







0. 前言
- 相关资料:
- pdf下载
- github
- 论文解读
- 论文基本信息
- 领域:行为识别
- 作者单位:加拿大华为诺亚实验室
- 发表时间:ECCV 2020
1. 要解决什么问题
- 现在的行为识别模型很多,也尽可能做小。但是,当前最优代表性的小模型TSM也需要较多算力。
- 用了一个我没看懂的方法算了一下,在手机上运行TSM的小模型大概能够连续运行15分钟。
2. 用了什么方法
- 其实就是将 Coarse-to-Fine(C2F) 的思想引入行为识别中。
- 人本身的视觉系统就是 Coarse-to-Fine,中文翻译就是“由粗到细”。
- 我的理解就是,我们看一个物体的时候,会在时间、空间多个维度上进行调整。
- 比如,“抬起头看电视”这个动作,抬起头眼睛先会找电视在哪个位置,然后再看电视屏幕中的内容。
- C2F的好处在于,处理数据时不用每次都使用高分辨率的数据。
- 比如,“检查电视是否关了”这个动作,我们用余光就能知道,不用仔细盯着电视屏幕看。
- 也就是说,对于不同的行为,不需要使用相同分辨率的输入数据就能完成任务。
- 其实,对于同一类行为的不同样本,也不一定需要使用相同的分辨率,毕竟距离摄像头的距离不一样。
- C2F结构如下图
- 感觉本质就是模型融合(model ensamble)
- 输入的RGB图像在时间维度和空间纬度都会进行下采样。
- C2F可以看成是模型集成的一种方式,在Coarse模型不顶用的情况下才会启用Finer的模型。下图中就包含三个模型,C(Coarse)/M(Finer)/F(Finest)。
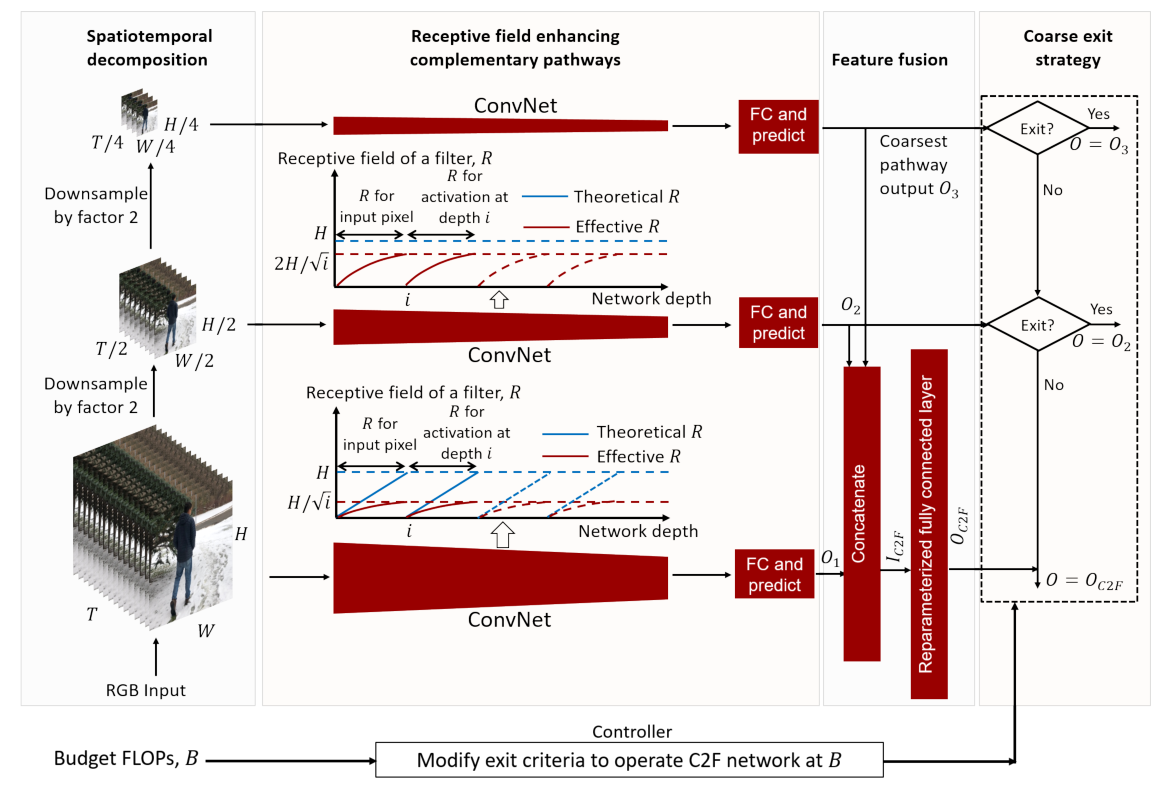

- Enhanced receptive fields via spatiotemporal decomposition
- 说的很玄乎(4行英文没有一个逗号和句号,你敢信?想到了英文阅读理解中的长句处理…),我没完全明白,下文可能有问题。
- 所谓 spatiotemporal decomposition 指的就是输入图像在时空纬度上的下采样。
- 所谓 enhanced recptive fields 指的就是基于不同输入的不同分支得到的感受野在变化。
- 最终实现方式就是,Coarser的分支感受野小,finer的分支感受野大。
- 文中提到,在行为识别中,为了提高性能,最好不要用中心切片,而要使用整张图片。
- 根据上面这个结论,可以得出,增强卷积核的感受野会对行为识别起到正面的作用。
- Feature fusion,其实就是不同分支的结果如何融合。
- 每个分支经过fc后(softmax前)得到一个特征。
- 特征融合方式就是将不同分支的特征进行拼接concat。
- 之后的FC使用的是 reparameterized FC,没看明白,也没细看。
- Coarse exit strategy,即coarser的分支在什么情况下可以输出,不用再使用finer分支。
- 这一步非常重要,我们需要根据当前的算力,选择不同的策略,希望能用一个参数来实现上面这个功能。
- 基本方法就是设置阈值,当最大概率大于某个阈值时就不再使用finer的分支。
- 提出了一些方法来选择阈值,还有一些方法来设置当前概率。
- 视频的两种采样方法
- dense sampling:取连续帧
- strided sampling:将视频分为若干段,每一段取帧
3. 效果如何
- 使用C2F之后,参数增加(模型变大),但FLOPs减少,性能些许提高。
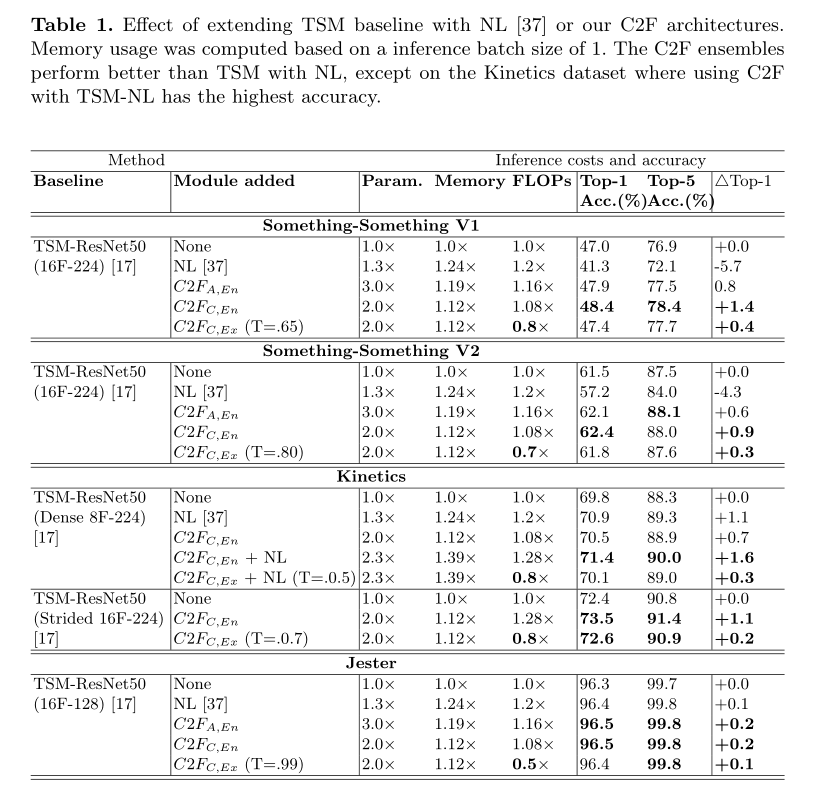
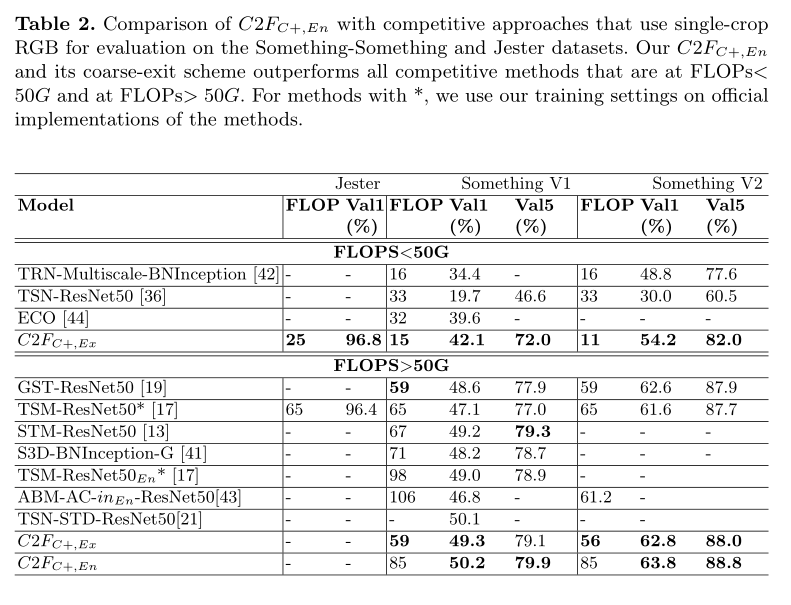
4. 还存在什么问题&有什么可以借鉴
-
这个思路非常好,感觉用在实时系统中也实用。
-
想到了FAIR的multi-grid训练,也是coarse-to-fine的思想。















 3539
3539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









