






NeRF必读:PixelNeRF
前言
NeRF从2020年发展至今,仅仅三年时间,而Follow的工作已呈井喷之势,相信在不久的将来,NeRF会一举重塑三维重建这个业界,甚至重建我们的四维世界(开头先吹一波)。NeRF的发展时间虽短,有几篇工作却在我研究的领域开始呈现万精油趋势:
- PixelNeRF----泛化法宝
- MipNeRF----近远景重建
- NeRF in the wild----光线变换下的背景重建
- Neus----用NeRF重建Surface
- Instant-NGP----多尺度Hash编码实现高效渲染
今天我们就来学习将NeRF泛化的万精油:PixelNeRF。
概述
总体来说PixelNeRF有以下两点比较厉害:
- 利用稀疏输入构建三维场景表达。
- 可以基于category泛化三维场景表达(在张三李四上训练,给张王五的照片就能生成王五了,但给张哈士奇不一定能行得通)。
背景
NeRF将空间中的一点
x
∈
R
3
\mathbf{x}\in \mathbb{R}^3
x∈R3在方向
d
\mathbf{d}
d上的观测结果描述为:
f
(
x
,
d
)
=
(
σ
,
c
)
f(\mathbf{x},\mathbf{d})=(\sigma,\mathbf{c})
f(x,d)=(σ,c)
通过对函数inference出的
(
σ
,
c
)
(\sigma,\mathbf{c})
(σ,c)积分就能渲染出2D图像:
C
^
(
r
)
=
∫
t
n
t
f
T
(
t
)
σ
(
t
)
c
(
t
)
d
t
\mathbf{\hat{C}(r)}=\int^{t_f}_{t_n}T(t)\sigma(t)\mathbf{c}(t)dt
C^(r)=∫tntfT(t)σ(t)c(t)dt
其中
T
(
t
)
=
exp
(
−
∫
t
n
t
σ
(
s
)
d
s
)
T(t)=\exp(-\int^t_{t_n}\sigma(s)ds)
T(t)=exp(−∫tntσ(s)ds)表示透射率,离镜头越远,透射率越低。
至于Loss就简单了:
L
=
∑
r
∈
R
3
∥
C
^
(
r
)
−
C
(
r
)
∥
2
2
\mathcal{L}=\sum_{r \in \mathbb{R}^3}\Vert \mathbf{\hat{C}(r)}-\mathbf{C(r)}\Vert^2_2
L=r∈R3∑∥C^(r)−C(r)∥22
PixelNeRF指出了NeRF的不足:
NeRF的每个scene都是单独训练的,scene与scene之间并不能共享知识,这对于神经网络这种可以共享先验知识的模型来说是极大的浪费,PixelNeRF的提出希望能弥补这一缺憾。
Image-conditioned NeRF
为了解决NeRF不能共享scenes之间的知识的问题,作者提出了一种Image-conditioned的架构,该架构由两个组件构成:
- 1个全连接的图像编码器 E E E,该编码器给出的图像特征将与原图像逐像素对齐。
- 1个类NeRF的网络结构,给定空间位置 x \mathbf{x} x和相应的编码特征 E ( I ) x E(I)_x E(I)x, NeRF网络输出该点的 ( σ , c ) (\sigma,\mathbf{c}) (σ,c)。
具体来说,结合下图与公式,就可以对PixelNeRF有一个非常清晰的认知:
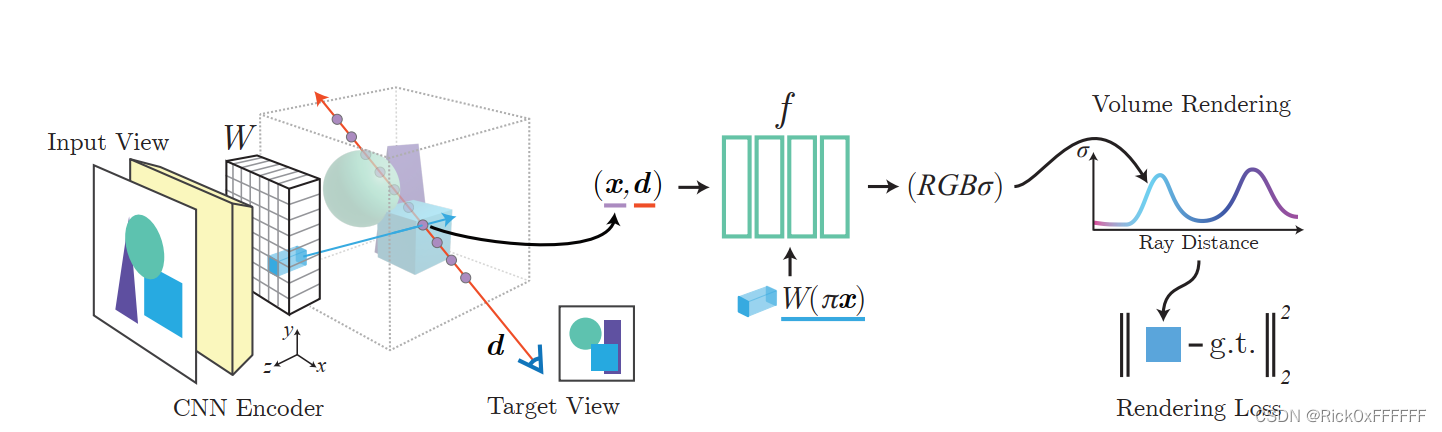
首先该图分为三部分,分别是:
- CNN对图像进行编码
- NeRF网络inference: ( x , d , I ) → ( c , σ ) (\mathbf{x,d},I) \rightarrow(\mathbf{c},\sigma) (x,d,I)→(c,σ)
- Volume Rendering
CNN Encoder:编码图像得到一个feature 图,WHF, F是feature数量,将输出结果命名为 W W W, π \pi π是一个将3维空间的点 x x x映射到二维图像上的点(u,v)的映射函数,则 W ( π ( x ) ) W(\pi(x)) W(π(x))就表示三维点 x \mathbf{x} x对应的二维像素的feature了
NeRF Network:
f
(
γ
(
x
)
,
d
;
W
(
π
(
x
)
)
)
=
(
σ
,
c
)
f(\gamma(\mathbf{x}),\mathbf{d};\mathbf{W}(\pi(x)))=(\sigma,\mathbf{c})
f(γ(x),d;W(π(x)))=(σ,c)
其中 γ ( x ) \gamma(\mathbf{x}) γ(x)是position encoding。
Volume Rendering:和经典NeRF一致。
Incorporating Multiple Views
作者希望通过融合多视角下的观测来构建出更为逼真的三维表达。 如何融合呢?对于一个世界坐标系下的query point
x
\mathbf{x}
x ,以及它的view direction
d
\mathbf{d}
d, 给定N个相机视角,以及它的位姿:
P
(
i
)
=
[
R
(
i
)
t
(
i
)
]
\mathbf{P}^{(i)}=[\mathbf{R}^{(i)}\space \mathbf{t}^{(i)}]
P(i)=[R(i) t(i)]
通过位姿变换,就可以求解出每个相机坐标系下
x
x
x的位姿了:
x
(
i
)
=
P
(
i
)
x
,
d
(
i
)
=
R
(
i
)
d
\mathbf{x}^(i)=\mathbf{P}^{(i)}\mathbf{x}, \space \mathbf{d}^{(i)}=\mathbf{R}^{(i)}\mathbf{d}
x(i)=P(i)x, d(i)=R(i)d
作者在此将NeRF做了一个层级划分,采用了PointNet之类的思想,先通过一个initial layers(命名为
f
1
f_1
f1)获得一个中间向量:
V
(
i
)
=
f
1
(
γ
(
x
(
i
)
)
,
d
(
i
)
;
W
(
i
)
)
\mathbf{V}^{(i)}=f_1(\gamma(\mathbf{x}^{(i)}),\mathbf{d}^{(i)};\mathbf{W}^{(i)})
V(i)=f1(γ(x(i)),d(i);W(i))
随后利用pooling 操作
ψ
\psi
ψ将多个中间向量融合在一起:
(
σ
,
c
)
=
f
2
(
ψ
(
V
(
1
)
)
,
ψ
(
V
(
2
)
)
,
.
.
.
,
ψ
(
V
(
n
)
)
)
(\sigma,\mathbf{c})=f_2(\psi(\mathbf{V}^{(1)}),\psi(\mathbf{V}^{(2)}),...,\psi(\mathbf{V}^{(n)}))
(σ,c)=f2(ψ(V(1)),ψ(V(2)),...,ψ(V(n)))
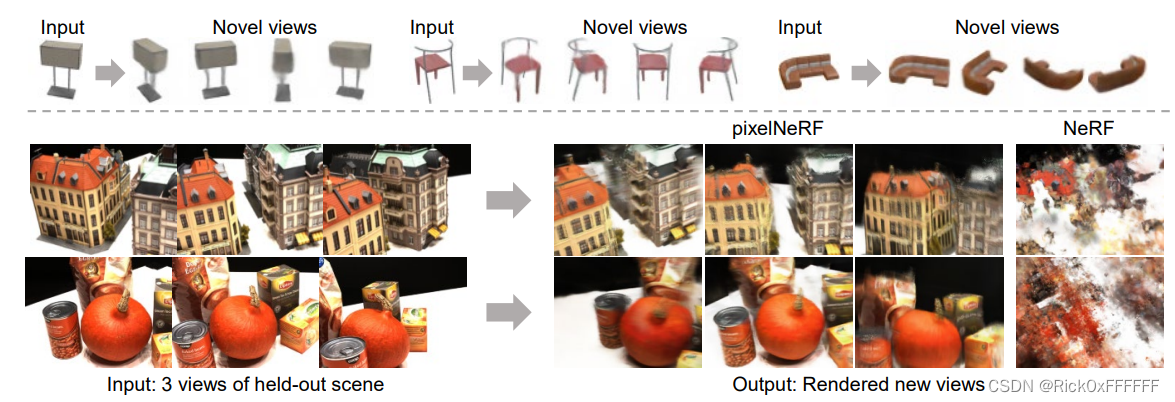
Result
效果不错:

好多文章都在用PixelNeRF: SceneRF, AutoRF等等,强推!要是喜欢本文就点个赞吧~
参考文献
Yu, Alex, et al. “pixelnerf: Neural radiance fields from one or few images.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.















 3031
3031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









