







简介
主页:https://alexyu.net/pixelnerf/
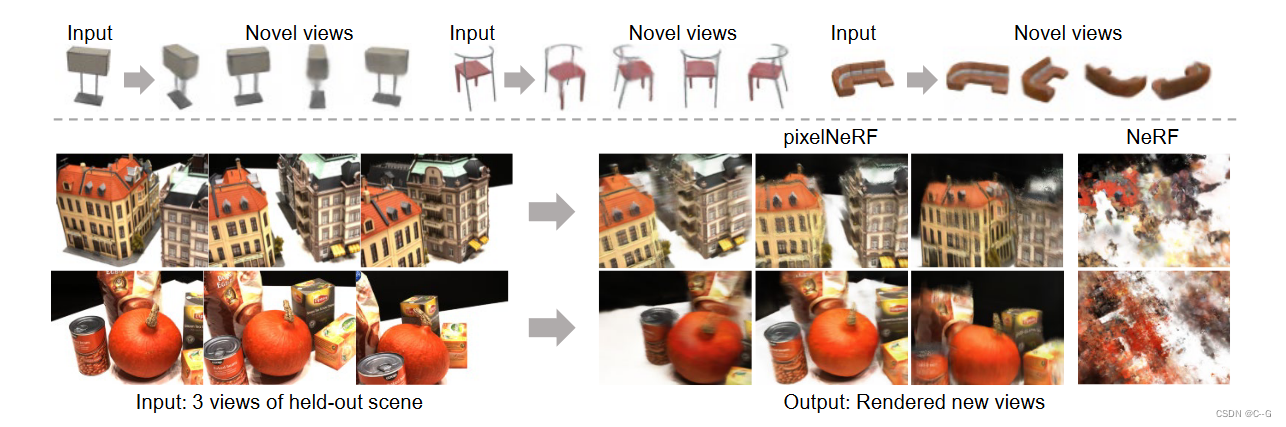
pixelNeRF,一个学习框架,从单个(上)或少数摆拍的图像(下)预测神经亮度场(NeRF)的表示。PixelNeRF可以在一组多视图图像上训练,允许它从很少的输入图像生成可信的新视图合成,而无需测试时间优化(左下)。相反,NeRF没有泛化功能,并且当只有三个输入视图可用时性能很差(右下)
pixelNeRF目的是在已知极少视角时也能很好地合成新视角。那首先NeRF为什么不能呢?原因很简单:NeRF没有充分利用已知信息。pixelNeRF的方法十分直接:将已知view image也作为输入用于神经渲染!
实现流程
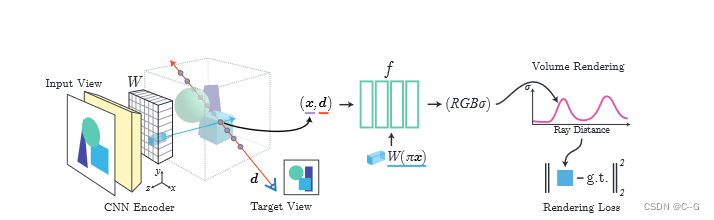
对于沿着观察方向为d的目标摄像机射线的查询点x,通过投影和插值从特征体W中提取相应的图像特征。然后将该特征与空间坐标一起输入NeRF网络f。对输出的RGB和密度值进行体积渲染,并与目标像素值进行比较。坐标x和d在输入视图的相机坐标系中
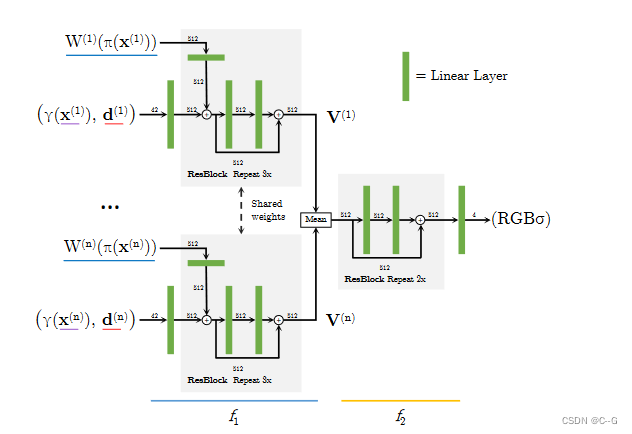
pixelNeRF并不对 view direction 进行编码
通过不同input view得到的neural representation通过求均值的方式聚合
单图像生成
pixelNerf由两部分组成:将输入照片转化为像素级别网格的Encoder E,以及Nerf
论文的坐标系都固定在输入图片的视图空间(view space)而非正交空间(canonical space)。此处简单提一下原因:如果是正交空间,则需要多次优化以达到较好的效果,而论文所提的方法可以实现将任意视角的图片作为输入,也不需要大量优化
对于给定的图片I,首先提取出其特征向量W=E(I)
给定一个场景的输入图像I,首先提取一个 feature volume特征体积W=E(I),对于相机射线上的一个点x,我们利用已知的本质信息将x投影到图像坐标π(x)上,检索相应的图像特征,对像素级特征进行双向插值,提取特征向量W(π(x)) 。这些图像特征会和位置向量和视角方向(都是在输入图片的视图空间中)一起进入原Nerf网络f
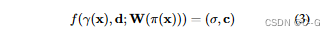
γ(·)是x上的一个位置编码,在原始的NeRF[27]中引入了6个指数增长的频率。图像特征作为每一层的残余合并
查询视图方向是确定NeRF网络中特定图像特征的重要性的有用信号
如果查询视图方向与输入视图方向相似,则模型可以更直接地依赖于输入;如果它不同,则模型必须利用学习到的先验
在多视图的情况下,视图方向可以作为不同视图的相关性和定位的信号
合并多个视图
相较于单图像生成,多图像生成需要生成更多的信息,还需要解决单视图情况下固有的三维几何歧义等问题。本文改进了上述模型,使得其可以利用任意视角的图片作为输入
固定好坐标系(这个坐标系可以是任意的)后,将第ith张照片表示为 I(i),从固定的坐标系到它原有的坐标空间的仿射矩阵表示 ,那么对于每条射线,都可以将其通过该矩阵仿射到原有的坐标系中:
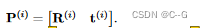
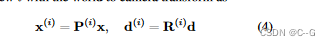
之后将Nerf网络分为两层,第一层表示为f1,分别计算每张图片(注意,此处都是在其原有的视角空间中进行计算):
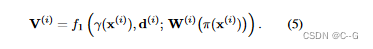
第二层f2,对视角进行合成
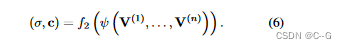
对于单图像,可以理解为

效果
















 1708
1708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









