







文章目录
数据类型
几乎所有数据都可以叫张量(tensor),根据维度来区分,可以分为:
-
标量(Scalar)。单个的实数,如1.2, 3.4 等,维度(Dimension)数为0,shape 为[]。
-
向量(Vector)。n个实数的有序集合,通过中括号包裹,如[1.2],[1.2, 3.4]等,维度数为1,长度不定,shape 为[n]。
-
矩阵(Matrix)。n行m列实数的有序集合,如[[1,2], [3,4]],也可以写成 [ 1 2 3 4 ] \begin{bmatrix}1&2\\3&4\\\end{bmatrix} [1324],维度数为2,每个维度上的长度不定,shape 为[n, m]。
-
张量(Tensor)。所有维度数dim > 2的数组统称为张量。张量的每个维度也作轴(Axis),一般维度代表了具体的物理含义,比如Shape 为[2, 32, 32, 3]的张量共有4 维,如果表示图片数据的话,每个维度/轴代表的含义分别是图片数量、图片高度、图片宽度、图片通道数,其中2 代表了2 张图片,32 代表了高、宽均为32,3 代表了RGB 共3 个通道。张量的维度数以及每个维度所代表的具体物理含义需要由用户自行定义。
在 TensorFlow 中间,为了表达方便,一般把标量、向量、矩阵也统称为张量,不作区分,需要根据张量的维度数或形状自行判断,
基本数据类型有
int、float、double、bool (0和1、true和false)、string
通过TensorFlow的方式去创建张量
如果要使用TensorFlow 提供的功能函数,须通过TensorFlow 规定的方式去创建张量
- 创建标量
tf.constant(1.2)

id 是TensorFlow 中内部索引对象的编号,shape 表示张量的形状,dtype 表示张量的数值精度
tensor常见且有用的属性
x.device返回当前tensor所在设备的名字

- tensor在设备上的转移

- tensor转numpy

- 返回维度

- 判断数据是否是tensor

- 判断数据类型

numpy转tensor
convert_to_tensor

cast

- 整形转布尔型

创建tensor
从Numpy、List创建
tf.convert_to_tensor()
tf.constant
这两个方法功能基本一样


创建全0或者全1张量
tf.zeros()

tf.ones()

tf.zeros_like()和tf.ones_like()创建一个和传入参数shape相同的全0\全1张量

创建全自定义数值张量
除了初始化为全0,或全1 的张量之外,有时也需要全部初始化为某个自定义数值的张量,比如将张量的数值全部初始化为−1等。
tf.fill,例:创建所有元素为-1 的向量

随机初始化
正态分布Normal Distribution
tf.random.normal
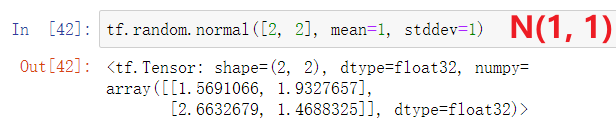
均值为mean,标准差为stddev,不设置这两个参数默认为0和1tf.random.truncated_normal截断的正态分布
这个初始化用来避免梯度弥散,效果可能会比tf.random.normal更好一点
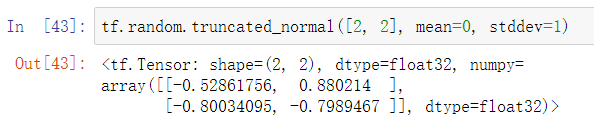
均匀分布Uniform Distribution
tf.random.uniform
创建采样自[minval, maxval)区间的均匀分布的张量。例如创建采样自区间[0,1),shape 为[2,2]的矩阵

如果需要均匀采样整形类型的数据,必须指定采样区间的最大值maxval 参数,同时指定数据类型为tf.int*型

创建一段连续的整型序列
tf.range()
tf.range(start, limit, delta=1)可以创建[0, limit)之间,步长为delta 的整型序列,不包含limit 本身,start为0时可省略。

张量的典型应用
标量 Scalar
标量最容易理解,它就是一个简单的数字,维度数为0,shape 为[]
- []
Loss损失值Accuracy准确度
向量 Vector
向量是一种非常常见的数据载体,如在全连接层和卷积神经网络层中(y=x@w+b),偏置张量𝒃就使用向量来表示。
矩阵 Matrix
矩阵也是非常常见的张量类型,比如全连接层的批量输入张量𝑿的形状为[𝑏, 𝑑 i n 𝑑_{in} din],其中𝑏表示输入样本的个数,即Batch Size; 𝑑 i n 𝑑_{in} din表示输入特征的长度。
三维张量
三维的张量一个典型应用是表示序列信号,它的格式是𝑿 = [𝑏, sequence len, feature len]:b个句子,sequence len每个句子单词数量,feature len单词编码长度。
四维张量
四维张量在卷积神经网络中应用非常广泛,它用于保存特征图(Feature maps)数据,格式一般定义为[𝑏, ℎ, w, 𝑐]:b张图片,h高,w宽,c通道数
多维张量
比较少见,但是每一个维度都有具体含义。
索引与切片
索引
- 标准索引
a = tf.ones([1, 5, 5, 3])
a[0][0]
a[0][0][0]
a[0][0][0][2] => 1.0
- numpy索引风格
a = tf.random。normal([4, 28, 28, 3]) # 4张28*28的彩色图片
a[1].shape => TensorShape([28, 28, 3])
a[1, 2].shape => TensorShape([28, 3])
a[1, 2, 3].shape => TensorShape([3])
a[1, 2, 3, 2].shape => TensorShape([])
索引编号从0端开始就是正常的0,1,2…,从末端开始的话就是-1,-2,-3…,最后一个是 -1
切片
通过start : end : step切片方式可以方便地提取一段数据。比如[A:B),截取从A到B(不包含B)的一段,A省略时默认为0,B省略时默认为-1,step省略默认为1。

省略A和B,只有 : 表示全选
假设a.shape = [4, 28, 28, 3]

a[0].shape = a[0, :, :, :].shape
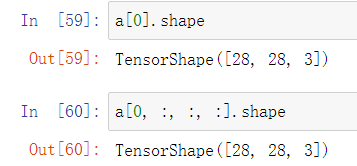
a[:, :, :, 0].shape = a[:, :, :, 2].shape

其他同理
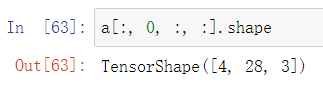
step

倒序
a = tf.range(10)
tf.Tensor([0 1 2 3 4 5 6 7 8 9], shape=(10,), dtype=int32)
- A:B:-1
a[::-1]
<tf.Tensor: shape=(10,), dtype=int32, numpy=array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])>
a[2::-1]
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 1, 0])>
- A:B:-2
# 倒序,隔着采
a[::-2]
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([9, 7, 5, 3, 1])>

三个点 …
使用⋯符号表示取多个维度上所有的数据,其中维度的数量需根据规则自动推断:当切片方式出现⋯符号时,⋯符号左边的维度将自动对齐到最左边,⋯符号右边的维度将自动对齐到最右边,此时系统再自动推断⋯符号代表的维度数量。

选择性索引
设一个tensor为:a = [4, 35, 8],具体含义是:4个班级,每个班级35个学生, 8门学科
tf.gather
# data 数据源
# axis 要取哪个维度
# indices 具体的索引号,自定义
tf.gather(data, axis=0, indices=[start, end])
- 取2,3班的信息
tf.gather(a, axis=0, indices=[2, 3])
# 数据源为a
# 第一个维度,班级
# 2班,3班
TensorShape([2, 35, 8])
- 不按顺序取
原来是1,2,3,4班的顺序,现在我要变成3,2,4,1班的顺序
tf.gather(a, axis=0, indices=[2, 1, 3, 0]).shape
TensorShape([4, 35, 8])
# 虽然输出的shape和原来一样,但是里面的内容顺序已经变了
- 取每个班级的某5个学生
tf.gather(a, axis=1, indices=[2, 3, 7, 9, 16]).shape
# 维度变成1,班级
# 索引为第2个学生,第3个学生。。。
TensorShape([4, 5, 8])
# 输出为4个班级,5个学生,8门课
- 取其中三门课的所有人的成绩
tf.gather(a, axis=2, indices=[2, 3, 7]).shape
# 维度变成1,班级
# 索引为第2门课,第3门课,第7门课
TensorShape([4, 35, 3])
# 输出为4个班级,35个学生,3门课
tf.gather_nd
现在进行抽样:第一个班级的第一个学生,第二个班级的第二个学生,第三个班级的第三个学生,第四个班级的第四个学生,得到的输出将会是[4, 8],四个学生8门课。

对于上面的例子:
tf.gather_nd(a, [[0, 0], [1, 1], [2, 2], [3, 3]]).shape
# 先分别取a[0, 0], a[1, 1], a[2, 2], a[3, 3]
# 然后再用一个[]组合起来,就变成了[4, 8]
tf.boolean_mask
略
维度变换
改变视图
tf.reshape(data, new_shape)
举个例子:[4, 28, 28, 3],4张28*28的彩色图片,对他进行不同的理解:
a.shape = [4, 28, 28, 3]
4张图片,高28,宽28,3个通道tf.reshape(a, [4, 784, 3]).shape或者tf.reshape(a, [4, -1, 3]).shape
4张图片,784个像素(28*28=784),3个通道
对于-1来说,系统会根据原来的维度,自动计算出-1。只能有一个-1
其他例子


交换维度
交换维度操作是非常常见的,比如在TensorFlow 中,图片张量的默认存储格式是通道后行格式:[𝑏, ℎ, w, 𝑐],但是部分库的图片格式是通道先行格式:[𝑏, 𝑐, ℎ, w],因此需要完成[𝑏, ℎ, w, 𝑐]到[𝑏, 𝑐, ℎ, w]维度交换运算,此时若简单的使用改变视图函数reshape,则新视图的存储方式需要改变,因此使用改变视图函数是不合法的。我们以[𝑏, ℎ, w, 𝑐]转换到[𝑏, 𝑐, ℎ, w]为例,介绍如何使用tf.transpose(x, perm)函数完成维度交换操作,其中参数perm表示新维度的顺序List
考虑图片张量shape 为[2, 32, 32, 3],“图片数量、行、列、通道数”的维度索引分别为0、1、2、3,如果需要交换为[𝑏, 𝑐, ℎ, w]格式,则新维度的排序为“图片数量、通道数、行、列”,对应的索引号为[0, 3, 1, 2],因此参数perm 需设置为[0,3,1,2]
x = tf.random.normal([2,32,32,3])
tf.transpose(x,perm=[0,3,1,2]) # 交换维度
<tf.Tensor: id=603, shape=(2, 3, 32, 32), dtype=float32, numpy=...>
如果希望将[𝑏, ℎ, w, 𝑐]交换为[𝑏, w, ℎ, 𝑐],即将高、宽维度互换,则新维度索引为[0,2,1,3],
tf.transpose(x,perm=[0,2,1,3]) # 交换维度
<tf.Tensor: id=612, shape=(2, 32, 32, 3), dtype=float32, numpy=...>
需要注意的是,通过tf.transpose 完成维度交换后,张量的存储顺序已经改变,视图也随之改变,后续的所有操作必须基于新的存续顺序和视图进行。相对于改变视图操作,维度交换操作的计算代价更高。
增加维度
通过tf.expand_dims(x, axis)可在指定的axis 轴前(axis为正,如果为负则在后面)插入一个新的维度
减少维度
通过tf.squeeze(x, axis)函数,axis 参数为待删除的维度的索引号,例如,图片数量的维度轴axis=0
Broadcasting
由python自动完成

数学运算
加减乘除
+-*/%//整除
矩阵相乘
@
a@b
matmul
matmul(a, b)
某一维度运算
- reduce_mean
- reduce_max
- reduce_min
- reduce_sun
乘方
tf.pow(x, a)可以方便地完成𝑦 = x 𝑎 x^𝑎 xa的乘方运算- 平方
tf.square(x), x 2 x^2 x2
开方
tf.sqrt(x) 平方根
x
\sqrt[]{x}
x
自然指数
e
x
e^x
ex ==> tf.exp(x)
对数
- 自然对数
l o g e x log_ex logex ==>tf.math.log(x) - 其他对数
如果希望计算其它底数的对数,可以根据对数的换底公式:
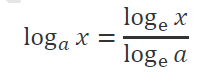
例子:
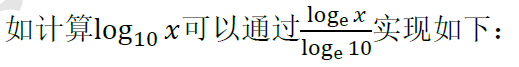
tf.math.log(x)/tf.math.log(10.) # 换底公式















 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









