




开源发布时间:2024年06月
论文:2406。
【LeRobot】中文字幕|OpenVLA: LeRobot Research Presentation 5 by Moo Jin Kim
一、简介

OpenVLA 是一个开源的视觉–语言–动作模型,拥有 70亿参数(7B) ,通过在 97 万机器人示范片段(episodes)上微调(数据来源 Open X-Embodiment),为通才(generalist)机器人操作策略 (manipulation policies) 设置了新的技术水平。它支持离线控制多个机器人,并通过参数高效的微调快速适应新的机器人领域(new robot domains),达到了优于闭源大模型(如 55B 参数的 RT-2-X)16.5 个百分点的任务成功率,同时大大降低了模型规模和资源消耗。
基础理论
- 预训练视觉–语言模型:OpenVLA 的核心依托于大规模预训练的视觉与语言模型。视觉编码器融合了 DinoV2 和 SigLIP 两种预训练模型的特征,既保留了低级空间信息,又获得了高级语义信息;而语言模型部分则使用 Llama 2 7B 模型,利用其丰富的互联网先验知识。
- 动作离散化与令牌化:为了使语言模型能直接生成机器人动作,OpenVLA 将连续的机器人控制指令离散化为 256 个区间,并修改了 Llama 的词汇表,使其支持这些动作令牌。整个训练过程基于下一个令牌预测目标,即让模型学会从视觉和语言输入中预测对应的动作序列。
如何运用
- 输入与输出:使用时,用户为机器人提供一幅图像(视觉观察)和一个自然语言指令,模型将二者结合,通过生成一系列动作令牌来输出对应的机器人控制动作。
- 微调适应:在实际应用中,可以利用预训练好的 OpenVLA 模型作为初始模型,通过少量数据的微调(甚至仅需 10–150 个示范)快速适配新的任务和机器人平台。
- 高效部署:结合低秩自适应(LoRA)和量化技术(如 4 位量化),OpenVLA 可以在消费级 GPU 上进行高效微调与推理,实现资源节省和实时控制。
二、模型细节
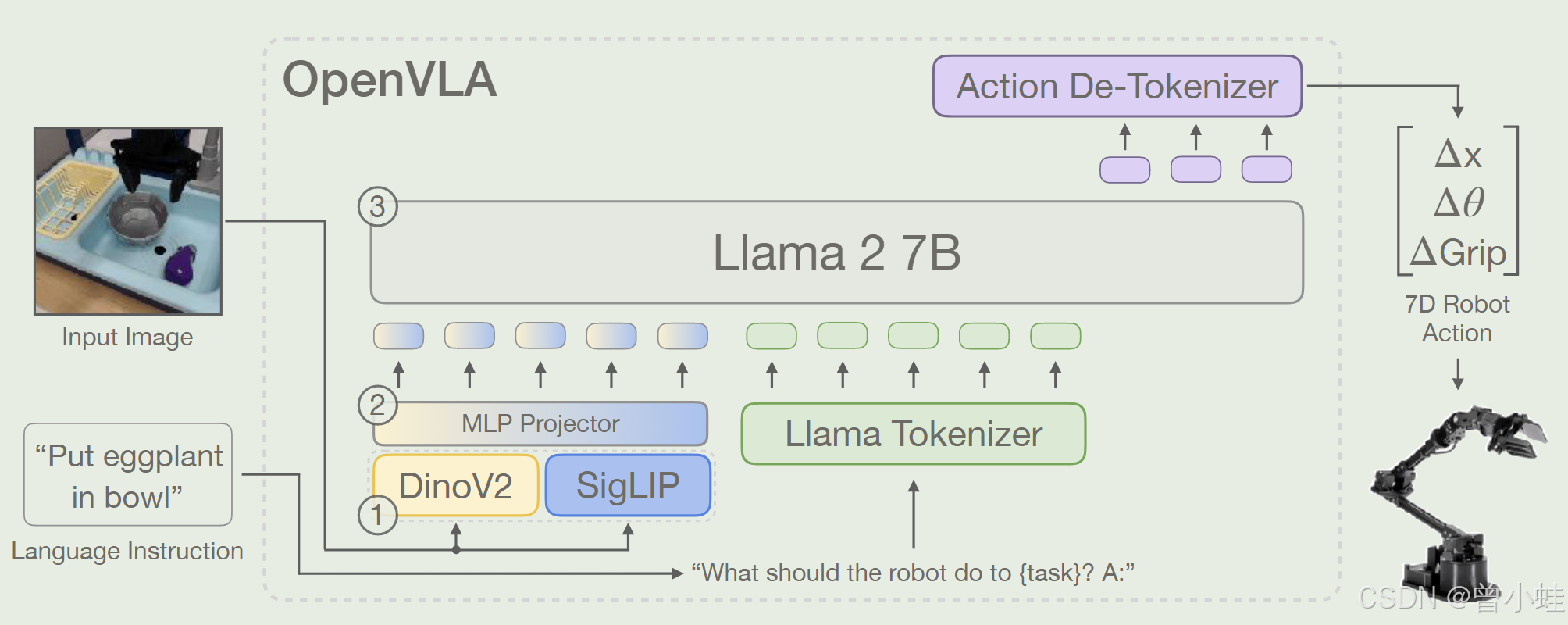
给定一个图像观察和语言指令,模型预测 7 维机器人控制动作。架构由三个关键组件组成:(1)连接 Dino V2 [25] 和 SigLIP[79] 特征的视觉编码器,(2)将视觉特征映射到语言嵌入空间的投影器,以及 (3) LLM 主干,Llama 2 7B 参数大型语言模型
OpenVLA 的目标是:给定机器人当前观察到的图像(或图像序列)和自然语言指令,模型能够预测机器人下一步应该执行的动作序列(离散化动作 token),从而在真实环境中进行闭环控制。
-
输入(Input)
- 视觉部分:一张或多张 RGB 图像,通常分辨率固定(如 224×224),送入预训练视觉编码器(DINOv2 + SigLIP)提取视觉特征。
- 语言部分:自然语言指令(如“Wipe the table”),通过 Llama2 语言模型的 tokenizer 转为文本 token。
- 动作部分:训练时,使用人类示范或离线收集的机器人轨迹,其中每一步的动作(如 7 维机械臂动作 Δx (位置偏移),Δθ (姿态/角度偏移)ΔGrip (夹爪动作偏移)) ) 被离散化为 256 个可能值之一,并映射成动作 token。
-
模型结构
- 视觉编码器:DINOv2 + SigLIP,用于从图像中提取多分辨率或多粒度视觉特征,输出一串“视觉 token”或向量序列。
- 投影层(Projector):将视觉特征映射到语言模型可识别的嵌入空间。
- 语言模型骨干(LLM):使用 Llama2 7B 模型,把视觉 token、文本 token、(以及潜在的历史动作 token)拼接后,通过多层 Transformer 编码,最终预测下一个动作 token 序列。
-
动作离散化与令牌化
- 将连续的动作维度(例如 7 维末端执行器指令)离散化为 256 个区间(bin)。
- 在训练时,需将这 256 个 bin 对应到语言模型词表(vocabulary)中的若干“空闲 token”,或直接“覆盖”低频词条,从而让 LLM 能把动作预测当作“生成 token”的过程。
-
训练流程
- 使用标准的自回归“下一个 token 预测”目标(next-token prediction)。
- 只计算动作 token 的交叉熵损失(语言指令 token 通常是上下文输入,不计算损失;或可在多任务场景下计算额外的语言损失)。
- 多次遍历(epoch)大规模机器人示范数据,提升动作预测准确率。
-
推理流程
- 给定新的图像与自然语言指令,模型通过视觉编码器和语言模型生成一串动作 token,解码为具体的机器人控制指令(Δx,Δθ,ΔGrip\Delta x, \Delta \theta, \Delta \text{Grip}Δx,Δθ,ΔGrip 等),并在真实机器人上执行。
- 可以循环执行:每执行一步动作后获取新图像,再次送入模型,直到完成任务。



















 6100
6100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











