






Abstract
这篇论文总结了现有数据增强的方法(include geometric transformations, color space augmentations, kernel filters,mixing images, random erasing, feature space augmentation, adversarial training,generative adversarial networks, neural style transfer, and meta-learning),光明的发展前景,以及实施数据增强的元决策(如何定数据集大小等)。
Introduction
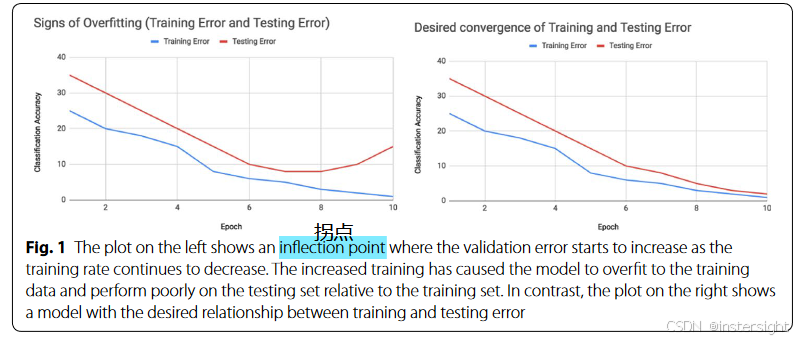
图1为过拟合现象:在训练过程中,我们用validation set评估模型性能,在训练后期随着周期的增加模型性能可能会出现下降,这是因为模型学习到了训练集中的特定特征,而这些特征在实际运用/测试集中是没有的。
因此,我们可以对数据集进行增强,使得训练数据更具有综合性和泛用性。但是减少过拟合现象的方法不止数据增强这一种,作者详细列举的常用方法,以便给读者一个更全面的认知:
1.Dropout
Dropout是一种用于深度学习模型的正则化技术,旨在防止过拟合。在每一个批次中,Dropout会随机选择一部分神经元,将它们的输出设为零,从而“丢弃”这些神经元。这意味着在每次迭代中,模型实际上在使用不同的子网络进行训练。通过强制模型学习多个特征组合,降低了对特定神经元的依赖(可以理解为网络就是在学习特征表示,每一个神经元代表特定特征)。
spatial dropout:通常是在卷积层之后,随机将特征图的某一些区域置零,以将与这些区域有关联的神经元丢弃。
2.Batch normalization
在不同批次的同一特征做归一化处理(减去均值除标准差)。
3.Transfer Learning
指的是使用已有模型的一部分来解决新问题
4.Pretraining
在大量数据上训练基础模型,使其能很快适应下游任务
5.One shot、Zero shot
还有早停等原文没有提到的方法。
数据增强常用技术介绍
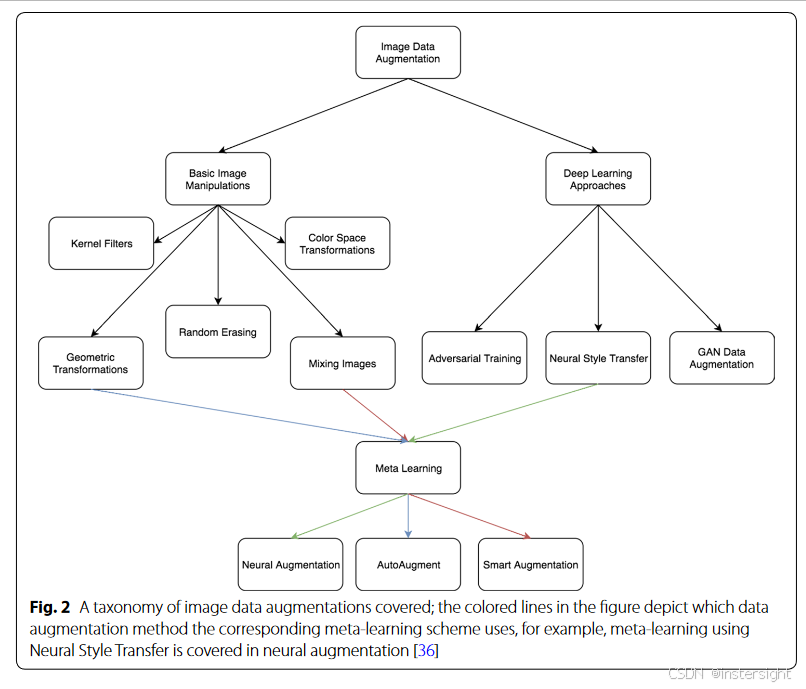
geometric transformations
flipping
rotation
cropping
color space augmentations
常用的方法
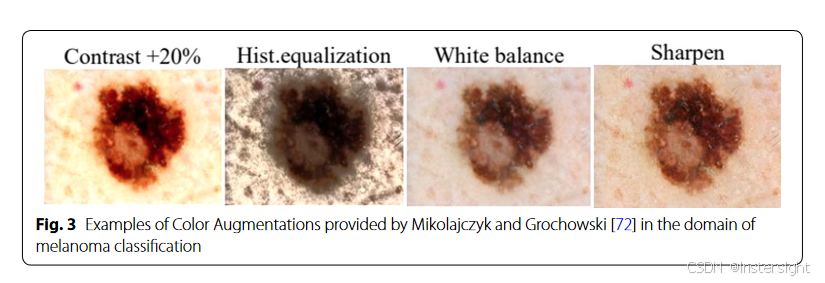
color jittering

fancy pca
kernel filters
Kernel filters 是图像处理中常用的技术,用于锐化和模糊图像。这些滤波器通过在图像上滑动一个 n×nn \times nn×n 的矩阵来工作,可以应用不同的滤波器,如高斯模糊滤波器(生成模糊图像)或高对比度的垂直或水平边缘滤波器(使图像沿边缘更锐利)。
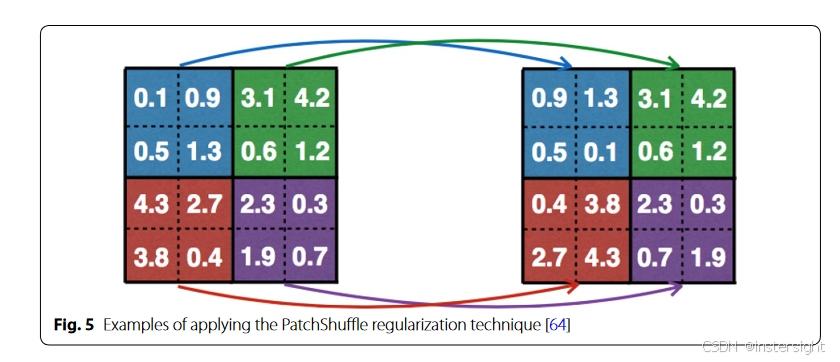
patchshuffle regularization
一种特殊的kernel filter,对输入图像划分区域,保持全局特征,重组局部特征。

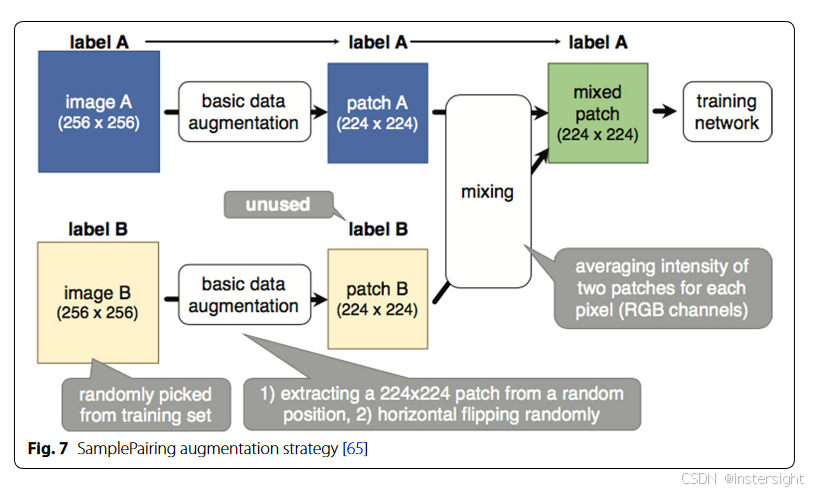
mixing images
将两张及以上图片进行混和得到新图片,下图为一般步骤。
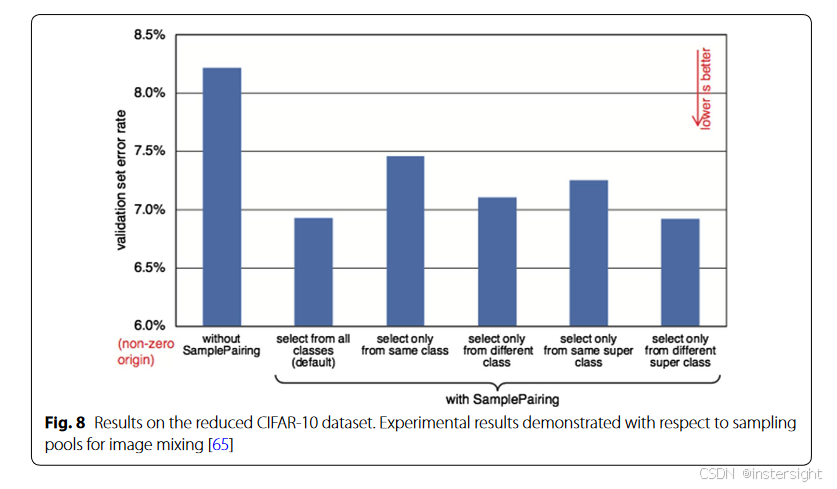
结果
random erasing

feature space augmentation
在图像分类任务中,可以使用自编码器将图像映射到低维特征空间,然后通过插值和外推生成新的样本。这些新样本可以用于训练模型,提高对未见类别的分类性能。
adversarial training
对抗训练是一种机器学习技术,通过引入对抗样本(即故意设计来误导模型的输入)来增强模型的鲁棒性。在对抗训练中,模型不仅学习正常样本,还会与生成对抗样本的网络进行训练。这样,模型在训练过程中会学习识别和抵御这些攻击,从而提高对真实世界中潜在攻击的抵抗力。该方法有效提升了深度学习模型的安全性和泛化能力。
generative adversarial networks
这是一种深度学习架构,由两个神经网络(生成器和判别器)组成。生成器试图生成逼真的数据(如图像),而判别器则试图区分真实数据和生成的数据。通过对抗训练,两者相互提升,最终生成器能够生成非常逼真的数
neural style transfer
使用风格迁移的神经网络获得更多样本

meta-learning
元学习使得模型能够在少量样本上快速适应新任务,通过学习多个任务的经验来提高对新任务的泛化能力。

















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









