









00 简介
本文发表于FAST 2023。
应用程序启动速度在个人计算/通信设备上的重要性不言而喻,特别是在笔记本电脑、单板计算机和智能手机上。当前,应用启动缓慢主要受限于闪存存储性能、应用复杂性增加以及并行性利用不足等问题。
为了解决这些问题,本文提出了Paralfetch,通过以下方式加速应用启动:1)准确收集启动相关的磁盘读请求;2)预先调度这些请求以提高预取过程中的I/O吞吐量;3)将应用执行与磁盘预取重叠,以隐藏磁盘访问时间。
Paralfetch在桌面/笔记本电脑、Raspberry Pi 3板和安卓智能手机上显著减少了应用启动时间,并优于现有的预取机制,有效解决应用启动慢问题,显著提升了用户体验。
01 背景与动机
启动延迟取决于系统的先前状态,尤其是磁盘缓存。冷启动发生在磁盘缓存中没有应用所需数据时,而热启动则是应用最近运行过,磁盘缓存中仍保留所需数据,因此启动更快。应用预取器通过在首次启动时收集启动相关数据,并在后续启动时预取这些数据来加速加载,从而减少冷启动时间开销,使其接近于热启动。
1.1 Linux下的磁盘缓存
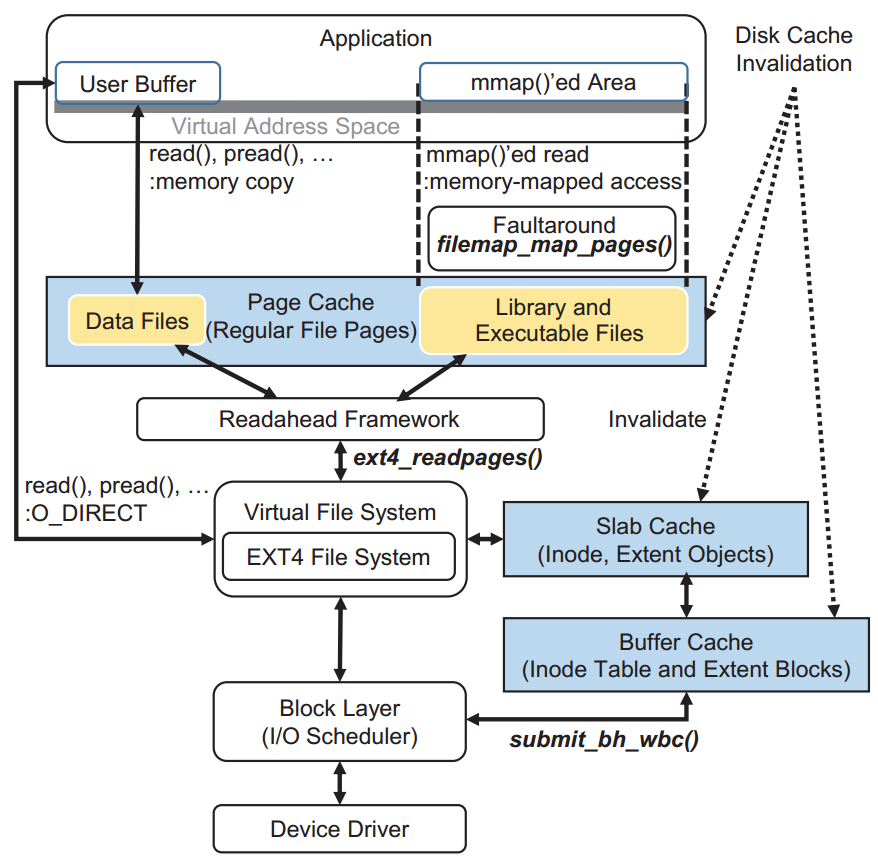
Linux包含三种磁盘缓存:用于常规文件的Page Cache、用于元数据对象的Slab(或slub)缓存和用于元数据块的Buffer Cache。Slab用作Buffer Cache的对象粒度元数据缓存。Read系统调用根据其参数显式地填充Page Cache,而映射文件的Page Cache则通过页面故障机制填充。预读框架负责填充Page Cache的内容,并根据访问顺序决定要预取多少块。元数据块可以通过EXT4文件系统预取。
1.2 代表性的预取程序
Windows Prefetcher:自XP开始,Windows包含用于启动和系统引导的预取功能,适用于HDD,也可配置用于SSD。在学习阶段,它识别应用所需文件的内存页,并在后续启动时预取这些块,通过碎片整理优化HDD磁头移动。
GSoC Prefetch:这是基于Linux的HDD预取器,通过跟踪引用页面来获得与启动相关的块信息,并在后续启动时按记录顺序预取块,从而减少寻道和旋转延迟。它还具有类似Windows预取器的碎片整理工具。
FAST:这是最新的基于Linux的SSD预取器,通过清除slab、缓冲区和Page Cache,在学习阶段监控块的LBA,创建预取程序,并在后续启动时与应用同时执行,无需I/O优化。
1.3 Paralfetch
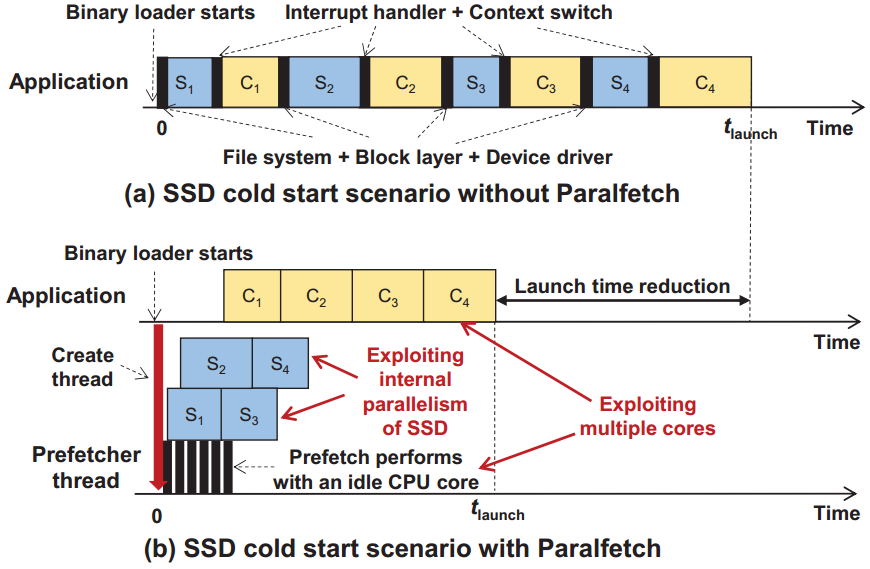
图(a)是一个应用的冷启动场景,从上层发出指令到向SSD请求块,再到中断返回使用刚刚取到的块继续进行计算,然后再发出下一个指令,过程全部串行执行(其中S代表向SSD请求块,C代表CPU的计算)。通过Paralfetch可以使这个过程以一个流水线的形式并行执行,利用多核运行使用命令队列发出异步I/O请求,使SSD的访问与CPU的计算并行,更好地利用多核扩展性和SSD的内部并行性。
02 Paralfetch架构设计
预取器通常包含两个阶段:学习阶段和预取阶段。在学习阶段,通过监视应用首次启动期间的页面故障,来检测启动期间产生的I/O请求;在预取阶段,通过学习阶段获取到的信息对相应的I/O进行预先调度,提升应用的启动速度。
下图显示了Paralfetch的整体架构,包含三个关键模块:1)1)跟踪模块:用于准确收集启动相关的磁盘读请求;2)预取调度模块:对预取的I/O请求进行调度以提高预取过程中的I/O吞吐量;3)并行执行模块:将应用执行与磁盘预取并行,以隐藏磁盘访问时间。
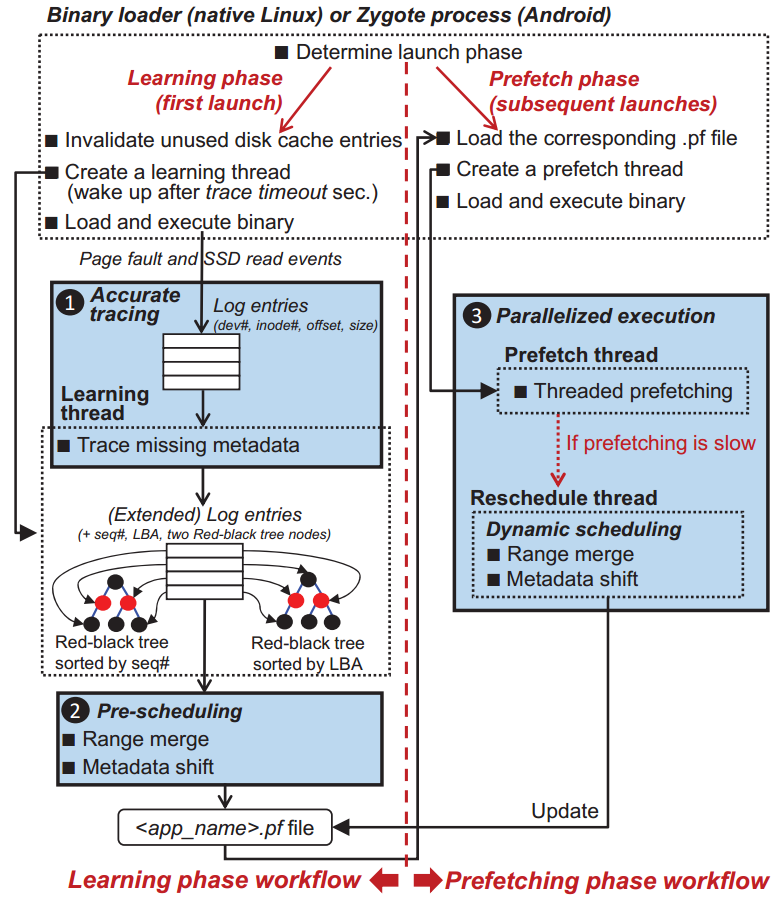
2.1 准确溯源
在学习阶段,Paralfetch将使磁盘缓存中未使用的条目无效,以便Paralfetch为后续启动应用程序收集适当的块集。然后,它通过使用带I/O日志代码的检测文件系统函数来记录在这些缓存中找不到的块的I/O请求,这些请求用于在启动期间预取那些额外的块。
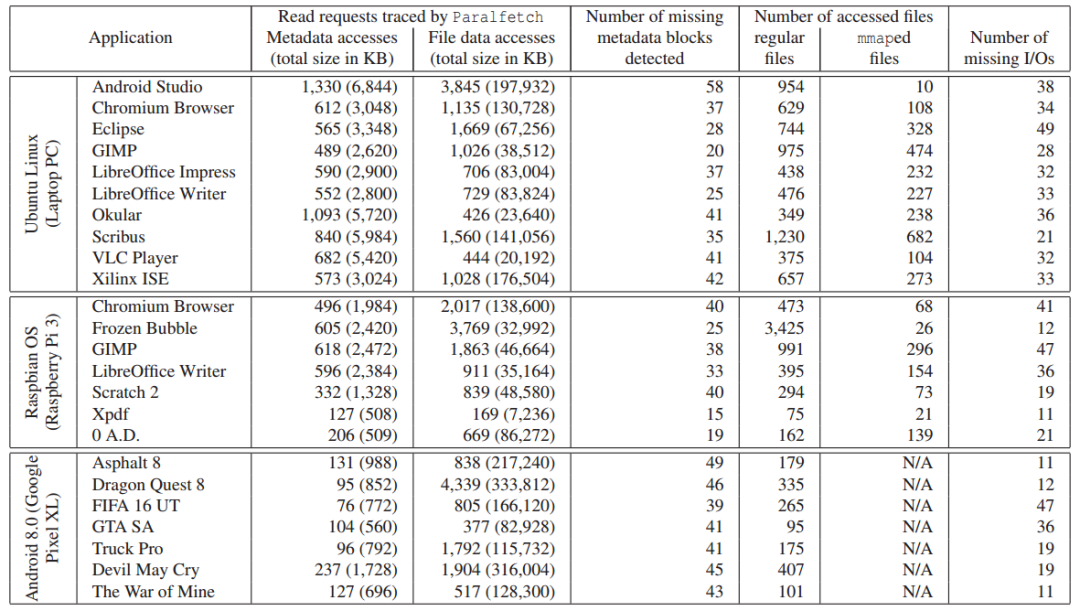
下表显示了在PC等设备上检测到的不同应用启动期间的miss块数量。
2.2 预取调度
在应用程序启动期间完成磁盘I/O请求的收集后,parallelfetch预先调度这些请求以加快预取阶段,合并和重新排序请求,从而利用SSD的内部并行性。
(1)Range merging。实验可得,一个大范围的I/O读取速度要比多个小范围的I/O要快。通过merge操作使一定范围内相邻的I/O操作合并为一个大的I/O操作,以提高I/O吞吐率。但过于激进的合并策略可能会妨碍后续块的及时预取,因此不应该将过远的两个相邻I/O合并,作者对其设定了一个阈值,相邻I/O之间的命令数量超过这个阈值就不再合并。
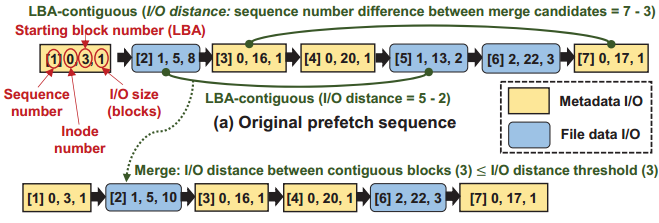
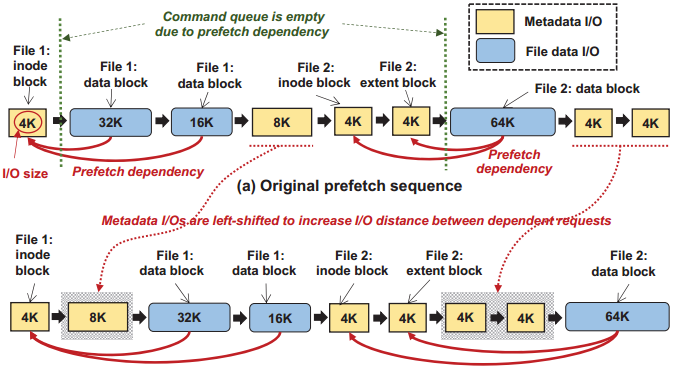
(2)元数据转移。对于元数据块和数据块的预取往往存在依赖关系,如在Ext4中对数据块的请求只能在关联的元数据块被读取之后发出,这种依赖性往往会限制可以排队的命令的数量。通过将元数据的I/O请求提前调度更好地利用命令队列,在命令队列中填充更多的I/O请求。
2.3 并行执行:应用程序执行与磁盘预取并行
及时预取可以更好地使应用程序执行与预取并行。重新排序或合并相隔很远的块可以提高预取吞吐量,但也可能妨碍及时预取。下图实验结果表明,预取吞吐量并不总是与启动性能相对应,从而证实了这一说法。Paralfetch通过动态调整元数据移动和范围合并来避免这个缺陷,当检测到预取瓶颈时,通过增加I/O距离阈值和/或元数据位移大小来重新调度预取条目。
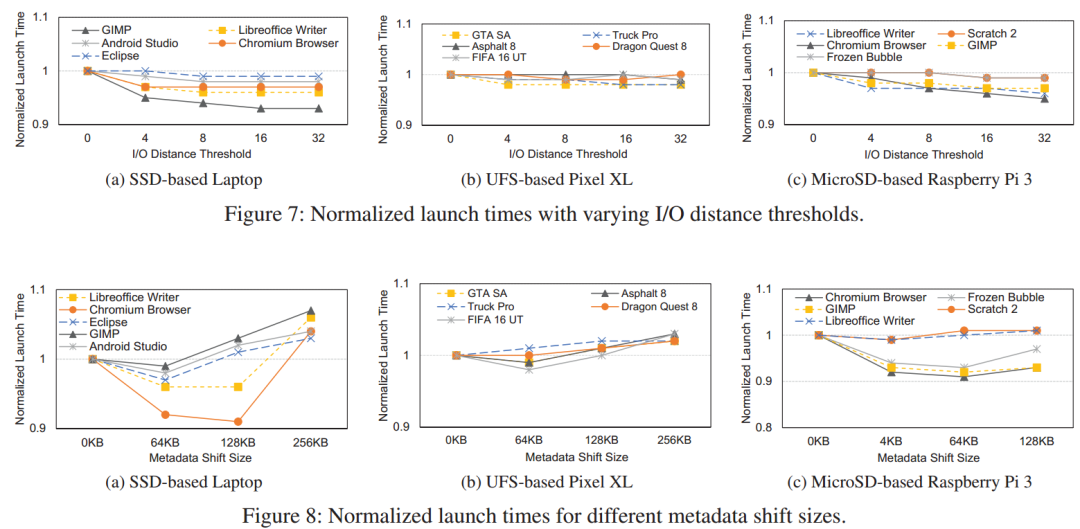
动态调度优化预取表项。最初,Paralfetch使用默认阈值进行元数据移动和范围合并,如表2所示。随后,根据CQ支持的可用性,只增加其中一种方法的阈值。元数据移动阈值以16KB为单位递增,I/O距离阈值以4为单位递增。
检测预取瓶颈。当应用程序必须等待预取线程请求的块时,它会经历更多的上下文切换,这意味着预取线程没有及时预取。具体来说,预取线程收集启动应用程序在预取期间进行的上下文切换次数。如果上下文切换的数量低于用户定义的阈值(默认为预取表项数的5%),则自动终止动态调度。
03 实验
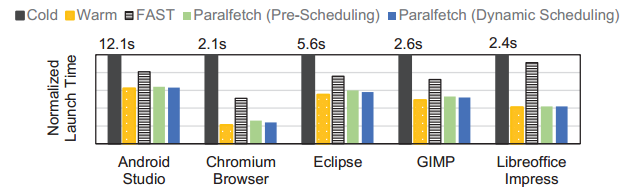
作者在PC,树莓派,Google Pixel上检测了冷启动,热启动的时间变化,以及应用Paralfetch、GSoC Prefetcher和FAST之后的冷启动速度提升对比。
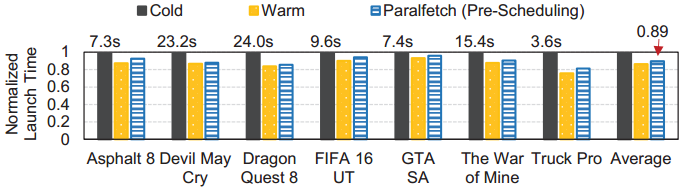
下图展示了在配备QLC SSD的笔记本电脑上启动十款非游戏应用和六款游戏程序的冷热启动时间以及使用GSoC Prefetch和Paralfetch的对比。

下图是在上述笔记本上与FAST的对比效果。
以下是在树莓派上进行同样的实验:

在Google Pixel上重复实验:
04 总结
文章提出了通过更精确的跟踪、快速I/O读取的预调度和预取线程重叠来实现接近热启动的启动性能的Paralfetch。Paralfetch在CPU、内存和存储方面的开销可以忽略不计。在运行Linux的各种个人计算/通信设备上,Paralfetch的性能明显优于现有的预取器。















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









