









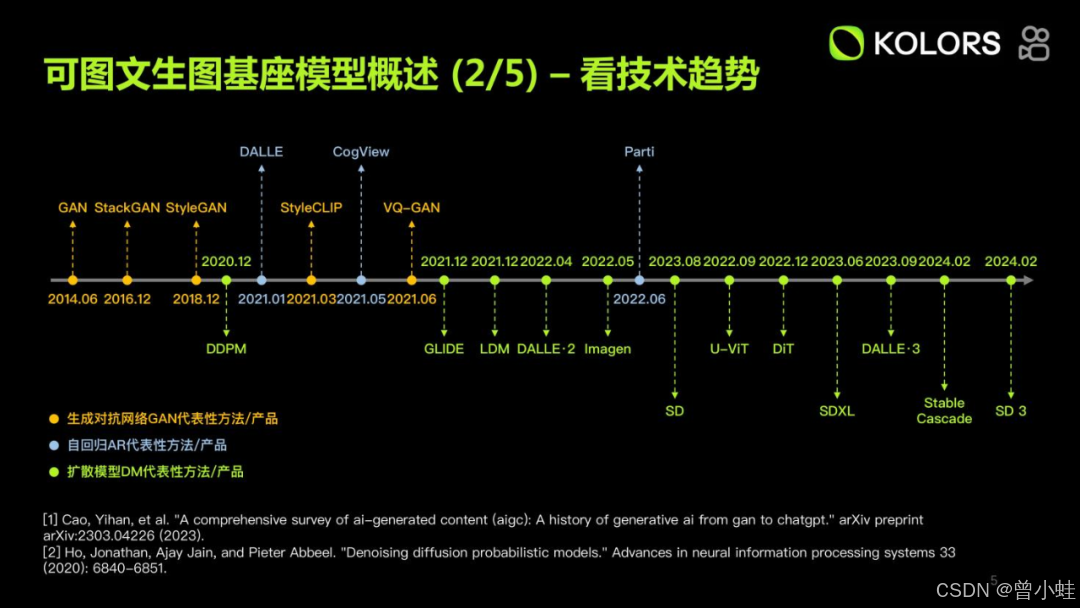
曾小蛙-CSDN博客 整理发布 : https://blog.csdn.net/imwaters/article/details/144969523
10年图像生成的发展脉络
- 2013.12 VAE: Auto-Encoding Variational Bayes
- 2014.06 GAN: Generative Adversarial Networks (生成对抗网络--上一代图像生成架构)
- 2017.06 Transformer : Attention Is All You Need
- 2017.11 VQ-VAE : Neural Discrete Representation Learning
- 2018.12 StyleGAN: (系列模型,GANs时代高峰,开启高清人像生成)A Style-Based Generator Architecture for Generative Adversarial NetworksGitHub - NVlabs/stylegan: StyleGAN - Official TensorFlow Implementation
- 2020.06 DDPM: Denoising Diffusion Probabilistic Models
- 2020.10 DDIM: Denoising Diffusion Implicit Models
- 2021.02 (自回归)DALLE: Zero-Shot Text-to-Image Generation
- 2021.03 CLIP: Learning Transferable Visual Models From Natural Language Supervision
- 2021.05 Diffusion Models Beat GANs on Image Synthesis guided-diffusion: Diffusion Models Beat GANs on Image Synthesishttps://github.com/openai/guided-diffusion
- 2021.05 (自回归) CogView:Mastering Text-to-Image Generation via Transformershttps://github.com/THUDM/CogView (可中文题词)
- 2021.08 SDEdit: (使用随机微分方程引导图像合成和编辑) Image Synthesis and Editing with Stochastic Differential Equations
- 2021.12.GLIDE: openai开发的模型Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
- 2021.12 LDMs High-Resolution Image Synthesis with Latent Diffusion Models GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
- 2022.04 DALLE-2: Hierarchical Text-Conditional Image Generation with CLIP Latents
- 2022.04 CogView2 : (对标DALLE-2)论文:Faster and Better Text-to-Image Generation via Hierarchical Transformers https://github.com/THUDM/CogView2
- 2022.05 Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
- 2022.07 CFG: Classifier-Free Diffusion Guidance
-
2022.08 Stable Diffusion 开源 : 论文是LDMs:GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
- 2022.10 Flow mactch: Flow Matching for Generative Modeling (SD3部分理论来源)
- 2022.11 SD2 https://huggingface.co/stabilityai/stable-diffusion-2
- 2022.12 DIT: Scalable Diffusion Models with Transformers (DiT)https://github.com/facebookresearch/DiT (SORA的基础架构)
- 2023.02 ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models GitHub - lllyasviel/ControlNet: Let us control diffusion models!
- 2023.07 SDXL: Improving Latent Diffuon Models for High-Resolution Image Synthesishttps://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
- 2023.09 DALLE-3: Improving Image Generation with Better Captions
- 2023.10 LCM: Latent Consistency Models Latent Consistency Models: Synthesizing High-Resolution Images with Few-step Inference
- 2023.11 AnyText (中文图片生成) Multilingual Visual Text Generation And Editing GitHub - tyxsspa/AnyText: Official implementation code of the paper <AnyText: Multilingual Visual Text Generation And Editing>
- 2023.12 Imagen2 未开源无论文 Imagen 2 - Google DeepMind
- 2024.03 CogView3 Finer and Faster Text-to-Image Generation via Relay Diffusion
- 2024.03 SD3: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
- 2024.04 Hyper-SD: (少步数采样的sota) Trajectory Segmented Consistency Model for Efficient Image Synthesis
- 2024.04 VAR: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale https://github.com/FoundationVision/VAR
- 2024.05 腾讯HunyuanDiT: A Powerful Multi-ResolutionDiffusionTransformer with Fine-Grained ChineseUnderstanding
- 2024.07 快手Kolors : (可中文题词)Effective Training of Diffusion Model forPhotorealistic Text-to-Image Synthesis
- 2024.08 Flux.1 : 论文是SD3, 最强开源文生图模型GitHub - black-forest-labs/flux: Official inference repo for FLUX.1 models
主要参考
万字长文分享快手 Kolors 可图大模型应用实践_kolors模型-CSDN博客
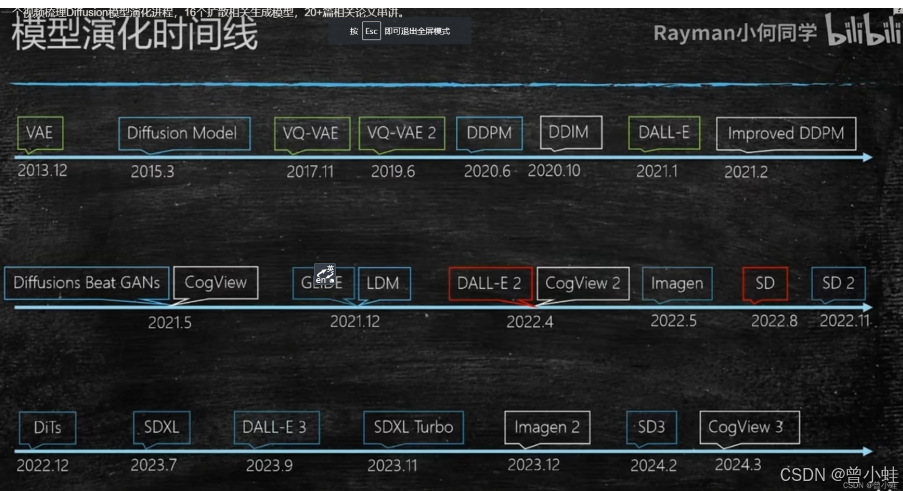
小何同学梳理的发展脉络
【扩散生成模型串讲】一个视频梳理Diffusion模型演化进程,16个扩散相关生成模型,20+篇相关论文串讲。_哔哩哔哩_bilibili



















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











