







序言:
最简单的分类器是将所有的训练数据所对应的类别都记录下来,并把测试数据与所有的训练数据进行匹配,若属性全部对应,则属于同一类。但并不是所有的测试数据都能够找到与之对应的训练数据,也有可能一个测试数据有好几组训练数据与之对应。因此,便有了。
思想:
是通过不同特征值之间的距离对数据进行分类。如果一个样本在特征空间中的
个最相似样本(特征空间中最邻近的
个)中的大多数都属于某一类,则该样本也属于该类。
在中,所有相邻的样本都已知其正确的分类。该方法在决策上只依赖最近
个样本的特征。
另外,在中通过计算样本之间的距离来估算相似性,以此来解决匹配问题。距离越近,相似性越高。计算距离的方法通常用欧式距离或曼哈顿距离。
例子:
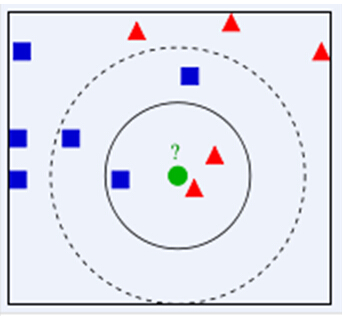
假设下图中间绿点为测试样本,旁边红色三角形和蓝色正方形为已知正确分类的样本。
当时,易知中间绿点和红色三角形同属一类(3个最相似样本三角形占2个)。
当时,易值中间绿点和蓝色正方形同属一类(5个最相似样本正方形占5个)。
总结:
1.计算测试数据与训练数据之间的距离,来估算其相似性。
2.对这些距离按照从小到大进行排序。
3.选取距离最小的个点(即前
个点)。
4.找出前个点中出现频率最多的一类,则测试数据就属于该类。
————————————————————update————————————————————















 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









