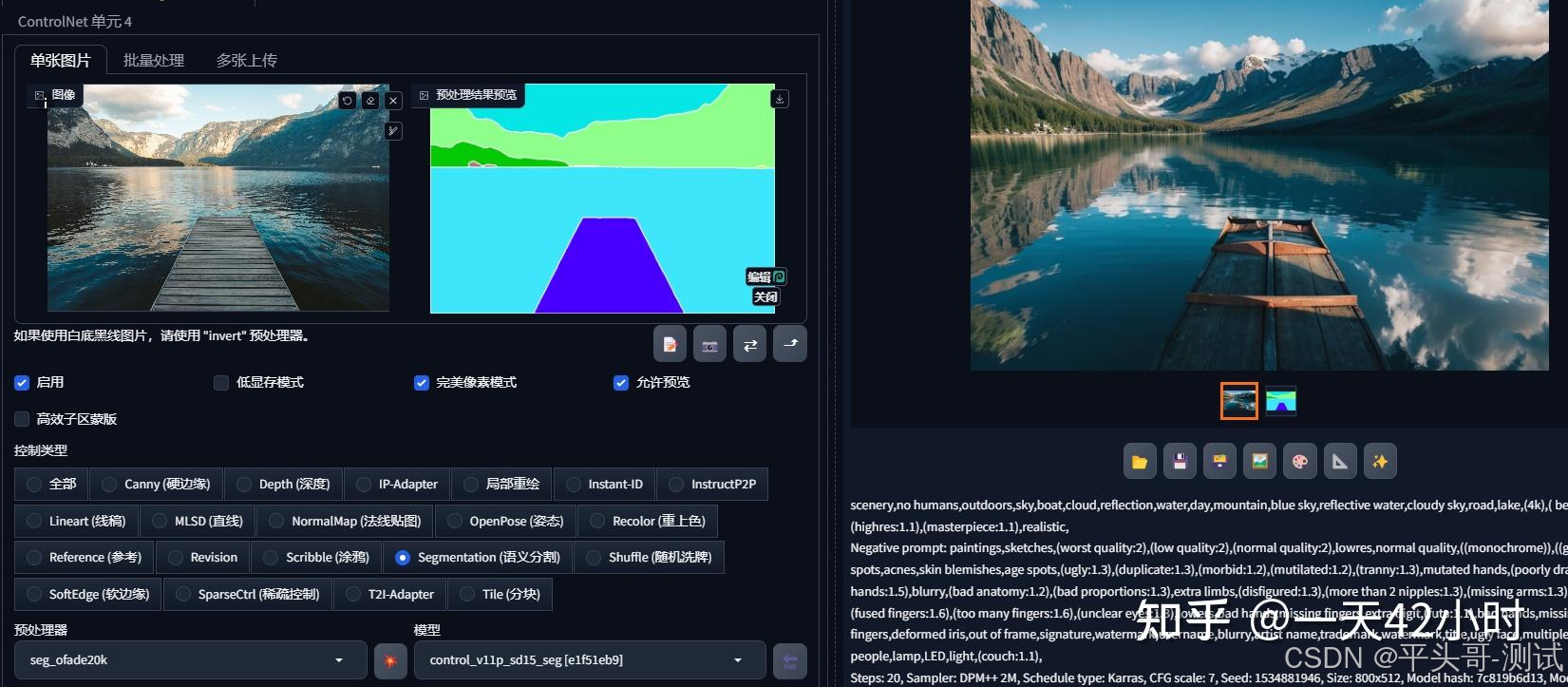
5.seg语义分割图
5.1.Segmentation语义分割,通过对图片内容进行语义分割
5.1.1.可以区分画面色块,标注画面中的不同区块颜色和结构
5.1.2.不同颜色代表不同类型对象,从而控制画面的构图和内容
5.1.3.适用于大场景的画风更改
5.2.Seg相关的预处理器有3种,分别为:seg_ofade20k、seg_ofcoco和seg_ufade20k
5.3.这3类预处理器最终处理的结果差异不大
5.3.1.在预处理器的选择上不用过多纠结,一般使用“seg_ofade20k”节即可

5.4.ofade20k准确度三个模型中最高,coco完整性最好,会忽略一些细节
5.5.下面表格中的颜色都对应着相关物体:
Seg语义参考:https://docs.qq.com/sheet/DYmtk
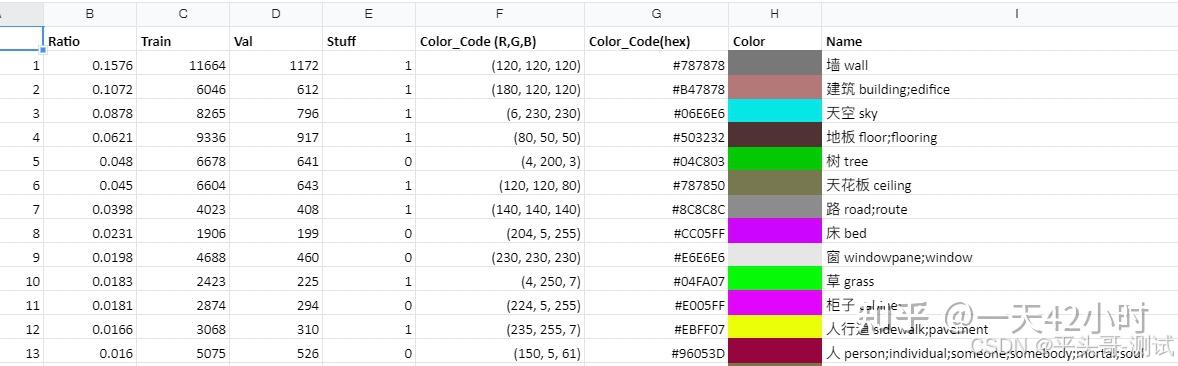
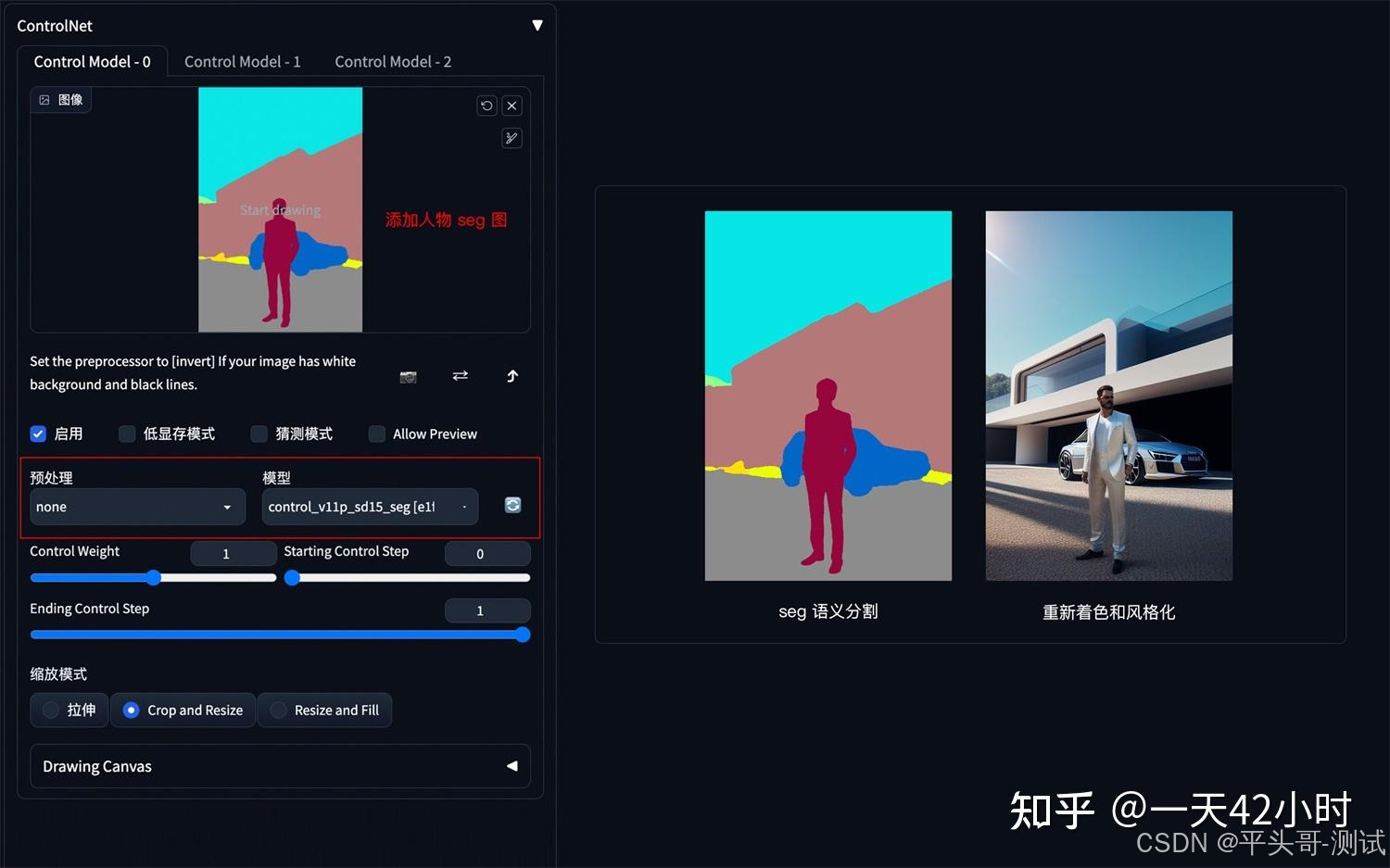
5.5.1.不同颜色代表不同类型对象
5.5.2.提取参考图内容和结构,再进行着色和风格化

5.5.3.如果还想在车前面加一个人,只需在Seg预处理图上对应人物色值
5.5.3.1.添加人物色块再生成图像即可
5.5.4.将不同对象分割成不同颜色(可以通过PS改变颜色,从而达到改变对象)
5.5.5.所以对于seg(语义分割)来将,我个人认识更适用于捕捉大的区域结构
5.5.6.可以让AI发挥出更多的想象空间,新生成的图像变化也将更大
5.6.Seg模型的优势在于我们可以获取到原图中元素信息以及位置且无过多细节
5.6.1.后续新生成图片时,可以很好的基于分割的模块进行图片生成
5.6.2.也不会有过多的原图元素干扰
5.7.适用于大场景的画风更改
5.8.与插件Inpaint anything扩展(分割)的区别:Inpaint anything是分割成不同颜色块
5.8.1.再将选择的颜色块生成为蒙板,更合适于局部修改
5.9.基于分割的模块进行图片生成
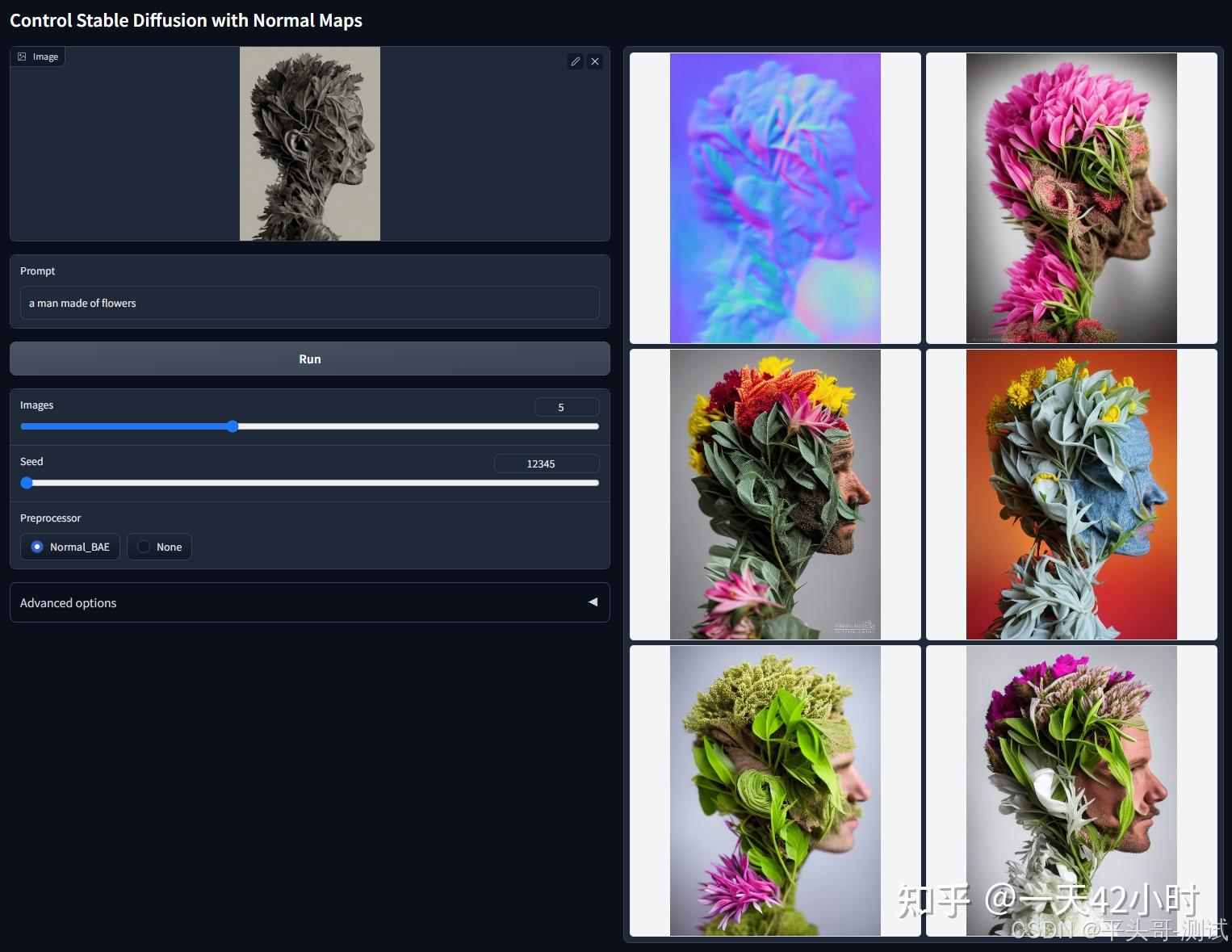
6.normal法线贴图
6.1.法线贴图是一种凹凸贴图,会生成特殊的纹理,把表面细节通过光线表现出来
6.2.推荐使用默认这个预处理器:Normal_bae
6.2.1.Normal_bae需要搭配模型control_v11p_normalbae一起使用
6.2.2.normal_midas可以很好的还原原图的光影(老版,不推荐)
6.2.3.normal_bae可以保留更多光影信息,让图片看着更有细节(推荐使用)
normal_dsine

6.2.4.normal_bae保留细节更多
6.2.4.1.发现:法线图对近景的细节保留还是很丰富的,但是远景就保留得很少
6.4.2.2.所以法线图更加适合于只想保留近景图像特征的情况,例如:三维模型
七.风格迁移类(5个)
1.Shuffle(洗牌):通过打散参考图的颜色来获取信息,从而进行扩散生成图像(SD1.5)
2.Instant-ID(即时ID)
3.IP-Adapter
4.Reference(参考):可以理解为固定参考图的部分特征,并在此基础上进行扩散
5.Revision(修订):将图片转化为提示词,类似于提示词反推
6.shuffle洗牌
6.1.Shuffle算法通过打散参考图的配色来获取信息,并控制SD模型生成相似配色方案的图像
6.1.1.简单来说就是让AI学习原图的风格,然后赋予到新的图片上
6.1.2.Shuffle是ControlNet最早期用于风格迁移的预处理器
6.1.3.仅针对SD1.5使用,通过模型名称中的“e”可以知道,它是一个实验性的预处理器
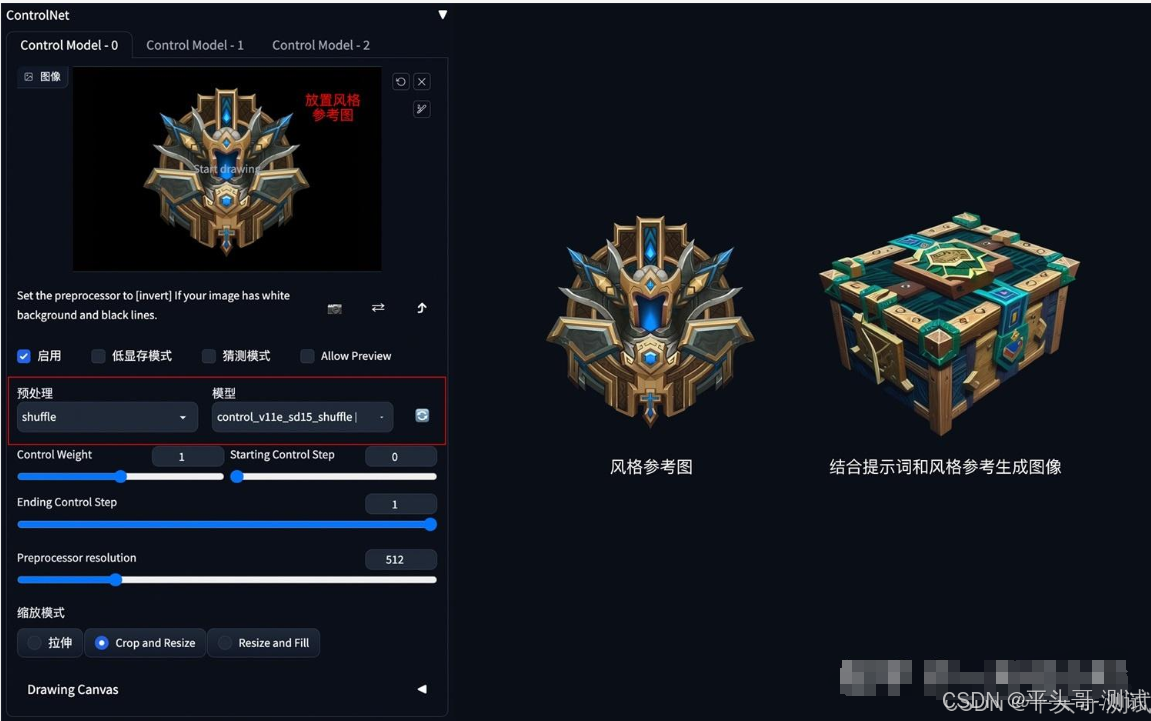
6.2.目前Shuffle算法有一个预处理器:shuffle预处理器
6.2.1.左上角的图像是“打乱顺序”后的图像。其他图像均为输出图像
6.2.2.参考图像的画风一定程度上融合进了生成图像中
6.2.3.生成的图像稳定性差,不易控制
6.2.4.随着越来越多的风格迁移预处理器的出现,Shuffle基本可以弃用了
6.2.5.不过如果在批量生图时没有灵感,可以加上Shuffle试试
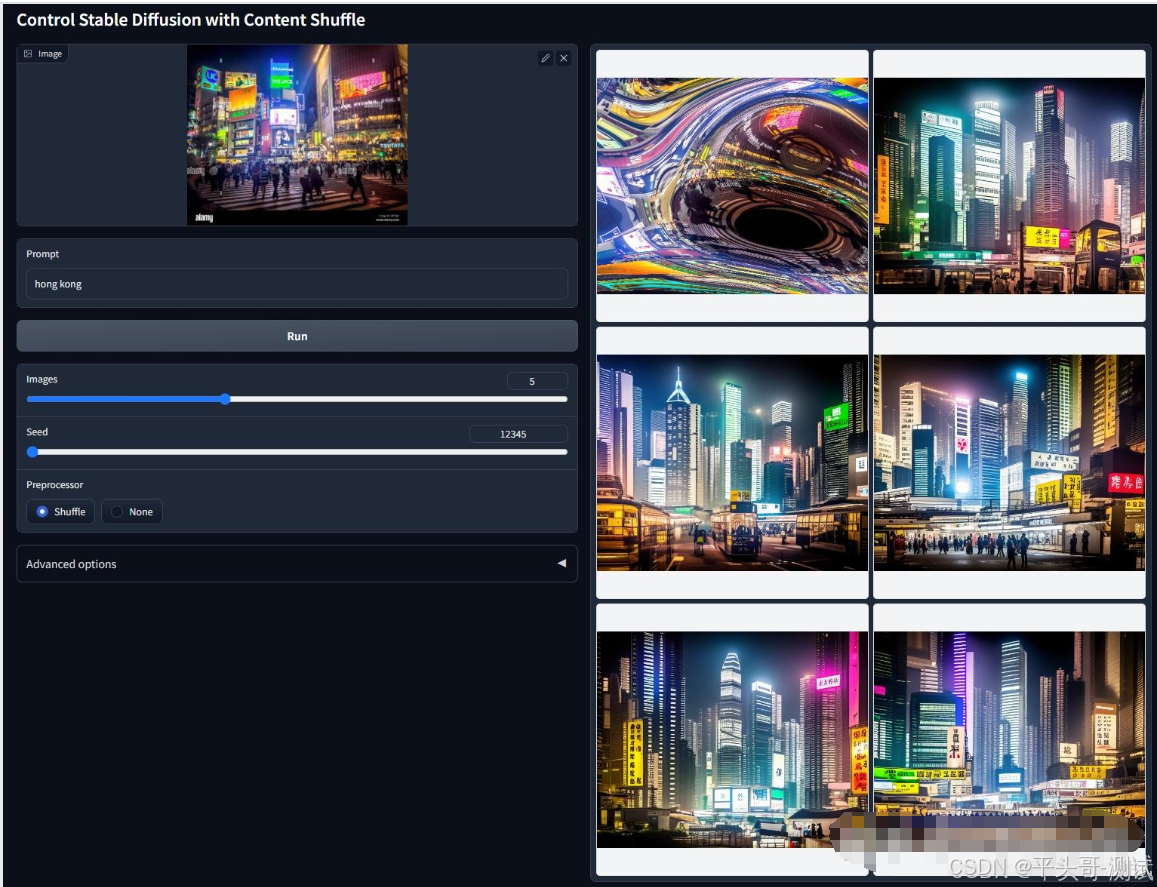
7.Instant-ID即时ID
7.1.Instant-ID主要针对面部特征进行迁移的预处理器,有点类似IP-Adapter中的FaceID和PulID
7.2.安装
7.2.1 模型下载地址:https://github.com/Mikubill/sd-webui-controlnet/discussions/2589
7.2.2.进入上面的网址,找到
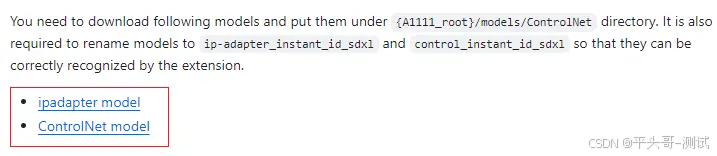
7.2.3.改名的时候不要把后缀名也复制进去
7.3.第一个链接,下载后的名字叫ip-adapter.bin,
需要改名为ip-adapter_instant_id_sdxl.bin
7.4.第二个下载后,原名是diffusion_pytorch_model.safetensors,
改名为control_instant_id_sdxl.safetensors
7.5.将上面下载下来的2个文件都放在SD\extensions\sd-webui-controlnet\models文件夹目录下
7.6.改名非常重要,名称不对,后面模型上可能识别不上
7.7.点下爆炸按钮,看下预处理效果,就会开始下载模型了:如果失败,可以从下面链接下载
https://huggingface.co/DIAMONIK7777/antelopev2/tree/main
7.8.这里会在extensions\sd-webui-controlnet\annotator\downloads\insightface\models\antelopev2下载五个模型
7.8.1.下载完放入以上文件夹
7.9.使用InstantID模型时需要注意一些事项:
7.9.1.大模型只能使用SDXL大模型(选择Instant-ID后模型里还显示无,可能就是模型不是SDXL模型)
7.9.2.提示词引导系数(CFG Scale)要比通常设置的参数值低3-5(太大会出现涂抹感很重)
7.9.3.需要使用2个ControlNet作为InstantID(一个预处理对应一个模型)
7.9.4.减少两个ControlNet的控制权重(Control Weights)和引导终止时机(Ending Control Steps)
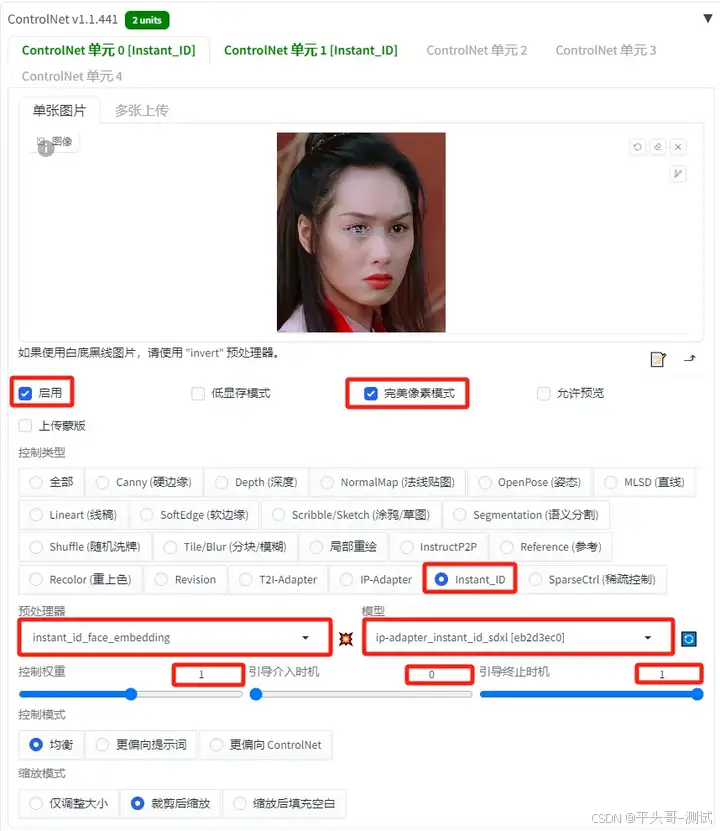
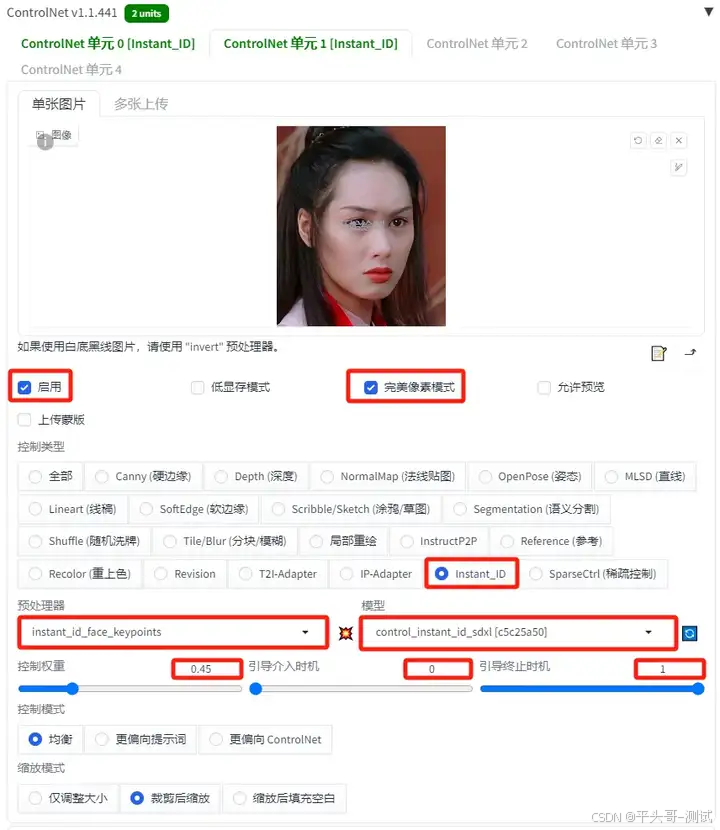
7.10.ControlNet插件InstantID模型设置
7.10.1.要使用它,需要开两个ControlNet
7.10.2.注意,必须按下面的顺序开,先放Embedding再放keypoints这个,是有顺序的
7.10.3.ControlNet单元0设置第一个ControlNet主要使用InsightFace来提取人物的面部特征
预处理器:instant_id_face_embedding
模型:ip-adapter_instant_id_sdxl
7.11.ControlNet单元1设置
7.11.1.第二个ControlNet用于提取面部关键点,例如眼睛、鼻子和嘴巴的位置
7.11.2.可以使用不同的图像,但建议使用相同的图像
7.11.3.这里使用第一个ControlNet上传的图片
预处理器:instant_id_face_keypoints
模型:control_instant_id_sdxl
8.IP-Adapter
9.T21-Adapter
10.Reference参考
11.Revisio修订
12.下方是Instant-ID和IP-Adapter各类面部迁移预处理器的对比
12.1.感觉从面部特征来看,Instant-ID要优于IP-Adapter
12.2.在Instant-ID中,除了有熟悉的控制模式外,它还提供权重类型的选项

八.重绘控制类(5个)
1.OpenPose:姿势检测,提取人物姿势
2.inpaint:局部修图
3.InstryctP2P:指令式修图,动动嘴皮子就可以魔法改图片(不过目前指令识别还有点局限性)
4.tile:超清修复 ,不是一般的上采样高清,而是会增加原图没有的细节
5.OpenPose姿势检测
5.1.OpenPose算法通过姿势识别,能够提取人体姿态
5.1.1.如人脸、手、腿和身体等位置关键点信息,从而达到精准控制人体动作
5.1.2.除生成单人的姿势,它还可以生成多人的姿势
5.1.3.此外还有手部骨骼模型,解决手部绘图不精准问题
5.2.Openpose模型精准识别出人物姿态,再配合提示词和风格模型生成同样姿态的图片
5.3.共六种预处理器
OpenPose
OpenPose_face
OpenPose_faceonly
OpenPose_full
openpose_hand
dw_openpose_full
5.3.1.目前算法中最强的预处理器,是OpenPose_full的增强版,精细程度加强
5.3.2.生成与原图人物姿势一样,但是风格不一样的图片,做人物类的图片常用到
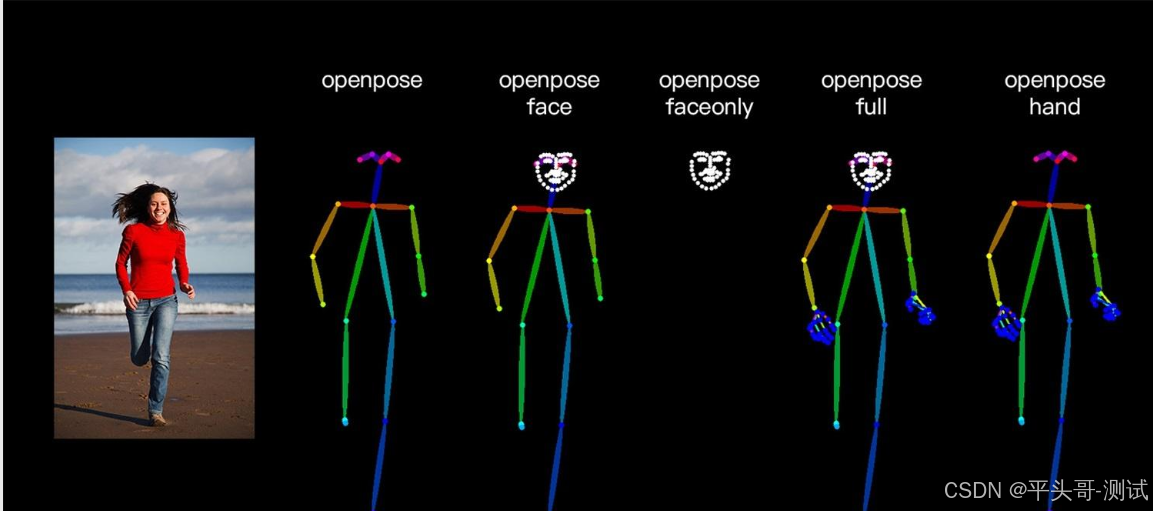
5.3.3.Dw_OpenPose_Full预处理器可以自动检测图像中的人物
5.3.3.1.并将人物的关键点检测结果保存在一个json文件中
5.3.3.2.这个json文件包含了每个关键点的坐标信息,可以用于进一步的分析和处理
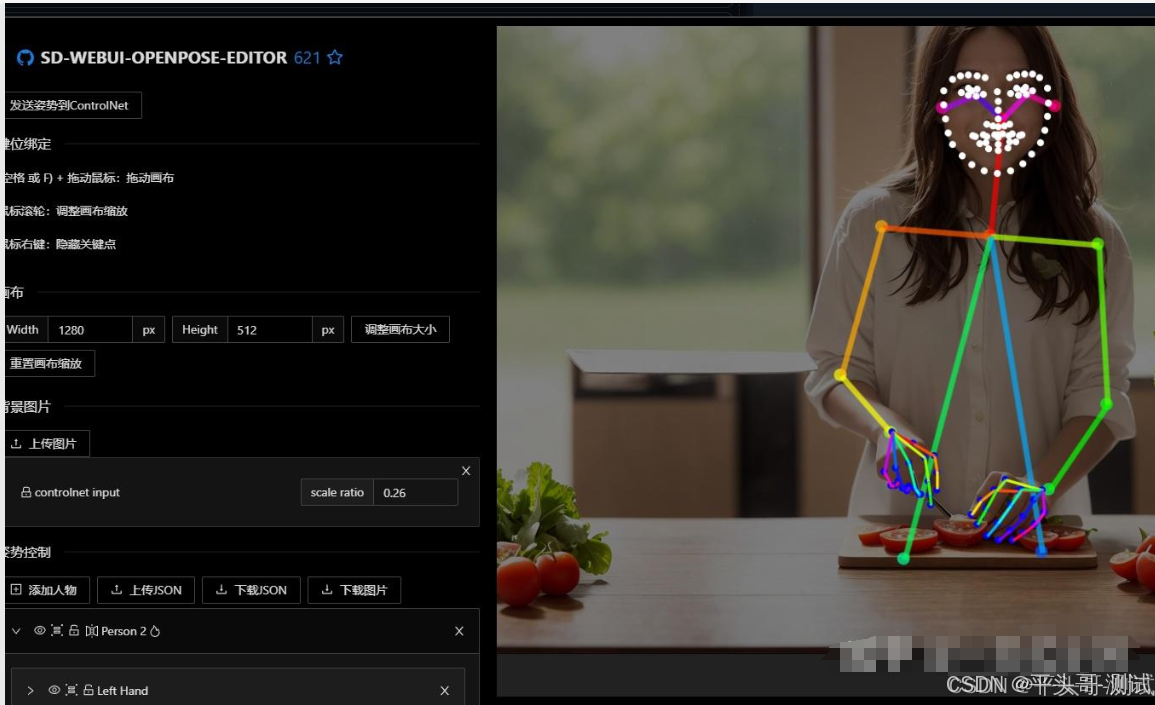
5.3.3.3.生成Pose后,点右下编辑可进入编辑界面。没有的话就去扩展里搜openPose安装
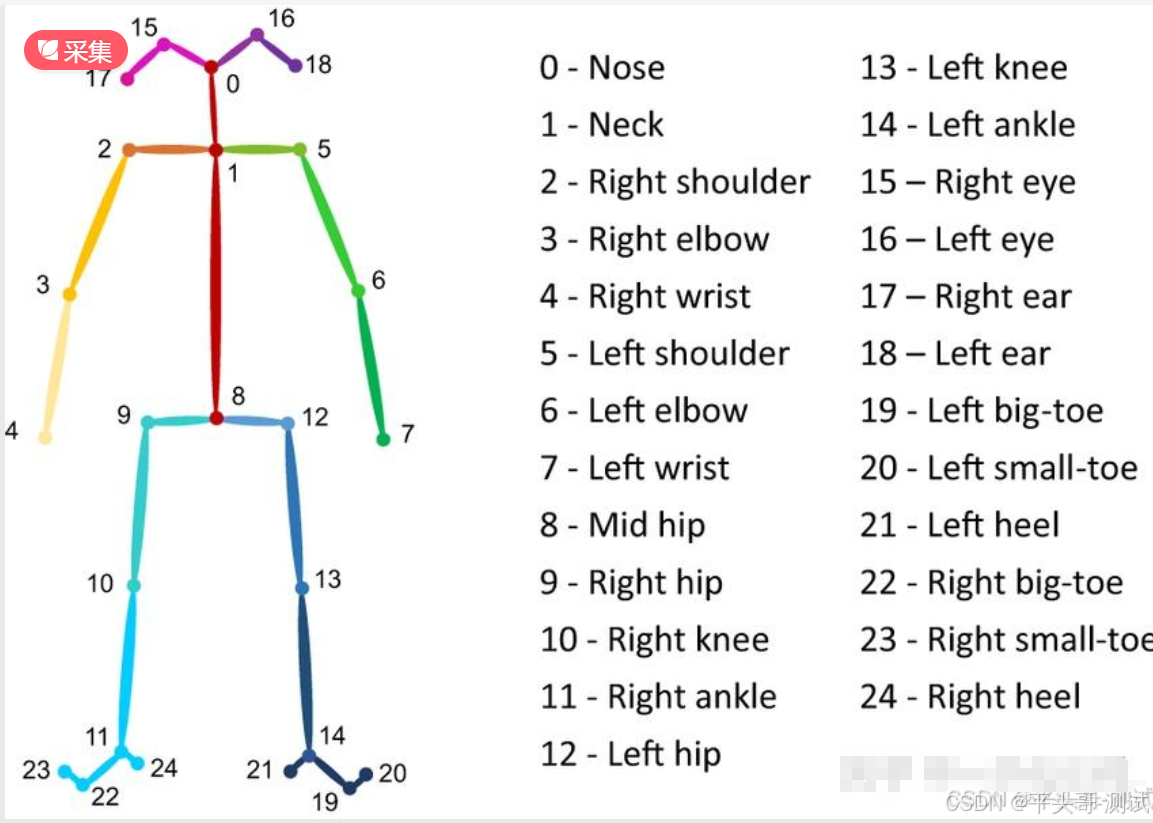
5.4.各节点对应名称
5.5.获取姿态图的途径
5.5.1.在现实中用相机给自己拍一张想要的姿态,再上传并提取
5.5.2.使用姿态编辑器生成
5.6.看到网上有openpose骨骼姿势图包下载,有的网友可以发我份,我挂个链接出来
5.6.1.比如三视图
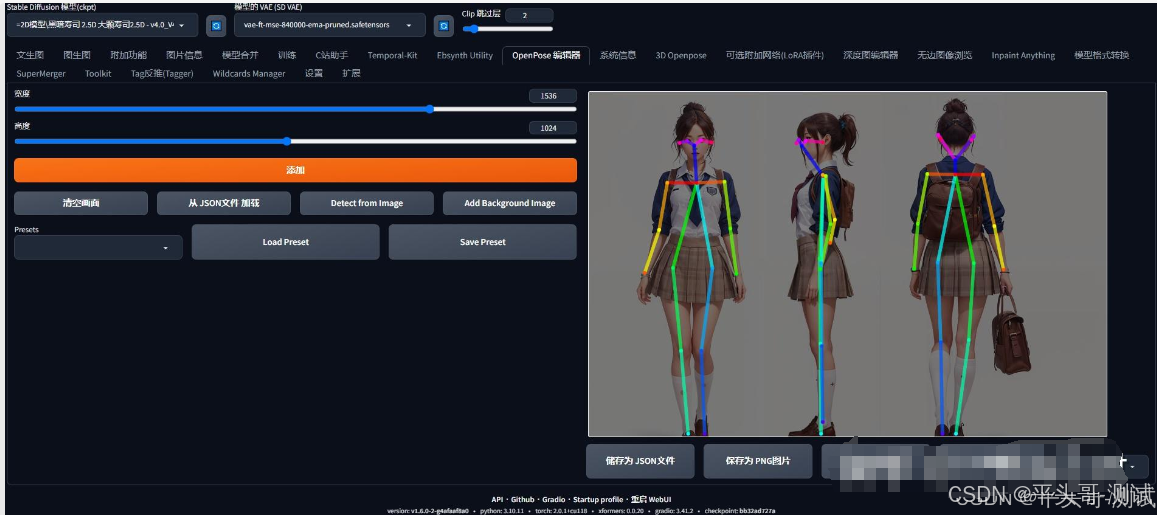
6.inpaint局部修图
模型文件:control_v11p_sd15_inpaint.pth
配置文件:control_v11p_sd15_inpaint.yaml
6.1.在ControlNet中也有一个Inpaint局部重绘的控制
6.1.1.它在文生图和图生图中都可以使用
6.1.2.其主要作用是局部重绘,对象移除、扩图(主要,其它功能一般)
6.2.预处理器
inpaint_only:在保留一些原图的内容和结构的基础上生成新内容
inpaint_only+lama:把原有内容彻底抹除然后生成新内容,更干净
inpaint_global_harmonious:全局融合算法
因此导致涂抹以外的区域也发生了一些变化,并且整体画面的颜色也发生了改变
6.2.1.看需求,如果重绘的不干净就用lama,希望原有的一些内容和新内容衔接就用only

6.3.由于上传ControlNet的图片显示很小,直接进行涂抹操作会不太方便
6.3.1.鼠标停留在左上角图片两个字那里会有画布画笔操作的快捷键提示:
Alt+滚轮-缩放画布
Ctrl+滚轮-调整画笔大小
R-重置缩放
S-全屏模式
F.移动画布
6.4.局部重绘
6.4.1.文生图Inpaint
STEP1:在ControlNet中上传该图片,勾选完美像素、选择局部重绘和预处理器
不要忘记点击一下将图片尺寸发送到生成设置; 按S进入全屏对需要重绘部分进行涂抹
STEP2:提示词中我输入咖啡色的衣服,背对镜头
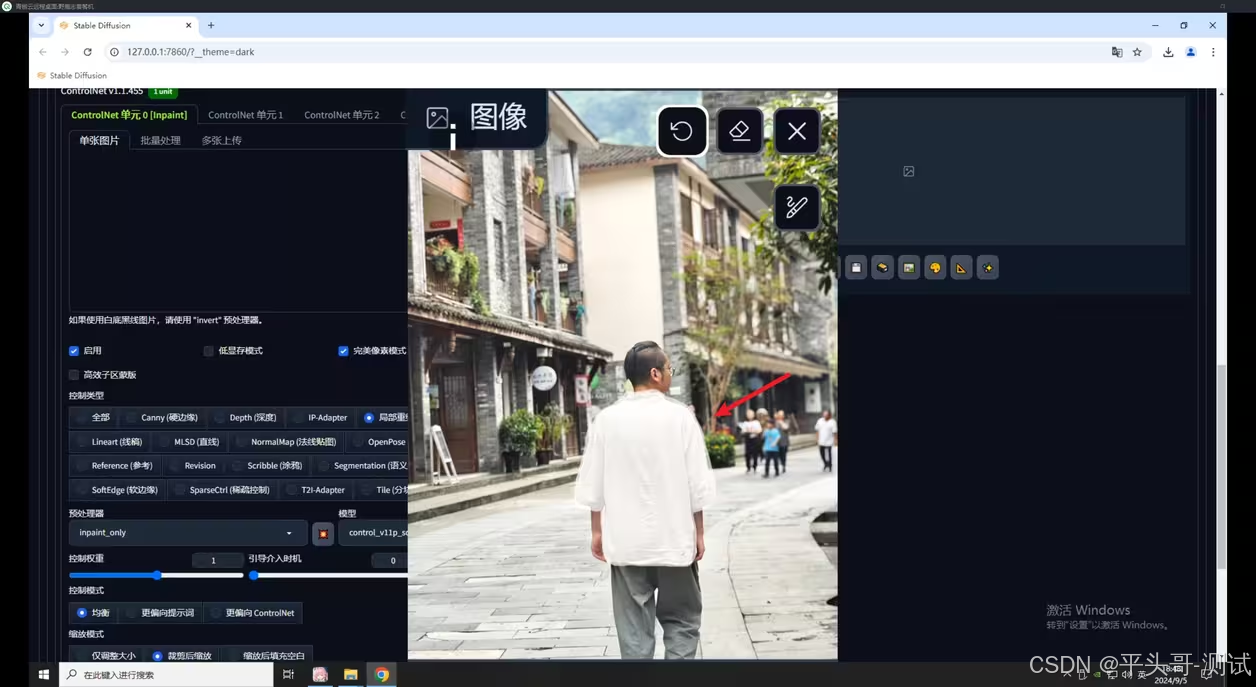
6.4.1.1.提示词中我输入咖啡色的衣服,背对镜头
6.4.1.2.从生成结果可以看到,除了global以外,其他两种都挺好

6.5.接下来再看看与图生图局部重绘的对比
6.5.1.在局部重绘中,同样先涂抹需要移除的部分;输入提示词并将重绘幅度调整到1
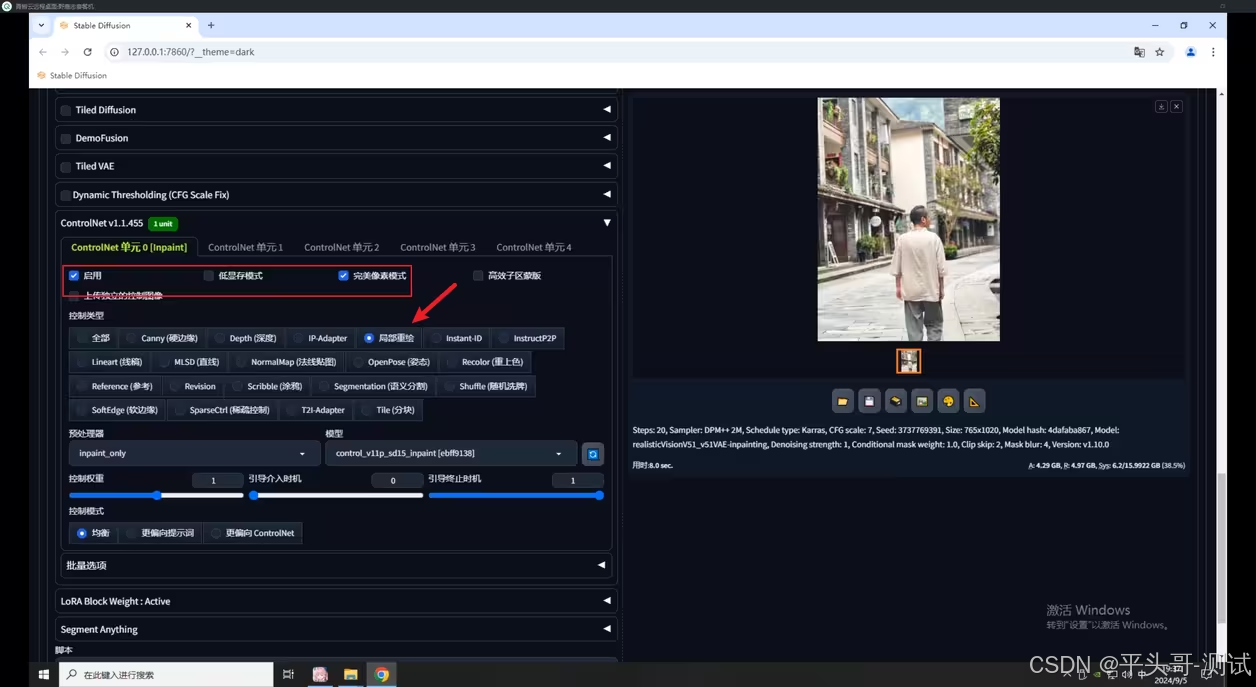
6.5.2.相比之下,个人感觉如果是移除对象,在图生图的局部重绘中,反而不使用ControlNet效果更好
6.5.2.1.而开启ControlNet后,生成效果反而不如不开启时理想
6.5.2.2.因此个人建议局部重绘时,可以选择在文生图中使用ControlNet局部重绘
6.5.2.3.或直接选择在图生图中进行局部重绘(不启用ControlNet重绘)

6.6.扩图(inpaint的主要用法)
STEP1:首先可以使用提示词反推功能,筛选后将结果复制到文生图的提词框中
负向提示词可随意加入一个负向Embedding模型,或者输入你们常用的负向提词
STEP2:ControlNet中还是上传这张图片,同样发送图片尺寸到生成设置
STEP3:我的原图尺寸是768*1016,这里我改为1280*1016
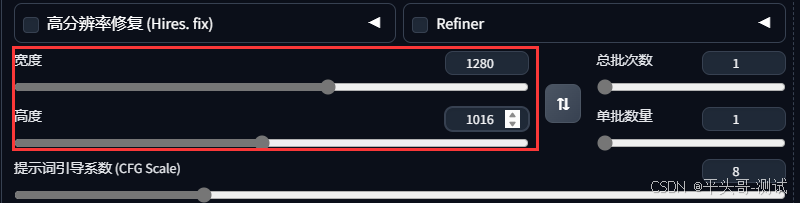
STEP4:缩放模式这里一定要选择缩放后填充空白
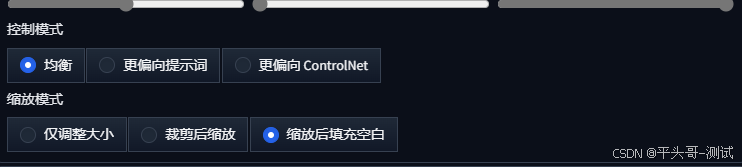
6.6.1.仅调整大小:拉伸模式会导致人物被直接向两侧拉开,使人物形象变形
6.6.2.裁剪后缩放:裁剪模式则会选取原图的中间部分,裁剪掉上下两部分的画面
6.6.3.缩放后填充空白:填充模式会根据原图边缘的内容填充无内容的白色区域
6.6.4.个人感觉,在“ControlNet更重要”的控制模式下,lama预处理器的效果是最好的

7.InstructP2P指令式修图
模型文件:control_v11e_sd15_ip2p.pth
配置文件:control_v11e_sd15_ip2p.yaml
7.1.一种通过提示词编辑图像的算法
7.1.1.该模型是使用50%的指令提示和50%的描述提示进行训练的
7.2.比如上传一张图片,给他发送:“让它着火”,但是目前只支持一些简单的指令
7.2.1.还不成熟,复杂的效果还是不太好
7.3.要点:采用指令式提示词(make Y into X)
7.3.1.如下图示例中的make it snow,让非洲草原下雪
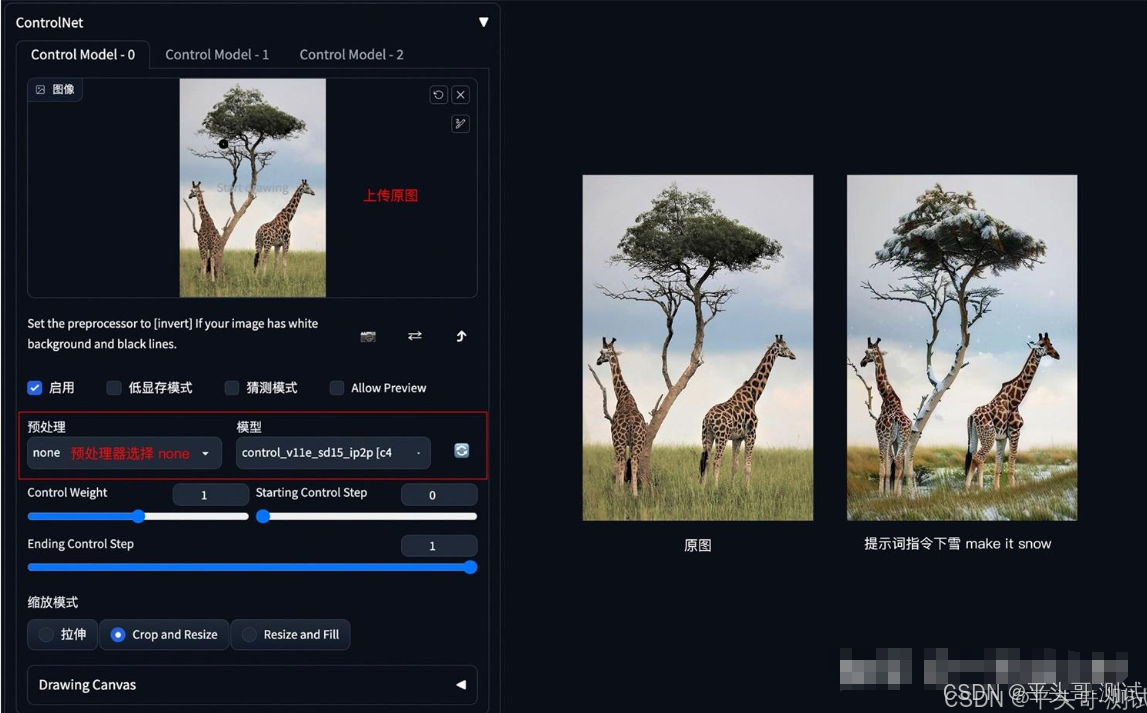
7.3.2.InstryctP2P算法不包含预处理器,目前只有一个control_v11e_sd15_ip2p模型
7.4.InstructP2P模型还可以被应用于图像修复和老照片修复等领域
7.4.1.通过输入相应的文字指令,该模型可以自动识别出需要修复的区域
7.4.2.并自动进行修复处理,从而得到一张更加完美的修复照片或修复图像
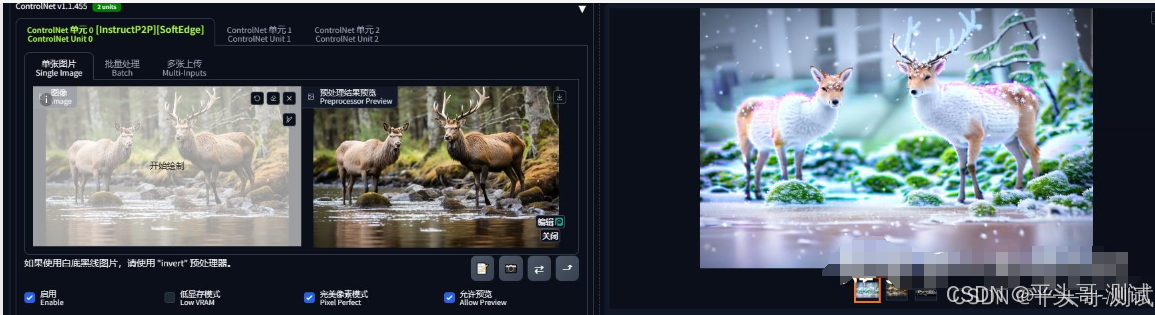
7.4.3.make it winter,再加个canny,要不此鹿就非彼鹿
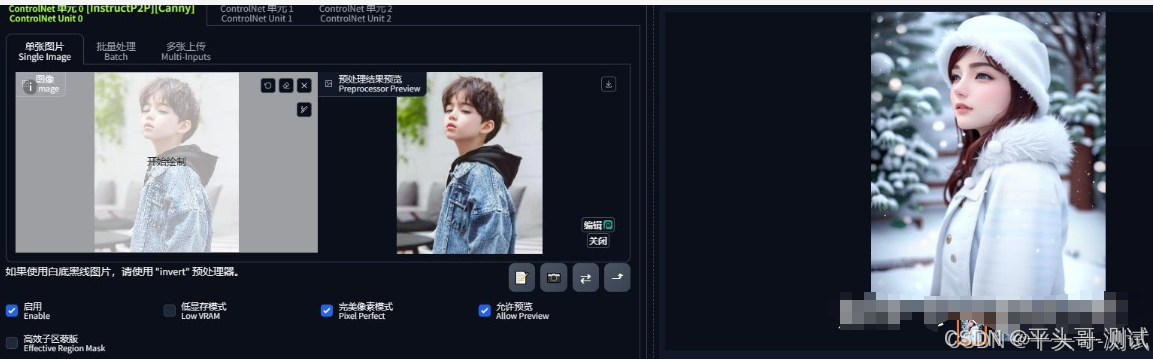
7.4.4.只加make it winter,结果男孩就变成女孩
7.4.5.在上面的基础上再加个Controlnet
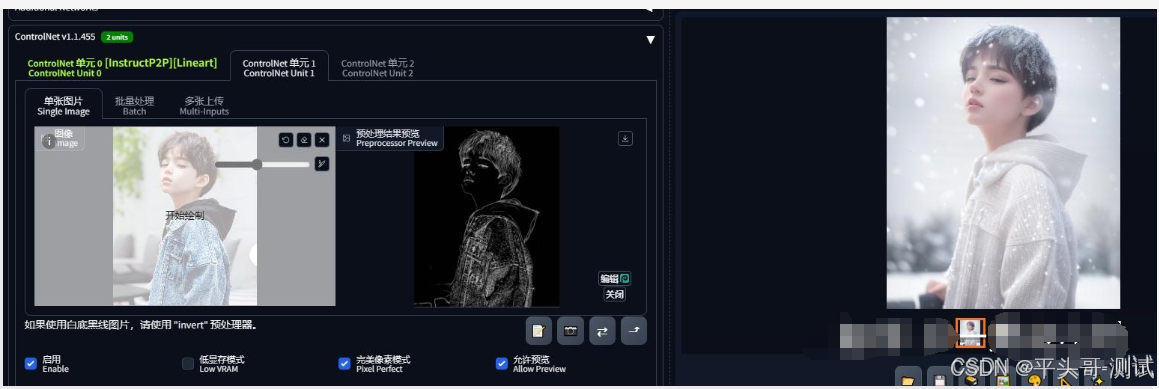
8.tile
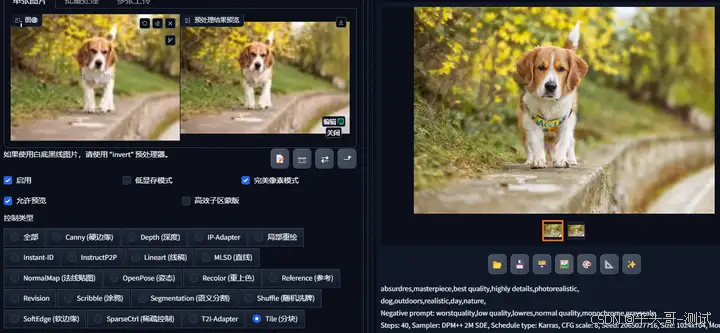
8.1.在SD Web UI工具中经常翻译为“分块”
8.1.1.它的主要作用是在保持图片整体布局的基础上给照片添加细节
8.2.基于这个特性,经常结合各种插件做图片的精细放大处理
8.2.1.用于对图片进行高清修复改善画质
8.3.另外它还有一个很重要的功能,就是用来转换图片风格
8.3.1.比如真人漫改,漫改真人、各种艺术字制作等
8.4.随着学习的深入,个人觉得Tile的功能真的超级实用,故单独起一章来详细说明
https://zhuanlan.zhihu.com/p/715905324
9.Recolor重上色
9.1.在SD中实现老旧照片重上色,最直接的方式是通过ControlNet的模型Recolor实现
9.2.该模型可以保持图片的构图,它只会负责上色,图片不会发生任何变化
9.3.模型文件:ioclab_sd15_recolor.safetensors
9.4.下载地址:https://huggingface.co/lllyasviel/sd_control_collection/tree/main
9.5.ControlNet中的Recolor模型相对较新,需要把ControlNet的模型更新到1.1.400以上的版本才可以

9.6.参数设置
9.6.1.Recolor模型可以使用在文生图或者图生图中,两者的效果差不多
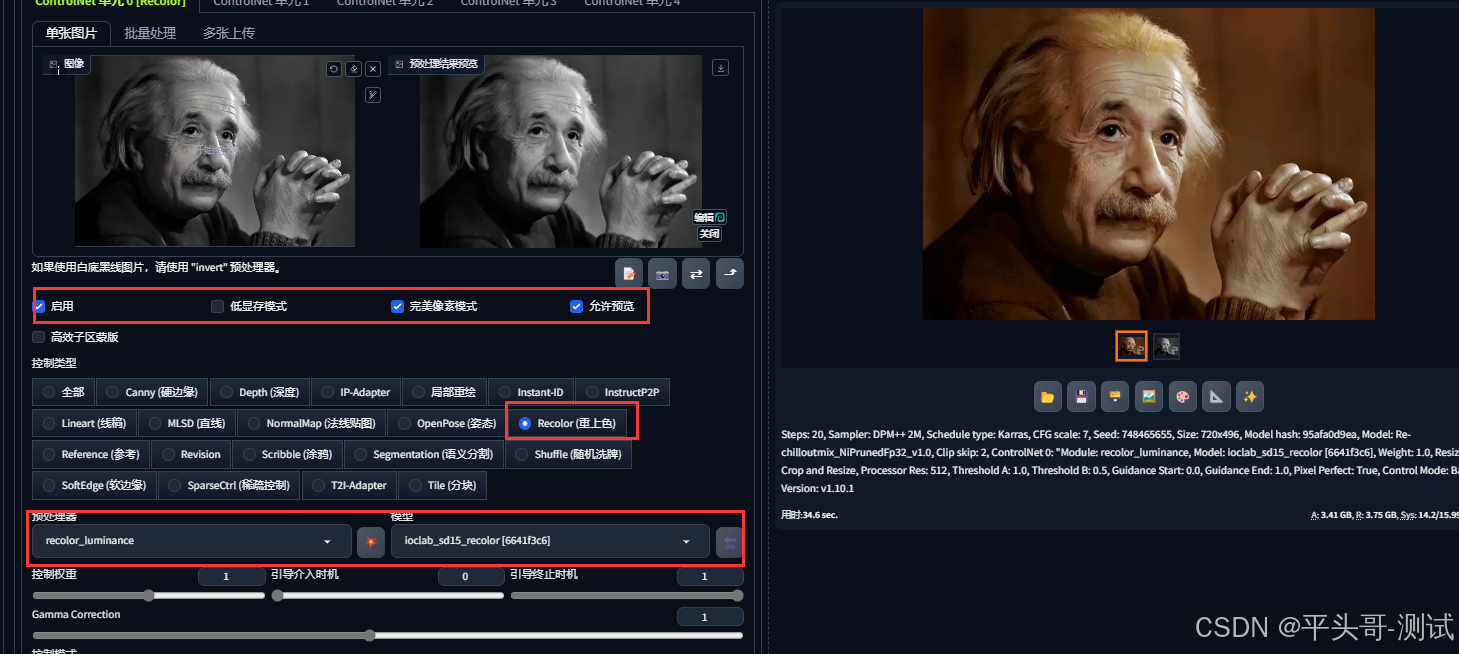
9.7.Recolor预处理器有2个
9.7.1.recolor_luminance:调节“图像亮度”以去色
9.7.1.1.提取图像特征信息时注重颜色的亮度,目前大部分情况下这个效果更好
9.7.2.recolor_intensity:调节“图像强度”以去色
9.7.2.1.提取图像特征信息时注重颜色的饱和度
9.7.3.通过下面2张重上色图片效果对比
9.7.3.1.发现recolor_luminance重上色效果要亮一些,效果看起来更好一些

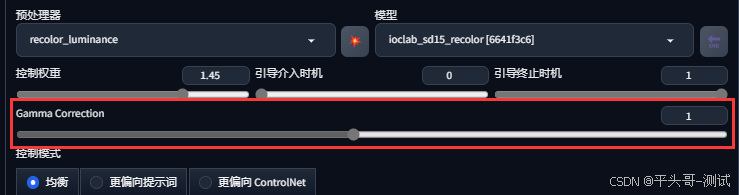
9.8.Gamma Correction参数
9.8.1.该选项用于调节图片的明暗,参数值越小图片越亮,参数值越大图片越暗,默认值为1
9.8.2.进行上面的设置之后,点击【生成】按钮,就可以完成黑白图片对应的彩色图片
九.其它
1.SparseCtrl (稀疏控制)
1.1.一个可以增强AI生成视频可控性的项目
1.1.1.这个项目的诞生将为Animatediff注入新的生命力
1.1.2.相当于是视频领域的ContorlNet
1.2.通过SparseCtrl,用户不仅能够自动选择关键帧来介入,降低资源消耗
1.2.1.还能更灵活地掌控视频生成的过程


















 2439
2439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











