







0. 前言
1. 要解决什么问题
- DETR存在一些问题:
- 收敛速度慢(需要训练更多的epochs)
- Transformer处理图像数据时,feature spatial resolution受限。
- Faster RCNN中,处理小目标问题一般是使用FPN。但在DETR中,使用FPN并不现实。因为会导致计算量大幅度增加。
- 而DETR中存在的问题,都可以归结为,在使用Transformer处理图像特征时,会处理所有可能的空间位置。
- 可能意思是,处理的位置太多了,没有抓住重点?
- 原文如下
The core issue of applying Transformer attention on image feature maps is that it would look over all possible spatial locations.
2. 用了什么方法
- 感觉就是吧Deformable的结构用在各种位置
- 可形变卷积的主要作用在于,可更高效地处理稀疏空间中的信息。
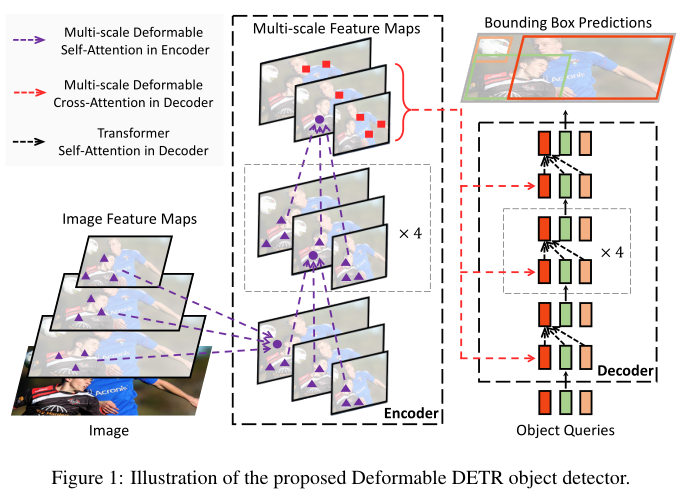
- deformable attention module
- multi-scale deformable attention module
- deformable transformer encoder
- deformable transformer decoder
- 上图中看到,模型的输入是 input multi-scale feature maps,那这个是如何构建的呢?
- 其他优化(附录中有一些介绍)
- Iterative Bounding Box Refinement,出自《Raft: Recurrent all-pairs field transforms for optical flow》,没看过细节。大概意思就是,用之前layer来优化当前decoder的bbox预测结果。
- Two-Stage Deformable DETR:原始DETR中decoder的object queries与当前图片无关,而本文则使用了two-stage的方法,第一个stage就是用来生成proposals作为decoder的object queries。
- 我有点疑问,用了这个,不就感觉DETR失去了一些原有的东西(比如去掉了anchor),感觉没有DETR惊艳。
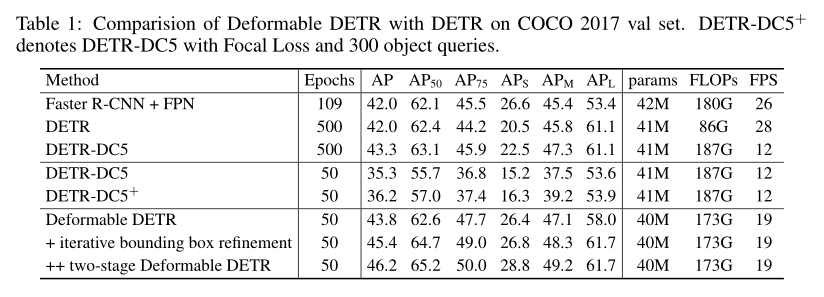
3. 效果如何
- 结果可以说非常好了,训练时间减少,性能又高
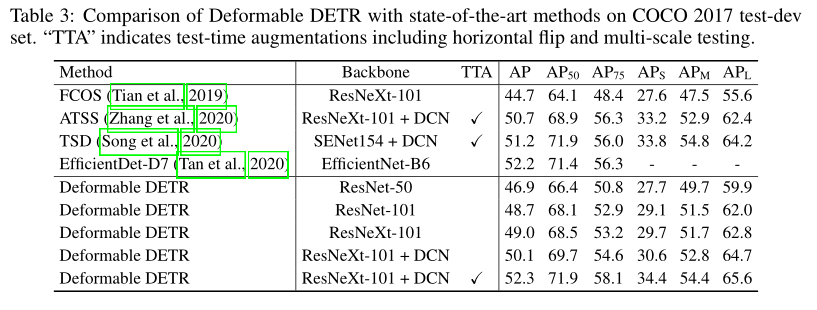
4. 还存在什么问题&可借鉴之处
- 本质都是在Transformer与DETR上进行一些改进,最主要的还是要研究好DETR的源码。之后要阅读下,然后再细看本文。














 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









